






目录
实例一:线性回归波士顿房价
'''
实例一:线性回归波士顿房价【回归问题】
'''
# 导入数据集(波士顿房价--小型数据集)
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression # 线性回归
import matplotlib.pyplot as plt
# 加载数据
X, y = load_boston(return_X_y=True)
# print(X)
# print(X.shape)
# 对数据集进行处理,只展示房间数
X1 = X[:,5:6]
# print(X1)
# print(X1.shape)
# 切分数据集
train_x, test_x, train_y, test_y = train_test_split(X1, y, test_size=0.3, random_state=2)
# 创建线性回归对象
lr = LinearRegression()
# 训练模型
lr.fit(train_x, train_y)
# 预测得到结果
result = lr.predict(test_x)
# 展示数据
plt.scatter(train_x, train_y, color='blue')
# 划线
# plt.plot(test_x, test_y, color='red')
plt.plot(test_x, result, color='red')
plt.show()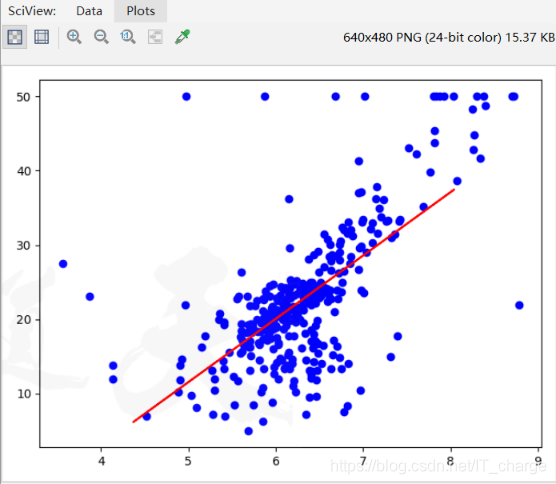
实例二:KNN实现电影分类
'''
实例二:KNN实现电影分类【分类问题】
'''
import numpy as np
import pandas as pd
# 训练数据
train_data = {'宝贝当家':[45,2,9,'喜剧片'],
'美人鱼':[21,17,5,'喜剧片'],
'澳门风云3':[54,9,11,'喜剧片'],
'功夫熊猫3':[39,0,31,'喜剧片'],
'谍影重重':[5,2,57,'动作片'],
'叶问3':[3,2,65,'动作片'],
'我的特工爷爷':[6,4,21,'动作片'],
'奔爱':[7,46,4,'爱情片'],
'夜孔雀':[9,39,8,'爱情片'],
'代理情人':[9,38,2,'爱情片'],
'新步步惊心':[8,34,17,'爱情片'],
'伦敦陷落':[2,3,55,'动作片']
}
# 将训练数据封装为 DataFrame
train_df = pd.DataFrame(train_data).T
# 设置表格列名
train_df.columns = ['搞笑镜头','拥抱镜头','打斗镜头','电影类型']
# 设置测试数据
test_data = {'唐人街探案':[23,3,17]}
# 计算欧氏距离
def euclidean_distance(vec1,vec2):
return np.sqrt(np.sum(np.square(vec1 - vec2)))
# 设定 K 值
K = 3
movie = '唐人街探案'
# 计算出所有的欧式距离
d = []
for train_x in train_df.values[:,:-1]:
test_x = np.array(test_data[movie])
d.append(euclidean_distance(train_x,test_x))
dd = pd.DataFrame(train_df.values, index=d)
# 根据排序显示
dd1 = pd.DataFrame(dd.sort_index())
print(dd1.values[:K,-1:].max())
实例三:基于线性回归预测波士顿房价
'''
实例三:基于线性回归预测波士顿房价
'''
# 1. 数据加载和预处理
import pandas as pd
from sklearn.datasets import load_boston
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
# 获取波士顿房价数据集
boston = load_boston()
# 获取数据集特征(训练数据X)
X = boston.data
# 获取数据集标记(label数据y)
y = boston.target
# print(pd.DataFrame(X))
# 特征归一化到 [0,1] 范围内:提升模型收敛速度
X = MinMaxScaler().fit_transform(X)
# print(X)
# print(pd.DataFrame(X))
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2020)
# 2. 线性回归算法实现
import numpy as np
import matplotlib.pyplot as plt
class LinearRegression:
'''线性回归算法实现'''
def __init__(self, alpha=0.1, epoch=5000, fit_bias=True):
'''
alpha: 学习率,控制参数更新的幅度
epoch: 在整个训练集上训练迭代(参数更新)的次数
fit_bias: 是否训练偏置项参数
'''
self.alpha = alpha
self.epoch = epoch
# cost_record 记录每一次迭代的经验风险
self.cost_record = []
self.fit_bias = fit_bias
# 预测函数
def predict(self, X_test):
'''
X_test: m x n 的 numpy 二维数组
'''
# 模型有偏置项参数时:为每个测试样本增加特征 x_0 = 1
if self.fit_bias:
x_0 = np.ones(X_test.shape[0])
X_test = np.column_stack((x_0, X_test))
# 根据公式返回结果
return np.dot(X_test, self.w)
# 模型训练:使用梯度下降法更新参数(模型参数)
def fit(self, X_train, y_train):
'''
X_train: m x n 的 numpy 二维数组
y_train:有 m 个元素的 numpy 一维数组
'''
# 训练偏置项参数时:为每个训练样本增加特征 x_0 = 1
if self.fit_bias:
x_0 = np.ones(X_train.shape[0])
X_train = np.column_stack((x_0, X_train))
# 训练样本数量
m = X_train.shape[0]
# 样本特征维数
n = X_train.shape[1]
# 初始模型参数
self.w = np.ones(n)
# 模型参数迭代
for i in range(self.epoch):
# 计算训练样本预测值
y_pred = np.dot(X_train, self.w)
# 计算训练集经验风险
cost = np.dot(y_pred - y_train, y_pred - y_train) / (2 * m)
# 记录训练集经验风险
self.cost_record.append(cost)
# 参数更新
self.w -= self.alpha / m * np.dot(y_pred - y_train, X_train)
# 保存模型
self.save_model()
# 显示经验风险的收敛趋势图
def polt_cost(self):
plt.plot(np.arange(self.epoch), self.cost_record)
plt.xlabel("epoch")
plt.ylabel("cost")
plt.show()
# 保存模型参数
def save_model(self):
np.savetxt("model.txt", self.w)
# 加载模型参数
def load_model(self):
self.w = np.loadtxt("model.txt")
# 3. 模型的训练和预测
# 实例化一个对象
model = LinearRegression()
# 在训练集上训练
model.fit(X_train, y_train)
# 在测试集上预测
y_pred = model.predict(X_test)
# 4. ToDo:打印模型参数
print('偏置参数:', 'ToDo')
print('特征权重:', 'ToDo')
# 5. 打印测试集前5个样本的预测结果
print('预测结果:', y_pred[:5])
# # 评分
# print(model.score(X_test,y_test)) 实例四:sklearn完成逻辑回归鸢尾花分类
实例四:sklearn完成逻辑回归鸢尾花分类
'''
实例四:sklearn完成逻辑回归鸢尾花分类
'''
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=0)
from sklearn.preprocessing import StandardScaler
#正则化
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=1000.0, random_state=0)
lr.fit(X_train_std, y_train)
X_combined_std = np.vstack((X_train_std, X_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X_combined_std, y_combined, clf=lr, filler_feature_ranges=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('./figures/logistic_regression.png', dpi=300)
plt.show()

实例五:支持向量机完成逻辑回归鸢尾花分类
'''
实例五:支持向量机完成逻辑回归鸢尾花分类
'''
from sklearn import datasets
import numpy as np
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=0)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler().fit(X_train)
x_train_std = ss.transform(X_train)
x_test_std = ss.transform(X_test)
#正则化
svc = SVC(kernel='rbf', random_state=0, gamma=0.2, C=1.0)
svc.fit(x_train_std,y_train)
X_combined_std = np.vstack((x_train_std, x_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X_combined_std, y_combined, clf=svc, filler_feature_ranges=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('./figures/support_vector_machine_rbf_iris_1.png', dpi=300)
plt.show()
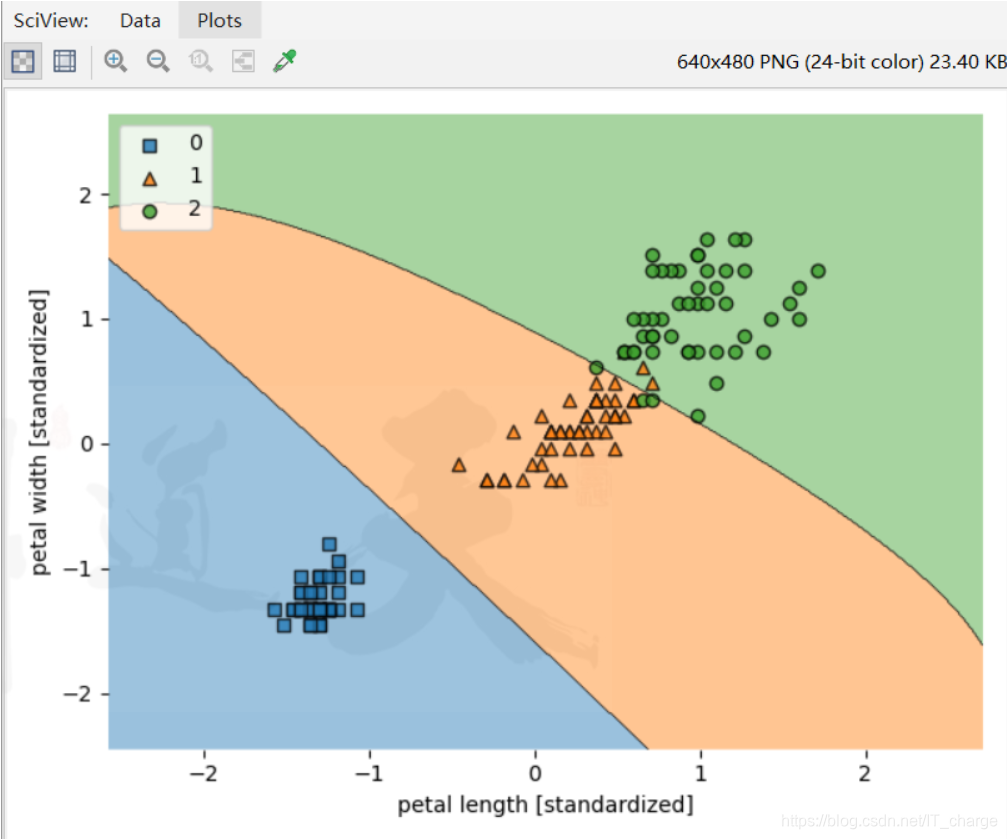
实例六:使用决策树实现鸢尾花分类
'''
实例六:使用决策树实现鸢尾花分类
'''
from sklearn import datasets
import numpy as np
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from mlxtend.plotting import plot_decision_regions
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=0)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler().fit(X_train)
x_train_std = ss.transform(X_train)
x_test_std = ss.transform(X_test)
# 正则化
dtc = DecisionTreeClassifier(criterion='entropy',random_state=0,max_depth=3)
dtc.fit(X_train,y_train)
X_combined_std = np.vstack((x_train_std, x_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X_combined_std, y_combined, clf=dtc, filler_feature_ranges=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('./figures/support_vector_machine_rbf_iris_1.png', dpi=300)
plt.show()
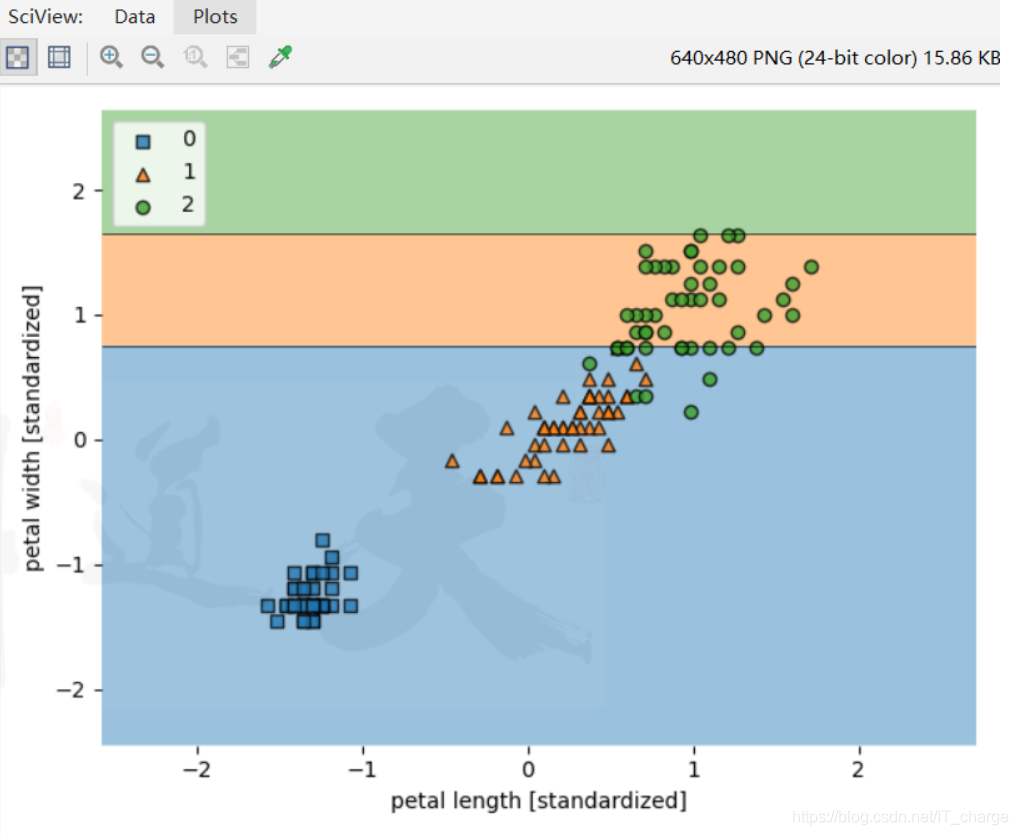
实例七:使用随机森林实现鸢尾花分类
'''
实例七:使用随机森林实现鸢尾花分类
'''
from sklearn import datasets
import numpy as np
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from mlxtend.plotting import plot_decision_regions
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=0)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler().fit(X_train)
x_train_std = ss.transform(X_train)
x_test_std = ss.transform(X_test)
# 正则化
rfc = RandomForestClassifier(criterion='entropy',n_estimators=10, random_state=1,n_jobs=2)
rfc.fit(X_train,y_train)
X_combined_std = np.vstack((x_train_std, x_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X_combined_std, y_combined, clf=rfc, filler_feature_ranges=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('./figures/support_vector_machine_rbf_iris_1.png', dpi=300)
plt.show()
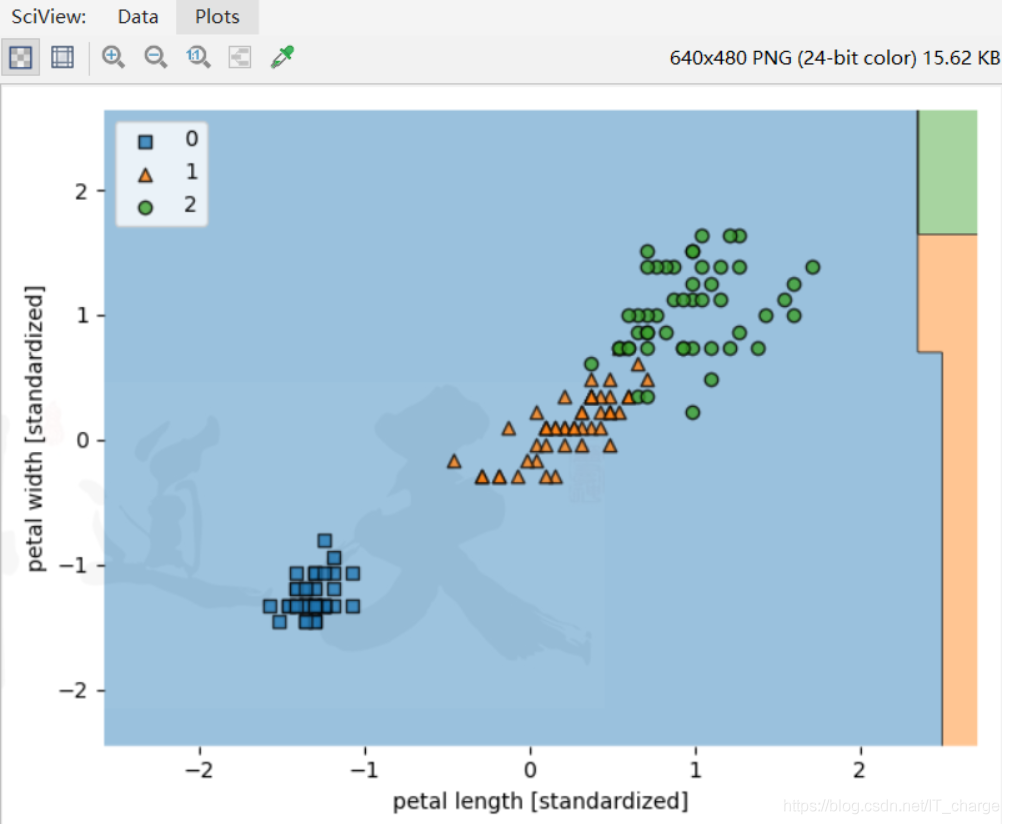
实例八:使用朴素贝叶斯进行鸢尾花分类
'''
实例八:使用朴素贝叶斯进行鸢尾花分类
'''
from sklearn import datasets
import numpy as np
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from mlxtend.plotting import plot_decision_regions
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=0)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler().fit(X_train)
x_train_std = ss.transform(X_train)
x_test_std = ss.transform(X_test)
# 正则化
gnb = GaussianNB()
gnb.fit(X_train,y_train)
X_combined_std = np.vstack((x_train_std, x_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X_combined_std, y_combined, clf=gnb, filler_feature_ranges=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('./figures/support_vector_machine_rbf_iris_1.png', dpi=300)
plt.show()
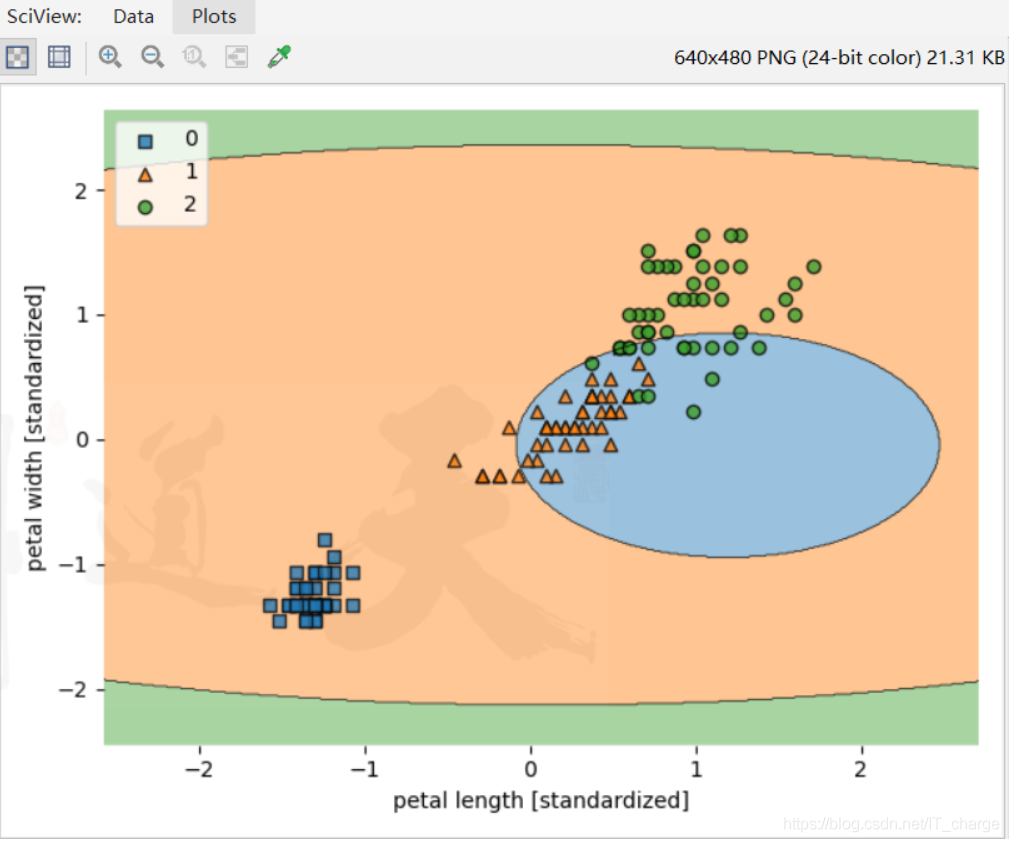
实例九:使用Kmeans来进行鸢尾花分类
'''
实例九:使用Kmeans来进行鸢尾花分类
'''
from sklearn import datasets
import numpy as np
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.cluster import KMeans
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from mlxtend.plotting import plot_decision_regions
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=0)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler().fit(X_train)
x_train_std = ss.transform(X_train)
x_test_std = ss.transform(X_test)
# 正则化
km = KMeans(n_clusters=3)
km.fit(X_train,y_train)
X_combined_std = np.vstack((x_train_std, x_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X_combined_std, y_combined, clf=km, filler_feature_ranges=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('./figures/support_vector_machine_rbf_iris_1.png', dpi=300)
plt.show()
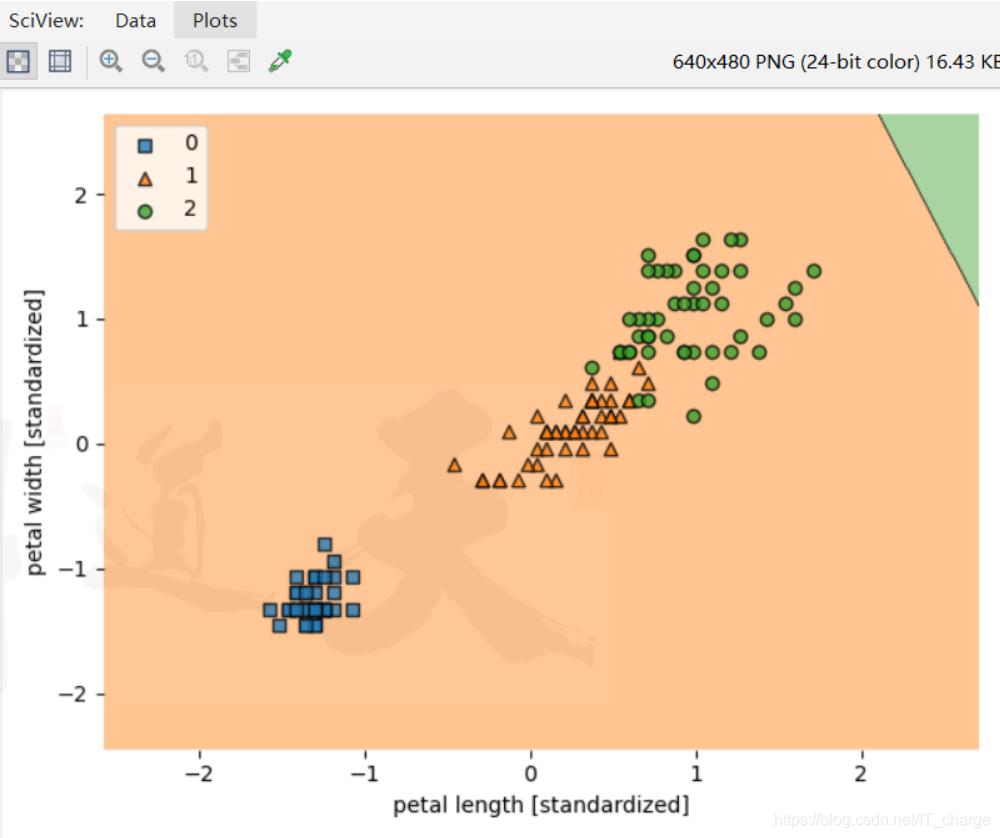
实例十:K最近邻的使用方式
'''
实例十:K最近邻的使用方式
'''
from sklearn import datasets
import numpy as np
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from mlxtend.plotting import plot_decision_regions
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=0)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler().fit(X_train)
x_train_std = ss.transform(X_train)
x_test_std = ss.transform(X_test)
# 正则化
knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski')
knn.fit(x_train_std, y_train)
X_combined_std = np.vstack((x_train_std, x_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X_combined_std, y_combined, clf=knn, filler_feature_ranges=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
# plt.savefig('./figures/support_vector_machine_rbf_iris_1.png', dpi=300)
plt.show()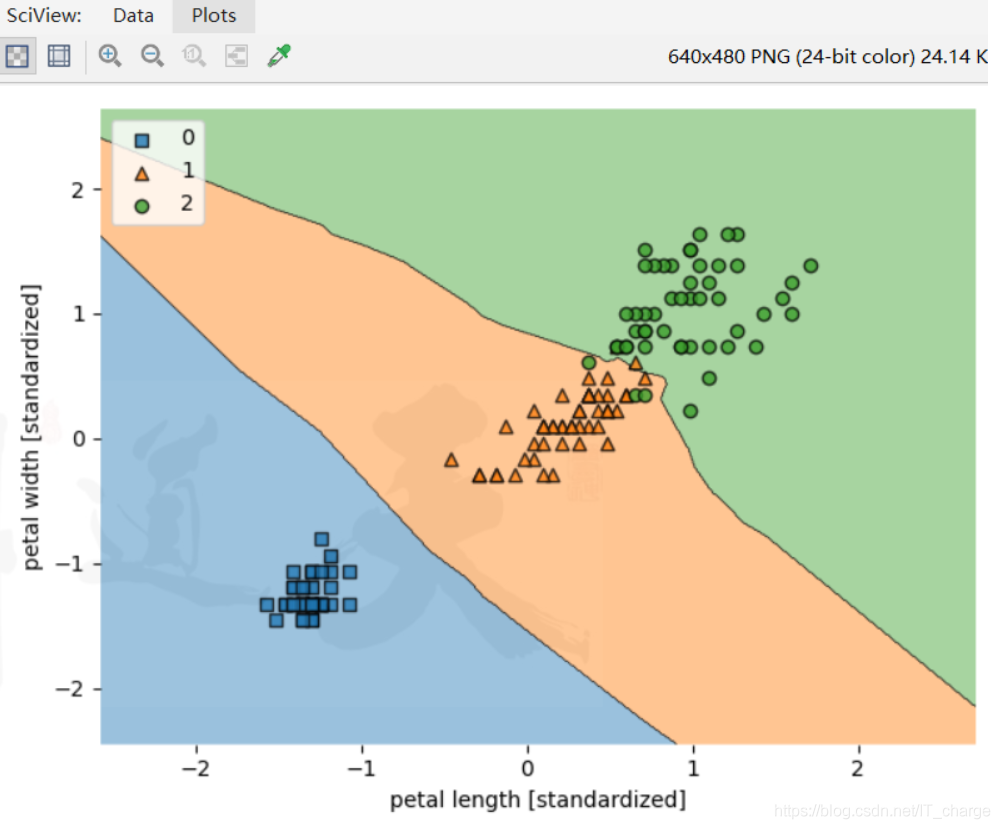
实例十一:kmeans的其他展示方式
''''
实例十一:•kmeans的其他展示方式
'''
import pandas as pd
from sklearn import datasets
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
df = pd.DataFrame(X)
df.columns=['x','y']
df['kind'] = y
df['kind'] = y
# 读取数据
data = iris
# 去除最后一列的数据,也就是标签
data1 = df
# print(data1)
# 聚类数为3
km = KMeans(n_clusters=3)
# 拟合数据
km.fit(data1)
predict = km.predict(data1)
# 设定坐标范围
# plt.figure(figsize=(10,10))
# 开始绘图
colored = ['orange', 'green', 'pink']
col = [colored[i] for i in predict]
plt.scatter(data1['x'], data1['y'], color=col)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
print(predict)
# 真实的值
# 将列表中的最后一行标签转化为数字类型
class_mapping = {'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2}
data1['kind'] = data1['kind'].map(class_mapping)
# 设定颜色
# colored = ['green','orange','pink']
# 把标签设置为不同的颜色
c = [colored[i] for i in y]
# 绘制散点图,用x和y标签
plt.scatter(data1['x'], data1['y'], color=c)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
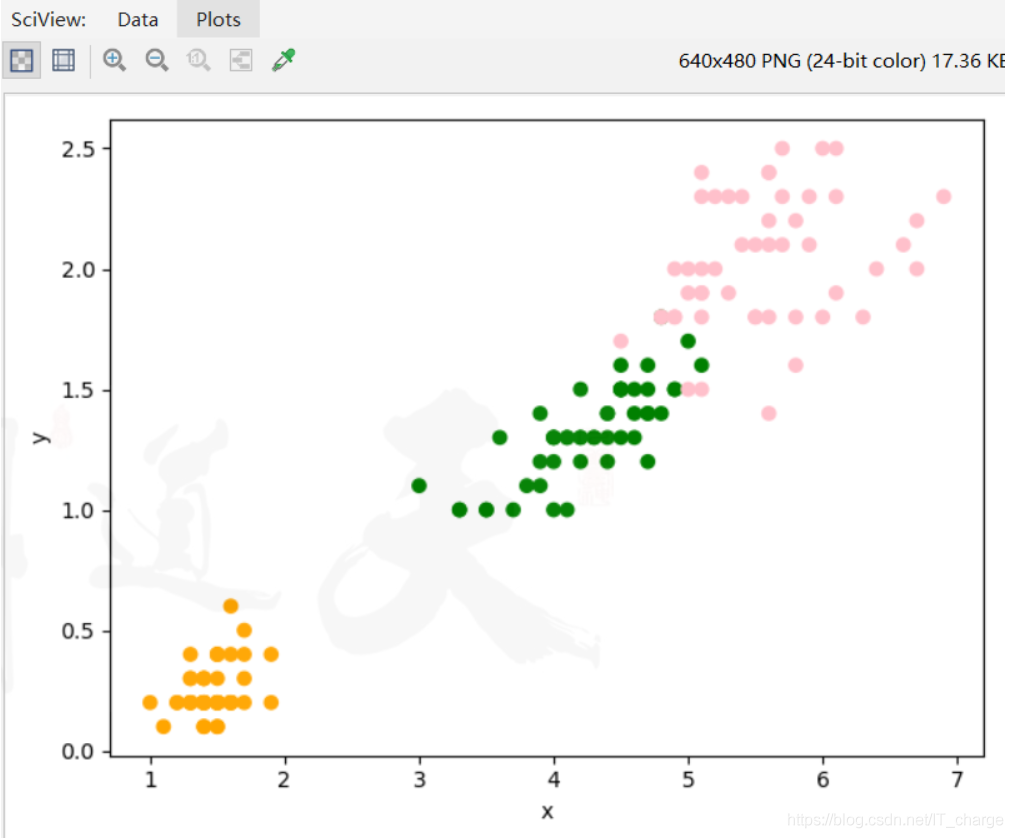
实例十二:Kmeans实现鸢尾花聚类
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv(r"C:\Users\单纯小男子\Downloads\iris.csv")
# 去除最后一列的数据,也就是标签
data1 = data.drop(['kind'], axis=1)
# print(data1)
# 聚类数为3
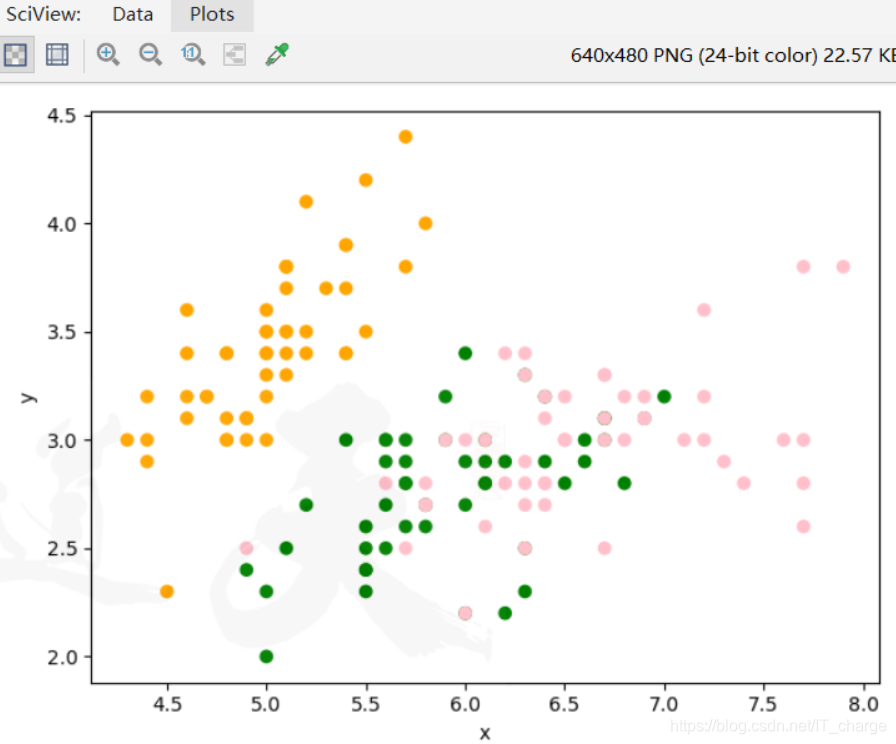
km = KMeans(n_clusters=3)
# 拟合数据
km.fit(data1)
predict = km.predict(data1)
# 设定坐标范围
# plt.figure(figsize=(10,10))
# 开始绘图
colored = ['orange', 'green', 'pink']
col = [colored[i] for i in predict]
plt.scatter(data1['x'], data1['y'], color=col)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
print(predict)
# 真实的值
# 将列表中的最后一行标签转化为数字类型
class_mapping = {'Iris-setosa': 0, 'Iris-versicolor': 1, 'Iris-virginica': 2}
data['kind'] = data['kind'].map(class_mapping)
# 设定颜色
# colored = ['green','orange','pink']
# 把标签设置为不同的颜色
c = [colored[i] for i in data['kind']]
# 绘制散点图,用x和y标签
plt.scatter(data['x'], data['y'], color=c)
plt.xlabel('x')
plt.ylabel('y')
plt.show()

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











