





目录
3.2 程序头表(Program Header Table)
3.3 节(Sections)与节头表(Section Header Table)
1.ELF文件概述
ELF的英文全称是The Executable and Linking Format,最初是由UNIX系统实验室开发、发布的ABI(Application Binary Interface)接口的一部分,也是Linux的主要可执行文件格式。
目标文件是编译出来后,没有进行链接前的中间文件. 一般为Linux平台的目标文件的后缀是: .o 而在Windows平台的目标文件的后缀是.obj; 同时, 目标文件的存储格式实际与可执行文件使用的是同一套存储标准,即 .o文件在Linux平台上与可执行文件都是使用的ELF文件格式进行存储的.
实际上,除了目标文件,我们熟悉的动态链接库文件也是使用ELF文件标准进行存储的. 动态链接库在Linux平台下的后缀是:.so ,而在Windows平台下的后缀是:.dll.
注: windows平台下的可执行文件标签是PE-COFF ,它是标准的COFF文件的变种.
COFF 文件格式是Unix System V Release 3 提出的标准.后来微软公司基于 COFF制定了 PE 文件格式标准. 并将其应用于Windows NT系统. Unix System V4 在COFF的基础上引入了ELF . 目前流行的Linux系统也是使用ELF格式作为基本的可执行文件格式.
2. ELF文件分类
ELF(Executable and Linkable Format)作为主流的二进制文件格式,广泛应用于类 Unix 系统及嵌入式开发领域。从实际开发与运行的使用角度出发,其核心文件类型可分为三类,各类文件在程序编译、链接、执行的全流程中承担不同角色,具体特性与应用场景如下:
一、可执行文件(Executable Files)
可执行文件是 ELF 格式中直接面向操作系统加载运行的最终产物,是程序从 “代码” 转化为 “可执行行为” 的关键载体。
核心作用
作为操作系统可直接调度的文件,它整合了程序运行所需的全部指令(如机器码)、初始化数据(如全局变量初始值)以及加载控制信息(如内存段分配规则),无需额外处理即可被内核加载到内存并启动执行。
关键特点
- 地址已固定:链接过程已完成地址绑定,文件内不存在未确定的相对地址,因此不包含重定位信息(重定位表为空);
- 入口点明确:文件头中记录了程序开始执行的固定地址(如_start符号对应的地址),操作系统加载时会从该地址开始取指运行;
- 结构完整:包含可加载的代码段(.text)、数据段(.data/.bss)及程序运行依赖的动态链接信息(若依赖共享库)。
典型示例
- 系统级工具:类 Unix 系统中/bin目录下的ls(列表显示文件)、cp(复制文件)等基础命令;
- 应用程序:/usr/bin目录下的python(Python 解释器)、gcc(编译器)等可直接启动的工具;
- 自定义程序:C 语言代码经编译链接后生成的a.out(默认可执行文件)或指定名称的执行文件(如app.exe,部分系统兼容该命名)。
二、可重定位文件(Relocatable Files)
可重定位文件又称 “目标文件”,是编译器或汇编器对源代码处理后生成的中间文件,主要用于后续链接器(Linker)的整合操作,是程序模块化开发的核心组成部分。
核心作用
作为代码与数据的 “半成品”,单个可重定位文件对应一个或多个源代码文件(如一个.c文件),用于暂存编译后的机器码与数据,等待链接器将多个同类文件及依赖库组合为完整的可执行文件或共享库。
关键特点
- 地址相对性:文件内的代码与数据地址均为 “相对地址”(以文件自身为基准的偏移量),未绑定到最终运行时的内存地址,无法直接加载执行;
- 含重定位表:包含专门的重定位表(.rel.text/.rel.data等段),记录了所有需要在链接阶段修正的地址位置(如跨文件调用的函数地址、全局变量地址);
- 符号表完整:保留了文件内定义的符号(如函数名、变量名)及引用的外部符号(如调用其他文件的函数),供链接器进行符号解析与地址绑定。
典型示例
- C 语言编译产物:main.c编译生成的main.o、func.c(自定义函数文件)编译生成的func.o;
- 汇编代码产物:DSP28335 汇编程序boot.asm经汇编器处理后生成的boot.obj;
- 模块化开发组件:大型项目中按功能拆分的network.o(网络模块)、storage.o(存储模块)等目标文件,需通过链接器合并为可执行文件。
三、共享目标文件(Shared Object Files)
共享目标文件即 “共享库”,是实现代码复用与内存优化的核心文件类型,可被多个程序在运行时动态加载并共享,避免了代码重复编译与内存重复占用的问题。
核心作用
作为 “可复用的代码库”,共享库中封装了通用功能(如输入输出、数学计算、网络通信),程序编译时无需将其代码嵌入自身,仅记录依赖关系;运行时由动态加载器(如ld-linux.so)将共享库载入内存,多个程序可共用同一库的内存副本。
关键特点
- 动态加载特性:编译链接阶段不直接整合到可执行文件,仅在程序启动或运行中按需加载,减少可执行文件体积;
- 支持重定位与符号共享:包含重定位信息(用于加载时修正地址)和动态符号表(.dynsym),确保加载后能与调用程序正确交互;
- 内存共享:多个程序同时使用同一共享库时,操作系统仅在内存中保留一份库代码,降低内存资源消耗。
典型示例
- 应用级共享库:开发中自定义的libutils.so(工具函数库)、libui.so(界面组件库),可被多个项目引用;
- 跨平台类比:功能等同于 Windows 系统中的动态链接库(.dll文件,如kernel32.dll、user32.dll)。
补充:核心转储文件(Core Dump Files)
除上述三类核心使用场景的文件外,ELF 格式还包括 “核心转储文件”,但该文件主要用于调试,而非日常开发与运行。其作用是程序崩溃(如段错误、内存访问异常)时,操作系统生成的内存快照,记录了崩溃时的内存数据、寄存器状态及调用栈信息,开发人员可通过gdb等调试工具分析该文件,定位程序崩溃原因(如野指针、数组越界)。
综上,ELF 的三类核心文件在程序开发流程中形成 “可重定位文件(编译生成)→ 链接为可执行文件 / 共享库(部署运行)” 的完整链路,分别对应 “中间产物”“最终执行体”“复用组件” 三种角色,支撑了从代码编写到程序运行的全流程需求。
本文主要从elf文件的组成构造的角度来进行分析拆解,将elf文件的数据通过一步一步的拆解得到里面的对应信息,同时通过C++实现解析ELF文件信息,包括添加调试选项(-g)的映射信息。通过本篇文章,你将完全熟悉elf的文件格式。
3.ELF文件的基本格式
ELF 格式凭借统一的结构设计,能够灵活适配可执行文件、可重定位目标文件、共享库等多种类型,其结构从文件头部到尾部遵循固定顺序,各部分协同支撑文件的编译、链接、加载与执行全流程。以下按结构顺序,详细拆解各核心组成部分的功能与关键信息:
3.1 ELF 文件头(ELF Header)
文件的 “总目录”
ELF 文件头位于文件的起始位置,是整个文件的 “入口指南”,操作系统加载文件或链接器处理文件时,首先读取此部分获取基础信息。其大小因架构而异,32 位 ELF 文件头占 52 字节,64 位则占 64 字节。
核心作用
定义 ELF 文件的全局属性,告知处理工具(如内核、链接器)文件的基本类型、架构适配性、关键表的位置等,确保工具能正确识别并解析文件后续内容。
关键内容
1. 魔数(Magic Number):固定为十六进制0x7F 45 4C 46(对应 ASCII 码的DEL E L F),是识别 ELF 格式的唯一标识,工具通过检测魔数快速判断文件是否为 ELF 格式。
2. 基础属性:
- 文件类别:标识文件为 32 位(ELFCLASS32)或 64 位(ELFCLASS64),决定后续地址、偏移量等字段的长度;
- 数据编码:指定字节序为小端序(ELFDATA2LSB,低字节存低地址)或大端序(ELFDATA2MSB,高字节存低地址),确保跨架构解析时数据顺序正确;
- ELF 版本:当前标准版本为 1(EV_CURRENT),保证格式兼容性;
- 目标操作系统 / ABI:如 Linux(ELFOSABI_LINUX)、Solaris 等,明确文件适配的运行环境;
- 目标机器架构:如 x86(EM_386)、ARM(EM_ARM)、x86_64(EM_X86_64),确保指令与硬件架构匹配。
3. 关键表指引:
- 程序入口地址:仅对可执行文件有效,记录文件加载到内存后开始执行的首地址(可重定位文件或共享库此值通常为 0);
- 程序头表信息:包含程序头表在文件中的偏移量、每个表项的大小及表项总数,指引工具找到程序头表位置;
- 节头表信息:包含节头表在文件中的偏移量、每个表项的大小及表项总数,指引工具找到节头表位置;
4. 其他元信息:文件对齐方式(如按 4 字节或 8 字节对齐)、节头表字符串表索引(指向存储节名的字符串表)等,保障文件结构的规整性。
- 魔数(Magic):前 4 字节固定为
0x7F+'E' 'L' 'F',标识 ELF 格式。- 类(Class):1 字节,
0x01表示 32 位,0x02表示 64 位。- 数据编码(Data):1 字节,
0x01表示小端,0x02表示大端。- 版本(Version):1 字节,
0x01为当前 ELF 标准版本。- 操作系统 / ABI 标识(OS/ABI):1 字节,如
0x00为 System V。- ABI 版本(ABI Version):1 字节,通常为
0x00。- 填充(Padding):若干字节,使魔数区域总长度为 16 字节。
- 类型(Type):2 字节,如
0x02为可执行文件(ET_EXEC)。- 机器(Machine):2 字节,如
0x03为 x86,0x28为 ARM 等。- 版本(Version):4 字节,同之前的版本字段(通常
EV_CURRENT即0x01)。- 入口点(Entry):4 字节,程序执行的起始地址。
- 程序头表偏移(Phoff):4 字节,程序头表在文件中的偏移。
- 节头表偏移(Shoff):4 字节,节头表在文件中的偏移。
- 标志(Flags):4 字节,与 CPU 相关的标志(如 ARM 的 Thumb 模式等)。
- ELF 头大小(Ehsize):2 字节,ELF 头自身的长度(通常
0x34即 52 字节)。- 程序头表项大小(Phentsize):2 字节,每个程序头表项的长度。
- 程序头表项数量(Phnum):2 字节,程序头表项的个数。
- 节头表项大小(Shentsize):2 字节,每个节头表项的长度。
- 节头表项数量(Shnum):2 字节,节头表项的个数。
- 字符串表索引(Shstrndx):2 字节,字符串表在节头表中的索引。
3.2 程序头表(Program Header Table)
内存加载的 “规划图”
程序头表仅对可执行文件和共享库有效(可重定位目标文件无需加载到内存执行,通常不含此表),位于 ELF 文件头之后,由多个 “程序头表项”(Program Header)组成,每个表项对应一个 “段(Segment)”。
核心作用
描述 ELF 文件中可加载到内存的段信息,告知操作系统加载时 “如何将文件内容映射到内存”—— 包括映射的位置、大小、权限等,是文件从 “磁盘存储” 转为 “内存运行” 的关键依据。
关键内容(单个程序头表项)
1. 段类型(Type):决定段的功能,常见类型包括:
- PT_LOAD:可加载段,是核心类型,包含代码、数据等需载入内存的内容(如.text 段、.data 段会被整合到PT_LOAD段);
- PT_DYNAMIC:动态链接信息段,存储共享库依赖、动态符号表位置等信息,供动态加载器使用;
- PT_INTERP:解释器路径段,记录动态加载器的路径(如/lib64/ld-linux-x86-64.so.2),可执行文件启动时会调用该解释器加载共享库;
- PT_NOTE:附加信息段,存储文件版本、版权等说明性内容。
2. 映射信息:
- 段在文件中的偏移量:标记段在磁盘文件中的起始位置;
- 段在内存中的虚拟地址:标记段加载到内存后的目标地址;
- 段大小:包含 “文件中实际大小”(磁盘存储的字节数)和 “内存中大小”(加载后占用的内存字节数,若内存大小大于文件大小,多余部分填充 0);
3. 权限控制:指定段加载到内存后的访问权限,包括可读(PF_R)、可写(PF_W)、可执行(PF_X),例如代码段(.text)通常为 “可读 + 可执行”,数据段(.data)通常为 “可读 + 可写”。
3.3 节(Sections)与节头表(Section Header Table)
代码与数据的 “细分容器”
节是 ELF 文件中存储代码、数据及链接信息的基本单位,主要供链接器处理(尤其可重定位目标文件);节头表则是节的 “管理目录”,位于文件后部,由多个 “节头表项”(Section Header)组成,每个表项对应一个节。
1. 节(Sections)
内容的 “具体载体”
根据功能不同,节可分为多个类别,常见类型及作用如下:
| 节类型 | 核心作用 | 特点与示例 |
| 代码相关节 | 存储程序执行指令 | .text:存放机器码指令,权限为 “可读 + 可执行”;.plt:动态链接过程中的函数跳转表(共享库相关) |
| 数据相关节 | 存储程序运行所需数据 | .data:存放已初始化的全局变量 / 静态变量(占文件空间);.bss:存放未初始化的全局变量 / 静态变量(仅占节头表项,不占文件空间,加载时分配内存并清零);.rodata:存放只读数据(如字符串常量、const 修饰的变量),权限为 “只读” |
| 链接相关节 | 支撑链接过程中的地址修正与符号解析 | .symtab:符号表,记录函数名、变量名与地址 / 偏移的映射;.rel.text/.rel.data:重定位表,记录需链接时修正的地址(如跨文件函数调用的地址);.dynsym:动态符号表,仅包含共享库相关的符号(供动态加载器使用) |
| 辅助信息节 | 提供调试、说明等附加信息 | .debug:存放调试信息(如行号与地址的映射,供 gdb 等工具使用);.shstrtab:节名字符串表,存储所有节的名称(节头表通过索引引用此表获取节名);.strtab:普通字符串表,存储符号名等字符串(符号表通过索引引用) |
2. 节头表(Section Header Table)
节的 “管理目录”
节头表是解析节的关键
工具通过它定位每个节的位置、了解节的属性,其每个表项包含以下核心信息:
- 节名索引:指向.shstrtab字符串表的索引,通过该索引可获取节的名称(如 “.text”“(.data”);
- 节类型:标识节的功能(如SHT_PROGBITS表示包含程序数据 / 指令,SHT_SYMTAB表示符号表);
- 节属性:如是否可写(SHF_WRITE)、是否可执行(SHF_EXECINSTR)、是否为分配段(SHF_ALLOC,加载时需分配内存);
- 位置与大小:节在文件中的偏移量、节的总大小、节在内存中的对齐方式;
- 链接信息:如重定位表关联的节(.rel.text关联.text节)、符号表关联的字符串表(.symtab关联.strtab)等。
3.4 辅助核心结构
支撑链接与解析的 “关键组件”
除上述主要结构外,ELF 文件还包含多个辅助结构,保障链接、加载过程的顺畅:
1. 符号表(Symbol Table,.symtab/.dynsym):
- 核心功能:建立 “符号名” 与 “地址 / 偏移” 的映射,解决 “如何找到函数 / 变量位置” 的问题;
- 关键信息:每个符号包含名称(通过索引关联字符串表)、值(可重定位文件中为节内偏移,可执行文件中为内存地址)、类型(函数STT_FUNC、数据STT_OBJECT)、绑定属性(全局符号STB_GLOBAL、局部符号STB_LOCAL)、所在节的索引等。
- 重定位表(Relocation Table,.rel.text/.rel.data):
-
- 核心功能:仅存在于可重定位文件中,记录 “需要链接时修正的地址位置”,例如:当main.c调用func.c中的add()函数时,main.o的.rel.text会记录add()调用指令的地址,链接时 linker 会将该地址修正为add()在最终可执行文件中的实际地址;
-
- 关键信息:每个重定位项包含 “需修正的偏移量”(在节内的位置)、“重定位类型”(如R_386_PC32表示 32 位 PC 相对地址修正)、“符号索引”(关联符号表中需引用的符号)。
2. 字符串表(String Table,.strtab/.shstrtab):
- 核心功能:存储符号名、节名等字符串,通过 “索引 + 字符串表” 的方式替代直接存储字符串,大幅节省文件空间;
- 结构特点:以空字符(\0)分隔每个字符串,例如.strtab中可能存储 “main\0add\0g_var\0”,符号表中通过索引 0 获取 “main”、索引 5 获取 “add”。
3.5 ELF 文件结构总结
层次清晰的 “功能协作体系”
ELF 文件的结构遵循 “总 - 分 - 辅” 的逻辑,各部分层层递进、协同工作:
1. 入口指引:ELF 文件头作为 “总目录”,明确文件的基础属性,并指引工具找到程序头表与节头表;
2. 功能拆分:
- 程序头表聚焦 “内存加载”,描述段的映射规则,支撑可执行文件 / 共享库从磁盘到内存的转换;
- 节头表聚焦 “链接处理”,描述节的细分结构,支撑可重定位文件的合并与地址修正;
3. 辅助支撑:符号表、重定位表、字符串表等辅助结构,解决链接中的符号解析与地址修正问题,保障文件能正确关联依赖、执行指令。
这种结构设计使 ELF 格式既能满足 “编译 - 链接 - 加载 - 执行” 的全生命周期需求,又能适配不同类型的文件(可执行、目标、共享库),成为类 Unix 系统及嵌入式领域的标准二进制格式。
4. 目标文件格式解析
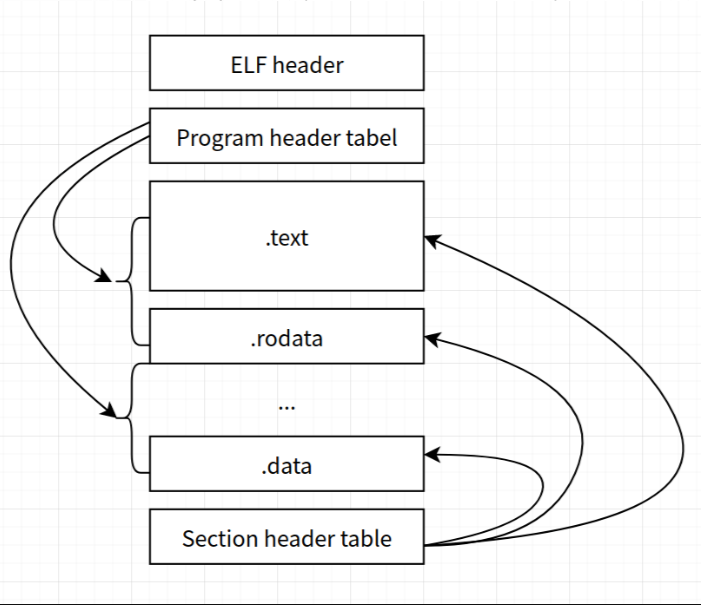
4.1 elf文件头信息解析
elf32的结构体定义:
#define EI_NIDENT (16)
/* Type for a 16-bit quantity. */
typedef uint16_t Elf32_Half;
/* Types for signed and unsigned 32-bit quantities. */
typedef uint32_t Elf32_Word;
/* Type of addresses. */
typedef uint32_t Elf32_Addr;
/* Type of file offsets. */
typedef uint32_t Elf32_Off;
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf32_Half e_type; /* Object file type */
Elf32_Half e_machine; /* Architecture */
Elf32_Word e_version; /* Object file version */
Elf32_Addr e_entry; /* Entry point virtual address */
Elf32_Off e_phoff; /* Program header table file offset */
Elf32_Off e_shoff; /* Section header table file offset */
Elf32_Word e_flags; /* Processor-specific flags */
Elf32_Half e_ehsize; /* ELF header size in bytes */
Elf32_Half e_phentsize; /* Program header table entry size */
Elf32_Half e_phnum; /* Program header table entry count */
Elf32_Half e_shentsize; /* Section header table entry size */
Elf32_Half e_shnum; /* Section header table entry count */
Elf32_Half e_shstrndx; /* Section header string table index */
} Elf32_Ehdr;
e_type
该数据类型是uint16_t数据类型的,占两个字节。通过字段查看,可以看到这个值为00 02。表格定义如下:
名称 取值 含义
ET_NONE 0x0000 未知目标文件格式
ET_ERL 0x0001 可重定位文件
ET_EXEC 0x0002 可执行文件
ET_DYN 0x0003 共享目标文件
ET_CORE 0x0004 Core文件(转储格式)
ET_LOPROC 0xff00 特定处理器文件
ET_HIPROC 0xffff 特定处理器文件
对应表格内容,可以看到类型为EXEC即可执行文件类型。
e_machine
由字段可以看到为00 28,关于这个字段的解析,基本上就是表示该elf文件是针对哪个处理器架构的。
下面只列出几个常见的架构的序号
名称 取值 含义
EM_NONE 0 No machine
EM_SPARC 2 SPARC
EM_386 3 Intel 80386
EM_MIPS 8 MIPS I Architecture
EM_PPC 0x14 PowerPC
EM_ARM 0x28 Advanced RISC Machines ARM
e_entry
这里表示程序的入口地址,为四字节。
e_phoff
该字段表示程序表头偏移。占四个字节,根据字段解析,可以查看当前的偏移量为00 00 00 34。也就是实际的偏移量为52个字节。这52个字节其实就是头部的信息数据结构体的大小。
e_shoff
该区域比较重要,记录了section的偏移地址。对于elf头部文件信息,首先可以根据上述获取文件头部信息:

(1)魔数(Magic,前 4 字节)
字节:
7F 45 4C 46→ 对应 ASCII 的0x7F+'E' 'L' 'F',是 ELF 文件的魔数,确认是 ELF 格式。(2)类(Class,第 5 字节)
字节:
01→ 表示32 位 ELF 文件(ELFCLASS32)。(3)数据编码(Data,第 6 字节)
字节:
02→ 表示大端字节序(ELFDATA2MSB)。若为01则是小端(ELFDATA2LSB)。(4)版本(Version,第 7 字节)
字节:
01→ 表示ELF 标准版本(EV_CURRENT)。(5)操作系统 / ABI 标识(OS/ABI,第 8 字节)
字节:
00→ 表示System V ABI(最常见的 ABI)。(6)ABI 版本(ABI Version,第 9 字节)
字节:
00→ ABI 版本为 0(通常无特殊版本需求时为 0)。(7)填充(Padding,第 10 - 16 字节)
字节:
00 00 00 00 00 00 00→ 填充到魔数区域总长度为 16 字节(ELF 魔数区域固定 16 字节)。(8)类型(Type,第 17 - 18 字节,小端 / 大端需注意)
字节:
00 02→ 大端模式下,实际值为0x0002→ 表示可执行文件(ET_EXEC)。(9)机器(Machine,第 19 - 20 字节)
字节:
00 14→ 大端模式下,实际值为0x0014→ 对应PowerPC架构(10)版本(Version,第 21 - 24 字节)
字节:
00 00 00 01→ 大端模式下,值为0x00000001→ 同之前的版本字段(EV_CURRENT)。(11)入口点(Entry,第 25 - 28 字节)
字节:
00 00 20 68→ 大端模式下,值为0x00002068→ 程序执行的起始虚拟地址。(12)程序头表偏移(Phoff,第 29 - 32 字节)
字节:
00 00 00 34→ 大端模式下,值为0x00000034→ 程序头表在文件中的偏移为 52 字节。(13)节头表偏移(Shoff,第 33 - 36 字节)
字节:
00 02 0B B0→ 大端模式下,值为0x00020BB0→ 节头表在文件中的偏移为0x20BB0字节。(14)标志(Flags,第 37 - 40 字节)
字节:
80 00 00 00→ 大端模式下,值为0x80000000(具体含义需结合 ARM ELF 规范,如可能包含 Thumb 模式、处理器特性等)。(15)ELF 头大小(Ehsize,第 41 - 42 字节)
字节:
34 00→ 大端模式下,值为0x34→ ELF 头自身长度为 52 字节(符合 32 位 ELF 头标准长度)。(16)程序头表项大小(Phentsize,第 43 - 44 字节)
字节:
20 00→ 大端模式下,值为0x20→ 每个程序头表项长度为 32 字节。(17)程序头表项数量(Phnum,第 45 - 46 字节)
字节:
00 0D→ 大端模式下,值为0x0D→ 程序头表包含 13 个项。(18)节头表项大小(Shentsize,第 47 - 48 字节)
字节:
28 00→ 大端模式下,值为0x28→ 每个节头表项长度为 40 字节。(19)节头表项数量(Shnum,第 49 - 50 字节)
字节:
00 1f→ 大端模式下,值为0x1f→ 节头表项数量为 31个。(20)字符串表索引(Shstrndx,第 51 - 52 字节)
字节:
00 1c→ 大端模式下,值为0x1c→ 字符串表在节头表中的索引值为28 。
该 ELF 文件是32 位、大端字节序、PowerPC 架构的可执行文件,符合 System V ABI 标准。程序头表起始于文件偏移 52 字节,包含 13 个项,每个程序头表项长度为 32 字节。节头表在文件中的偏移为0x20BB0字节,节头表项数量为 31个,每个节头表项长度为 40 字节,。
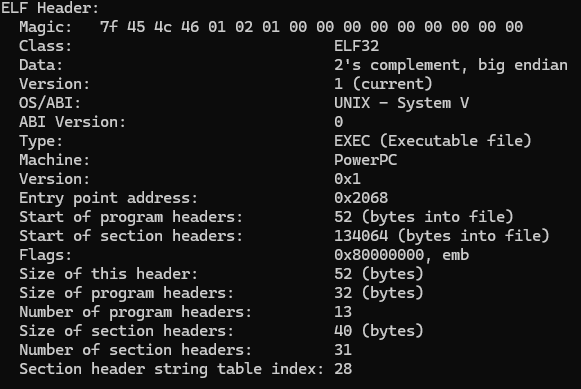
这个时候我们能得到的布局信息如下:
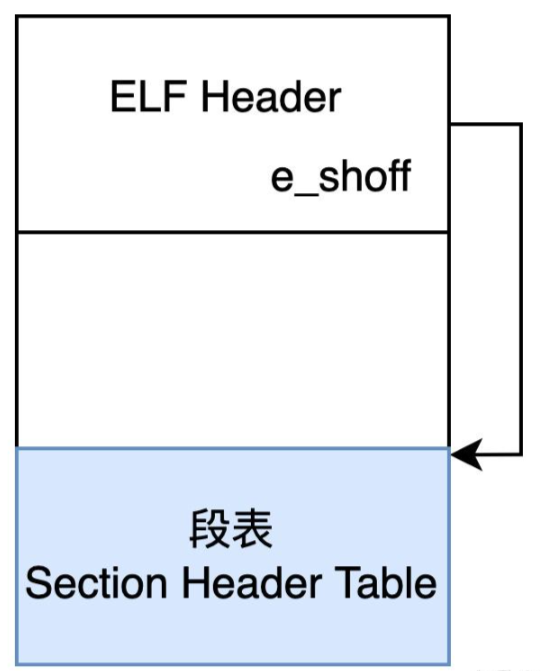
4.2 elf文件节区解析
elf文件中的节是从编译器链接角度来看文件的组成的。从链接器的角度上来看,包括指令、数据、符号以及重定位表等等。
关于理解ELF中的Section,需要知道程序的链接视图,在编译器将一个一个.o文件链接成一个可以执行的elf文件的过程中,同时也生成了一个表。这个表记录了各个Section所处的区域。
#define EI_NIDENT (16)
/* Type for a 16-bit quantity. */
typedef uint16_t Elf32_Half;
/* Types for signed and unsigned 32-bit quantities. */
typedef uint32_t Elf32_Word;
/* Type of addresses. */
typedef uint32_t Elf32_Addr;
/* Type of file offsets. */
typedef uint32_t Elf32_Off;
typedef struct
{
Elf32_Word sh_name; /* Section name (string tbl index) */
Elf32_Word sh_type; /* Section type */
Elf32_Word sh_flags; /* Section flags */
Elf32_Addr sh_addr; /* Section virtual addr at execution */
Elf32_Off sh_offset; /* Section file offset */
Elf32_Word sh_size; /* Section size in bytes */
Elf32_Word sh_link; /* Link to another section */
Elf32_Word sh_info; /* Additional section information */
Elf32_Word sh_addralign; /* Section alignment */
Elf32_Word sh_entsize; /* Entry size if section holds table */
} Elf32_Shdr;通过上述头解析根据e_shoff可以找到section的地址,根据e_shentsize可以找到具体的第一个section的内容。已知段表的起始地址为0x000020bb,头表项数量为 31个,每个节头表项长度为 40 字节,即可计算出:
- 节头表总大小:1240 字节
- 节头表地址范围:
0x00020BB0~0x00021088(包含首尾地址) -

首先从字段结构体上进行分析:
sh_name
表示从e_shstrndx的偏移地址开始,得到的字符字符串信息为该段的名字。
sh_type
字段的类型,关于sh_type的类型,解析如下:
/* Legal values for sh_type (section type). */ #define SHT_NULL 0 /* Section header table entry unused */ #define SHT_PROGBITS 1 /* Program data */ #define SHT_SYMTAB 2 /* Symbol table */ #define SHT_STRTAB 3 /* String table */ #define SHT_RELA 4 /* Relocation entries with addends */ #define SHT_HASH 5 /* Symbol hash table */ #define SHT_DYNAMIC 6 /* Dynamic linking information */ #define SHT_NOTE 7 /* Notes */ #define SHT_NOBITS 8 /* Program space with no data (bss) */ #define SHT_REL 9 /* Relocation entries, no addends */ #define SHT_SHLIB 10 /* Reserved */ #define SHT_DYNSYM 11 /* Dynamic linker symbol table */ #define SHT_INIT_ARRAY 14 /* Array of constructors */ #define SHT_FINI_ARRAY 15 /* Array of destructors */ #define SHT_PREINIT_ARRAY 16 /* Array of pre-constructors */ #define SHT_GROUP 17 /* Section group */ #define SHT_SYMTAB_SHNDX 18 /* Extended section indeces */ #define SHT_NUM 19 /* Number of defined types. */ #define SHT_LOOS 0x60000000 /* Start OS-specific. */ #define SHT_GNU_ATTRIBUTES 0x6ffffff5 /* Object attributes. */ #define SHT_GNU_HASH 0x6ffffff6 /* GNU-style hash table. */ #define SHT_GNU_LIBLIST 0x6ffffff7 /* Prelink library list */ #define SHT_CHECKSUM 0x6ffffff8 /* Checksum for DSO content. */ #define SHT_LOSUNW 0x6ffffffa /* Sun-specific low bound. */ #define SHT_SUNW_move 0x6ffffffa #define SHT_SUNW_COMDAT 0x6ffffffb #define SHT_SUNW_syminfo 0x6ffffffc #define SHT_GNU_verdef 0x6ffffffd /* Version definition section. */ #define SHT_GNU_verneed 0x6ffffffe /* Version needs section. */ #define SHT_GNU_versym 0x6fffffff /* Version symbol table. */ #define SHT_HISUNW 0x6fffffff /* Sun-specific high bound. */ #define SHT_HIOS 0x6fffffff /* End OS-specific type */ #define SHT_LOPROC 0x70000000 /* Start of processor-specific */ #define SHT_HIPROC 0x7fffffff /* End of processor-specific */ #define SHT_LOUSER 0x80000000 /* Start of application-specific */ #define SHT_HIUSER 0x8fffffff /* End of application-specific */
sh_flags
表示段的标志,
A表示分配的内存、AX表示分配可执行、WA表示分配内存并且可以修改。
sh_addr
加载后程序段的虚拟地址
sh_offset
表示段在文件中的偏移。
sh_size
段的长度
sh_addralign
段对齐
sh_entsize
每项固定的大小
以第二个节头表项的40字节分析为例
待分析 16 进制数据(共 40 字节,按 4 字节分组对应上述字段):
00 00 00 01 00 00 00 01 00 00 00 03 00 00 00 00 00 00 01 e0 00 00 1f d8 00 00 00 00 00 00 00 00 00 00 00 04 00 00 00 00
1. 字段 1:sh_name(0-3 字节)
- 16 进制:00 00 00 01
- 大端还原(直接拼接):0x00000001(十进制 = 1)
- 含义:节名称在 “字符串表节” 中的偏移为 1,需结合字符串表节的内容才能确定具体名称(如偏移 1 对应的字符串可能是.text、.data等)。
2. 字段 2:sh_type(4-7 字节)
- 16 进制:00 00 00 01
- 大端还原:0x00000001
- 含义:节类型为SHT_PROGBITS(ELF 标准定义的 “程序数据节”),表示此节包含程序运行所需的实际数据或指令(如代码段、数据段均属此类)。
3. 字段 3:sh_flags(8-11 字节)
- 16 进制:00 00 00 03
- 大端还原:0x00000003(二进制 = 0b0011)
- 对应符号属性:SHF_ALLOC(0x2)| SHF_EXECINSTR(0x1),即节头表中的 “AX” 属性:
4. 字段 4:sh_addr(12-15 字节)
- 16 进制:00 00 00 00
- 大端还原:0x00000000
- 含义:节在内存中的起始地址未指定(常见于 “可重定位文件”,如.o目标文件),链接器会在链接时根据内存布局分配实际地址;若为可执行文件(.exe),此值应为非 0 的内存地址。
5. 字段 5:sh_offset(16-19 字节)
- 16 进制:00 00 01 e0
- 大端还原:0x000001E0(十进制 = 480)
- 含义:此节在 ELF 文件中的起始偏移为480 字节(从文件开头第 0 字节开始计算),即文件中第 480 字节到(480+sh_size-1)字节是该节的实际数据。
6. 字段 6:sh_size(20-23 字节)
- 16 进制:00 00 1f d8
- 大端还原:0x00001FD8(十进制 = 8152)
- 含义:节的总大小为8152 字节,即该节在文件中占据 8152 字节的数据(从 sh_offset=480 开始,到 480+8152-1=8631 字节结束)。
7. 字段 7:sh_link(24-27 字节)
- 16 进制:00 00 00 00
- 大端还原:0x00000000
- 含义:无关联节(仅特定类型的节需要关联,如符号表节 SHT_SYMTAB 需关联字符串表节,而 SHT_PROGBITS 类型节通常无需关联)。
8. 字段 8:sh_info(28-31 字节)
- 16 进制:00 00 00 00
- 大端还原:0x00000000
- 含义:无附加信息(SHT_PROGBITS 类型节无需附加信息,仅符号表、重定位表等节需此字段)。
9. 字段 9:sh_addralign(32-35 字节)
- 16 进制:00 00 00 04
- 大端还原:0x00000004(十进制 = 4)
- 含义:节在内存中的对齐要求为4 字节(PowerPC 架构的基本数据对齐单位,符合 RISC 架构 “对齐访问” 的设计,避免非对齐访问导致的性能损耗或错误)。
10. 字段 10:sh_entsize(36-39 字节)
- 16 进制:00 00 00 00
- 大端还原:0x00000000
- 含义:此节非 “表结构”(如符号表是表结构,sh_entsize=16 字节;而数据段是连续数据,无表项概念,故为 0)。
以readelf解析内容为例对比分析:
节头表列表字段
对应值
此前十六进制拆解结果
匹配验证结论
Nr(节索引)
1
-(索引由节头表顺序确定)
节头表中第 1 个有效节(索引从 0 开始时,此为索引 1)
Name(节名称)
.reset
sh_name=0x00000001(字符串表偏移 1)
字符串表偏移 1 对应的值为 “.reset”,补全节名称
Type(节类型)
PROGBITS
sh_type=0x00000001(SHT_PROGBITS)
完全匹配,确认为程序数据节
Addr(内存地址)
00000000
sh_addr=0x00000000
完全匹配,为可重定位文件(未分配内存地址)
Off(文件偏移)
0001e0
sh_offset=0x000001E0(十进制 480)
完全匹配,文件中起始位置一致
Size(节大小)
001fd8
sh_size=0x00001FD8(十进制 8152)
完全匹配,节数据长度一致
ES(表项大小)
00
sh_entsize=0x00000000
完全匹配,非表结构节
Flg(节属性)
AX
sh_flags=0x00000006
(SHF_ALLOC | SHF_EXECINSTR)
Lk(关联节索引)
0
sh_link=0x00000000
完全匹配,无关联节
Inf(附加信息)
0
sh_info=0x00000000
完全匹配,无附加信息
Al(对齐要求)
4
sh_addralign=0x00000004
完全匹配,4 字节对齐
关键属性补充:节属性 “AX” 的深度解析
此前通过十六进制拆解,sh_flags=0x00000003(二进制0b0011),初步判断为 “SHF_ALLOC | SHF_EXECINSTR”(可加载 + 可写):
ELF 节属性 “Flg” 的符号含义
ELF 标准中,节属性的符号表示与十六进制值的对应关系如下:
| 符号 | 对应十六进制值 | 属性含义 |
| A | 0x2(SHF_ALLOC) | 节需加载到内存 |
| W | 0x4(SHF_WRITE) | 内存中可写 |
| X | 0x1(SHF_EXECINSTR) | 内存中可执行(代码段) |
4.3 elf文件段区解析
- 段(Segment):从 “内存视角” 对数据的物理划分,用于程序加载到内存后的动态执行,是连续的内存块,包含一个或多个属性兼容的节(如 “可执行段” 可能包含
.text和.reset节),由程序头表(Program Header Table)描述。
映射关系:一个段可包含多个节(节的属性需与段的权限兼容),一个节只能属于一个段。
typedef struct {
Elf32_Word p_type; // 段类型(如LOAD、DYNAMIC等)
Elf32_Off p_offset; // 段在文件中的起始偏移(文件视角)
Elf32_Addr p_vaddr; // 段在内存中的虚拟地址(内存视角)
Elf32_Addr p_paddr; // 段在内存中的物理地址(PowerPC等嵌入式架构常用)
Elf32_Word p_filesz; // 段在文件中的大小(字节)
Elf32_Word p_memsz; // 段在内存中的大小(字节,可能大于p_filesz,如.bss节)
Elf32_Word p_flags; // 段的权限标志(如R=读、W=写、X=执行)
Elf32_Word p_align; // 段在内存中的对齐要求(2的幂,如4、16等)
} Elf32_Phdr;关键字段解析(以 PowerPC 架构为例):
- p_type:最核心的类型是
PT_LOAD(可加载段),表示该段需要被加载到内存,节到段的映射主要针对PT_LOAD类型。 - p_flags:段的权限标志,与节的
sh_flags对应(如节的AX属性对应段的RX权限),常见组合:PF_R(0x4):可读;PF_W(0x2):可写;PF_X(0x1):可执行。
- p_vaddr/p_paddr:PowerPC 嵌入式系统中,
p_paddr通常设置为物理地址(如复位段映射到 0x00000000),确保硬件能直接访问。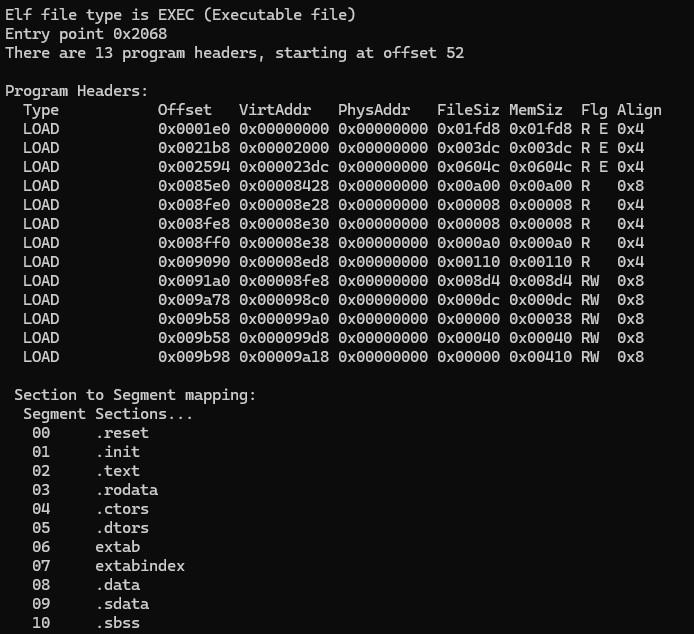
总结:映射的核心作用
节到段的映射是 ELF 文件从 “静态存储” 到 “动态执行” 的关键转换:
- 对开发人员:通过节的逻辑划分便于代码组织(如分离代码与数据);
- 对加载器 / 硬件:通过段的物理划分实现内存高效加载、权限控制和架构适配(如 PowerPC 的地址对齐、复位向量映射)。理解这一映射关系,是分析 ELF 文件在 PowerPC 架构上的加载执行流程、调试内存访问异常的基础。
4.4 elf文件符号节表
ELF 文件中的符号信息存储在符号表节(Symbol Table Section) 中,而非直接存储在 “段(Segment)” 中。但符号表节会被包含在某个可加载段(通常是包含只读数据的段)中,随段一起加载到内存。以下是具体解析:
一、符号的存储位置:符号表节(.symtab)
ELF 文件的符号(如函数名、变量名、符号地址等)主要存储在符号表节中,该节的类型为SHT_SYMTAB(在节头表中sh_type=2),通常名为.symtab。符号表节的结构由Elf32_Sym结构体数组组成(32 位 ELF),每个结构体对应一个符号,包含符号名称(字符串表索引)、值(地址)、大小、类型、绑定属性等信息:
c
typedef struct {
Elf32_Word st_name; // 符号名称在字符串表中的偏移(索引)
Elf32_Addr st_value; // 符号的值(如函数地址、变量地址)
Elf32_Word st_size; // 符号大小(如变量占用字节数)
unsigned char st_info; // 符号类型(如函数、变量)和绑定属性(如全局、局部)
unsigned char st_other;// 未使用(通常为0)
Elf32_Half st_shndx; // 符号所在节的索引(如.text节的索引)
} Elf32_Sym;
此外,符号表通常关联一个字符串表节(.strtab),用于存储符号的实际名称(.symtab的st_name字段指向.strtab的偏移)。
二、符号表节所属的段:只读数据段(PT_LOAD)
符号表节(.symtab)本身是 “辅助信息节”,不直接参与程序执行,但会被包含在某个可加载段(PT_LOAD 类型) 中 —— 通常与其他只读数据节(如字符串表.strtab、重定位表.rel.text等)合并到同一个段,该段的权限为PF_R(只读)。
例如,通过readelf -l查看段信息时,可能会看到:
plaintext
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x0001e0 0x00000000 0x00000000 0x01fd8 0x01fd8 R X 4 # 可执行段(含.text、.reset)
LOAD 0x0021b8 0x00002000 0x00002000 0x00500 0x00800 R W 4 # 数据段(含.data、.bss)
LOAD 0x0026b8 0x00002800 0x00002800 0x00a00 0x00a00 R 4 # 只读信息段(含.symtab、.strtab)
其中,.symtab和.strtab被包含在第三个PT_LOAD段中(权限R),随该段加载到内存地址0x00002800。
三、符号的读取方式:通过节头表定位
工具(如readelf、objdump)或加载器读取符号时,并非直接从段中读取,而是通过以下步骤:
- 解析节头表(Section Header Table),找到类型为
SHT_SYMTAB的节(即.symtab); - 根据
.symtab节头的sh_offset字段,从 ELF 文件中读取该节的原始数据(Elf32_Sym数组); - 结合
.symtab的sh_link字段(指向字符串表.strtab的索引),从.strtab中读取符号的实际名称(通过st_name偏移); - 若符号表被加载到内存,可通过节头的
sh_addr字段(内存地址)直接访问内存中的符号数据。
四、总结
- 符号的存储载体:符号信息本质存储在符号表节(.symtab) 中,依赖字符串表节(.strtab)存储名称;
- 与段的关系:.symtab 节会被包含在一个只读可加载段(PT_LOAD,权限 R) 中,随段加载到内存,但符号的定位和解析主要依赖节头表,而非段信息;
- 工具查看方式:使用
readelf -s <elf文件>可直接读取符号表,输出符号名称、地址、类型等信息,其底层就是解析.symtab和.strtab节的数据。
5. 反汇编解析
结合 ELF 文件的符号节表、段区划分、节区划分和头信息进行反汇编,核心是通过这些结构定位可执行代码所在的节(如.text、.reset),再利用工具解析指令二进制数据并转换为汇编代码。以下是具体步骤和原理:
一、反汇编的核心依据:可执行节的定位
反汇编的对象是包含机器指令的可执行节(通常类型为SHT_PROGBITS,属性含SHF_EXECINSTR,即X标志),这些节是反汇编的 “数据源”。定位可执行节的关键信息来自:
- 节头表(Section Header Table):
- 筛选
sh_type=SHT_PROGBITS且sh_flags含SHF_EXECINSTR(即X属性)的节(如.text、.reset),这些节存储实际指令。 - 记录节的
sh_offset(文件中偏移)、sh_size(指令长度)、sh_addr(内存地址,用于指令地址标注)。
- 筛选
- 段划分(Program Header Table):
- 可执行节通常属于
PT_LOAD类型且p_flags含PF_X(执行权限)的段,通过段的p_offset和p_vaddr可辅助验证节的文件 / 内存位置是否合法(避免非可执行数据被误解析)。
- 可执行节通常属于
二、反汇编的完整流程(以 PowerPC ELF 为例)
步骤 1:解析头信息,确认文件格式与架构
- 从ELF 文件头(Elf32_Ehdr) 中获取
e_ident字段,确认:- 位数(32 位 / 64 位):
EI_CLASS字段(1=32 位,2=64 位); - 字节序:
EI_DATA字段(1 = 小端,2 = 大端,PowerPC 为大端); - 架构:
e_machine字段(0x14=PowerPC),确保反汇编工具使用正确的指令集(如 PowerPC 的lis、mtspr等指令)。
- 位数(32 位 / 64 位):
步骤 2:通过节头表定位可执行节
- 遍历节头表,找到所有可执行节(如
.reset、.text),提取关键信息:- 以
.reset节为例:sh_offset=0x0001e0(文件中起始位置)、sh_size=0x1fd8(指令总长度)、sh_addr=0x00000000(内存地址,用于汇编指令前的地址标注)。
- 以
步骤 3:提取可执行节的二进制指令数据
- 根据节的
sh_offset和sh_size,从 ELF 文件中读取对应范围的二进制数据(即机器指令的原始字节流)。- 例如:
.reset节从文件偏移0x0001e0开始,读取0x1fd8字节的二进制数据,这部分数据是 PowerPC 指令的原始编码(如0x3c000000对应lis %r0, 0x0000)。
- 例如:
步骤 4:结合符号表标注函数 / 变量名称
- 反汇编工具会解析符号表(.symtab),将指令地址与符号关联,在汇编代码中显示函数名或变量名(而非纯地址):
- 符号表的
Elf32_Sym结构体中,st_value是符号地址(如函数入口地址),st_name指向.strtab中的符号名称(如 “main”“reset_handler”)。 - 例如:若
.reset节中0x00000000地址对应符号表中st_value=0x00000000、st_name="reset_init",则反汇编时会在该地址处标注reset_init:,提升可读性。
- 符号表的
步骤 5:调用反汇编工具生成汇编代码
- 工具(如
objdump、gdb)根据架构(PowerPC)、字节序(大端)和二进制指令数据,将机器码转换为汇编指令:- 示例命令(针对
.reset节):bash
objdump -M powerpc,big -d -j .reset <elf文件>-M powerpc,big:指定 PowerPC 架构和大端字节序;-d:反汇编可执行节;-j .reset:仅反汇编.reset节。
- 输出示例(简化):
plaintext
00000000 <reset_init>: 0: 3c 00 00 00 lis %r0, 0x0000 4: 60 00 00 00 nop 8: 7c 08 02 a6 mflr %r0 ...
- 示例命令(针对
步骤 6:验证反汇编结果(可选)
- 结合段划分验证:可执行节所在的段
p_flags必须含PF_X(执行权限),若反汇编的节不在此类段中,可能是误解析(如数据节被当作代码)。 - 结合节对齐验证:PowerPC 指令为 4 字节对齐,反汇编的指令地址应能被 4 整除(如
0x0、0x4、0x8),若出现非对齐地址,可能是节数据损坏或工具参数错误。
三、关键工具与参数解析
- objdump(最常用):
- 核心参数:
-d(反汇编可执行节)、-j <节名>(指定节)、-M <架构,字节序>(指定架构和字节序,如powerpc,big)、-S(结合源代码,需编译时带-g)。
- 核心参数:
- readelf(辅助定位节信息):
- 先通过
readelf -S <elf文件>确认可执行节的sh_offset和sh_size,再用objdump精准反汇编。
- 先通过
- gdb(动态调试反汇编):
- 加载 ELF 文件后,用
disassemble <地址范围>反汇编指定内存区域(如disassemble 0x00000000,0x00002000),结合符号表自动标注函数名。
- 加载 ELF 文件后,用
四、总结
反汇编的本质是 “将可执行节的二进制指令,按特定架构的指令集规则转换为汇编代码”,而 ELF 的各结构(头信息、节 / 段划分、符号表)的作用是:
- 头信息:确定解析规则(架构、字节序、位数);
- 节 / 段划分:定位可执行代码的位置(文件偏移、长度);
- 符号表:为汇编代码添加名称标注(函数、变量)。通过工具整合这些信息,即可完成从 ELF 文件到汇编代码的转换,这是逆向分析、调试和理解程序执行流程的核心手段。

















 5933
5933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









