









数据结构:字符串
字符串基础
字符串的表示方式
char[]数组:手动管理字符串的长度和内存分配;容易越界;(C风格字符串)
vector<char>向量数组:可以动态调整(向量的自动扩容机制)数组大小,但是需要额外操作来实现字符串操作;
string类:提供了丰富的成员函数用于字符串操作;
char[]数组的字符串会自动在字符串末尾加上\0,如果要获取字符串长度,就需要遍历数组知道找到\0后停止,看遍历了多少个元素;
而vectot<char>只需要调用size()方法即可获取字符串长度;string也可以通过size()方法来获取字符串长度;
string类
string 类是 C++ 标准库中提供的用于操作字符串的类,位于命名空间 std 中。它封装了对字符串的常见操作,提供了丰富的成员函数用于字符串的增、删、改、查等操作,使得对字符串的处理更加方便、安全和高效。
string 类重载了加号(+)操作符,用于字符串的拼接操作。通过重载+操作符,可以实现两个 string 对象或 string 对象与字符串字面值之间的拼接,此种方式比之前的字符串拼接都要简便多;(注意必须是字符串,而不是字符串和字符的拼接)
string常见成员函数:
| 函数名 | 输入 | 输出 | 功能 |
|---|---|---|---|
length() | 无 | 返回字符串长度 | 返回字符串中字符的数量 |
size() | 无 | 返回字符串长度 | 返回字符串中字符的数量 |
empty() | 无 | 布尔值(true 或 false) | 检查字符串是否为空 |
clear() | 无 | 无 | 清空字符串内容 |
substr() | 起始位置、子串长度 | 返回子串 | 返回从起始位置开始指定长度的子串 |
append() | 字符串、字符、起始位置、长度 | 无 | 将指定内容添加到字符串末尾 |
insert() | 插入位置、字符串、字符、起始位置、长度 | 无 | 在指定位置插入字符串或字符 |
erase() | 起始位置、长度 | 无 | 从字符串中删除指定位置开始的指定长度字符 |
replace() | 起始位置、长度、字符串 | 无 | 用指定字符串替换指定位置开始的指定长度的字符 |
find() | 查找内容、起始位置 | 返回字符串位置(或 npos) | 在字符串中查找指定内容的位置,返回找到的第一个匹配子串的位置,如果未找到则返回 std::string::npos |
swap函数的两种实现方式:
// 常见的交换数值
int tmp = s[i];
s[i] = s[j];
s[j] = tmp;
// 使用位运算符异或实现swap函数
s[i] ^= s[j];
s[j] ^= s[i]; // s[j]新 = s[j]旧 ^ s[i]旧 ^ s[j]旧 = s[i],自己异或自己为全0,全0异或s[i]就是s[i];
s[i] ^= s[j];
读取字符串和打印字符串:
getline():读取一行字符串的输入,注意换行符不会读进来;(由于换行符不会被读取进来,所以可能要用getchar()配合清楚缓存区的换行符)
std::string input;
std::getline(std::cin, input); // 从cin流读取一行字符串到input变量;
std::string input = "apple,banana,cherry";
std::istringstream iss(input);
std::string token;
while (std::getline(iss, token, ',')) {
// 按照指定分界符读取一行;注意不能再cin流这么使用;
std::cout << token << std::endl;
}
istringstream将字符串包装为流,然后使用getline和逗号拆分字符串并打印输出每个子字符串,而getline(cin, token, ',');不可以,因为cin是整个字符串流;(如果是stringstream也可以)
getchar():读取一个字符;
cin、cout:从控制台获取输入和输出;
切割字符串:
substr函数:截取字符串中的子串,传入起始位置和终止位置的迭代器(左闭右开)或者传入起始位置索引和子串长度;(经常和find()一起连用)
std::string substr(size_t pos = 0, size_t len = npos) const;
std::string substr(iterator first, iterator last) const;
string ss = "abcdefg";
string subs = substr(ss.begin(), ss.end() - 1); //传入迭代器切割子串;
substring s = "cd";
size_t c = ss.find(s); // 模式串匹配,返回第一个匹配的子串的起始位置;
string subs = substr(c, s.length()); // 获取子串;
auto cc = find(ss.begin(), ss.end(), s); // find和substr既可以通过索引也可以通过迭代器使用;
string subs = substr(cc, cc + s.length());
stringstream流和isstringstream流:
std::istringstream:
std::istringstream是一个用于输入的流类,通常用于将字符串转换为输入流,以便从字符串中提取数据。- 主要用途是将字符串解析为不同的类型数据,如从字符串中提取整数、浮点数等。
- 只能从字符串中读取数据,不能写入数据到流中。
- 继承自
std::basic_istream类。
std::stringstream:(更强大)
std::stringstream是一个同时用于输入和输出的流类,可以用于在内存中读写字符串数据。- 可以通过
<<和>>运算符从std::string中提取数据,也可以将数据写入std::string。 - 可以用于字符串的拼接、格式化输出等操作。
- 继承自
std::basic_iostream类。
在处理字符串按照某个字符切割时,使用stringstream类超级方便;
#include <sstream>
// 从字符串中提取数据;(默认以空格分割)
std::string data = "10 20 30";
std::stringstream ss(data);
int num;
while (ss >> num) { // 可以将字符串转换为数字;(自动处理,不需要类型转换,及其方便)
std::cout << num << std::endl;
}
拼接字符串:直接使用重载后的加号运算符即可实现拼接两个字符串;
查找字符串中某个字符:
find()函数:(两种)
std::string str = "Hello, World!";
char target = ',';
size_t found = str.find(target); // 返回索引
auto it = std::find(str.begin(), str.end(), target); // 返回迭代器类型
// 查找某个字符串:
std::string str = "Hello, World!";
std::string pattern = "Wo";
size_t found = str.find(pattern);
常见字符串操作
- 按照空格切割字符串并输出;
- 按照逗号切割字符串并输出;
- 添加字符到字符串末尾;
- 拼接字符串;
// 绝大多数使用stringstream流即可实现;(find和substr结合也可以实现,正则表达式也可以实现,但stringstream最方便)
#include <sstream>
#include <string>
using namespace std;
int main () {
string str1 = "1,2,3,4";
string str2 = "1 2 3 4";
stringstream ss1(str1);
stringstream ss2(str2);
string token;
while (getline(ss1, token, ',')) cout << token << endl;
while (ss2 >> token) cout << token << endl;
str1.push_back('a'); // push_back一个字符到字符串末尾;
// str1 += 'a'; // 不可以,字符串和字符不能拼接;
str1 += "a";
}
KMP算法
KMP(Knuth-Morris-Pratt)算法是一种高效的字符串匹配算法,用于在一个文本串中寻找一个模式串的出现位置。KMP 算法通过预处理模式串构建一个部分匹配表(Partial Match Table),利用这个表在匹配过程中避免了不必要的回溯,从而提高了匹配的效率。
KMP 算法的主要思想包括以下步骤:
构建部分匹配表(Partial Match Table,即next数组):
- 部分匹配表是模式串本身的一种特殊形式,用于记录每个位置前缀字符串的最长相等前缀后缀长度。
- 该表的构建是 KMP 算法的关键,通过计算每个位置的最长匹配长度来避免不必要的回溯。
匹配过程:
- 在匹配过程中,主串的指针不回溯,而是根据模式串的部分匹配表决定向右移动的步数。
- 当出现不匹配时,根据部分匹配表跳过已匹配的部分,继续向右移动模式串。
明确几个概念:
- 文本串(主串):需要进行搜索或匹配操作的原始字符串,通常是待搜索的长字符串。
- 模式串(子串):在文本串中搜索或匹配的目标子字符串,通常是较短的字符串。
- 文本串指针(主串指针):用来遍历文本串的指针或索引,指向当前检查的文本串字符位置。
- 模式串指针(子串指针):用来遍历模式串的指针或索引,指向当前检查的模式串字符位置。
- 不匹配:当前文本串指针指向的字符和模式串指针指向的字符不相同;
KMP的思想:当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。(即避免文本串指针回溯)记录的一部分已经匹配的文本内容的信息,就是next数组;next数组就是一个前缀表(prefix table),指出了当发生字符不匹配时,模式串指针要回到哪去继续匹配;
KMP算法思想推导
文本串:string ss = "aaabd",模式串:string subs = "aab";
如果不使用KMP算法,则需要使用回溯(回溯文本串指针):
ss[0]和subs[0]匹配,匹配成功;ss[1]和subs[1]匹配,匹配成功;ss[2]和subs[2]匹配,匹配失败;
对于匹配失败时的不同处理,就是暴力回溯匹配和KMP算法的差异;
如果从subs[0]和ss[1]重新开始匹配,则是回溯法;(暴力匹配,文本串中每一个字符都作为第一个字符和子串进行匹配)
如果利用前面已经匹配的部分字符串(模式串中的字符b匹配失败了,但是我们知道模式串中b前面的字符一定都匹配成功了,这部分匹配成功的信息应该被利用),从ss[2]和subs[1]开始匹配,则是KMP算法;
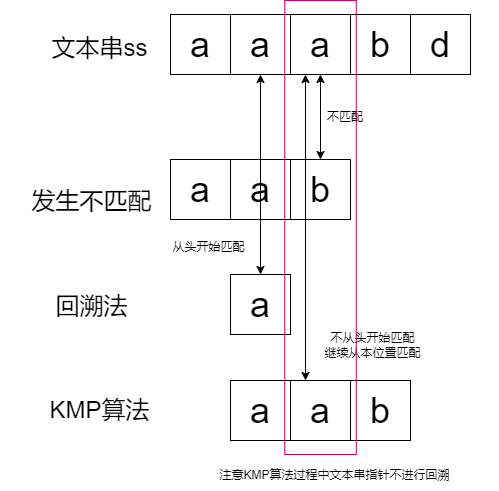
举一个特殊而又简单的例子,如果模式串是”aaaaab",而文本串是"aaaaaab",在匹配第6个字符时,模式串是"b",文本串是"a",所以发生不匹配;如果是暴力匹配,则需要将文本串指针和模式串指针同步回退;而事实上,大可不必,因为"b"匹配失败的同时带来了前5个"a"是匹配成功的,所以文本串指针没必要回退,而模式串指针只用回退1个位置即可,在下一轮对比即可找到匹配子串;如果文本串回退,因为前5个字符都是"a",所以要多比较4次"a == a",而这4次"a == a"本来是没必要的;
暴力匹配:文本串指针和模式串指针同步回退;
改进之后:文本串不动,模式串相对于文本串右移(本例子中只用右移一位);
从这个例子出发,引出了KMP算法的基本思路:不同步回退,文本串不动,模式串相对于文本串右移;所以KMP算法的关键也就呼之欲出——模式串相对于文本串右移多少位;
这也是改进暴力算法的一般思想:看之前的经验能不能用于之后的预期,即看之前已经匹配的字符是否能减少之后某个字符不匹配时的比较次数;(记忆=经验=预知力)
我们将模式串相对于文本串右移的位数定义为前缀表;前缀表可以用来回退,记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。
KMP算法中文本串指针和模式串指针在不匹配时的变化:文本串指针不回溯,即不匹配之后,文本串指针不变;模式串指针根据next前缀表进行回溯;
要在文本串:aabaabaafa 中查找是否出现过一个模式串aabaaf:
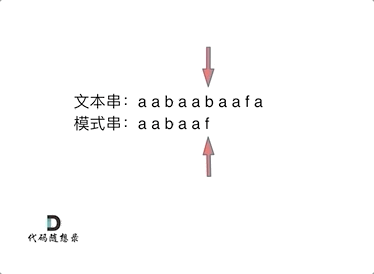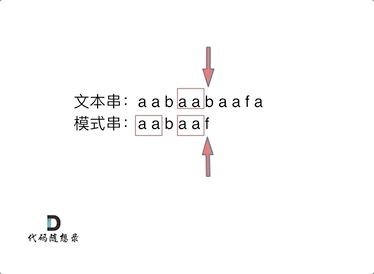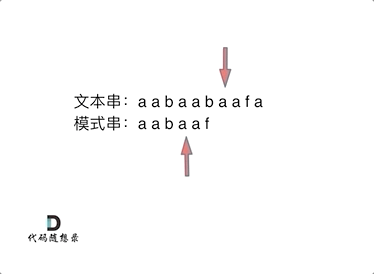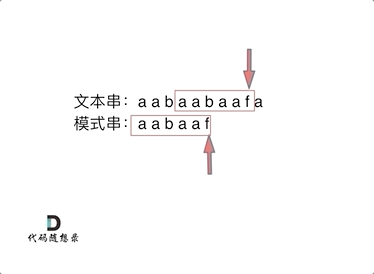
文本串中第六个字符b和模式串的第六个字符f,不匹配了。如果暴力匹配,发现不匹配,此时就要从头匹配了。但如果使用前缀表,就不会从头匹配,而是从上次已经匹配的内容开始匹配,找到了模式串中第三个字符b继续开始匹配。
next数组
当发生不匹配时,模式串相对于文本串右移,右移多少位?如果每次右移1位,能不能保证文本串指针不变,然后进行比较?事实上并不能,我们必须保证的时,右移之后文本串指针不变,所以模式串右移后模式串指针左边的字符必须都是匹配成功的;
0 1 2 3 4 5 6 7 8 9
a a b a a b a a f a // 文本串
a a b a a f // 模式串
a a b a a // 右移1位明显不可以;模式串指针之前的字符并不能和字符串匹配,继续右移看知道模式串指针之前的字符都能匹配上
a a b a // 继续右移
a a b // 模式串指针指向b,b之前的字符都可以匹配上了,所以一共右移3位
a a b a a f // 模式串指针和主串指针继续向前匹配,最终匹配成功
上述例子很好的描述了模式串右移的过程,我们可以看出右移的长度和模式串中匹配失败的字符的位置有关,也一定和之前匹配过的字符有关;和文本串无关;我们依次变化不同匹配失败的位置,看各自要右移的位数;(匹配失败时,尽可能大跨度的右移模式串)
设置不同的匹配失败的字符的位置,记录模式串右移的过程:
0 1 2 3 4 5
a a b a a f
a x // 如果在主串的位置1发生匹配失败后
a x // 右移1位后重新匹配,指针指向0 (x代表匹配失败,指针指向的是模式串当前比较的字符的位置)
a a b a a f
a a x
a a x // 右移1位后重新匹配,指针指向1
a a b a a f
a a b x
a a b x // 右移3位后重新匹配,指针指向0
a a b a a f
a a b a x
a a b a x // 右移3位后重新匹配,指针指向1
a a b a a f
a a b a a x
a a b a a x // 右移3位后重新匹配,指针指向2
a a b a a f
a a b a a f // 匹配成功
上述过程描述了在主串不同位置发生匹配失败时,模式串要右移的不同位数,已经右移后模式串指针指向的位置;我们将模式串指针指向的位置,保存在一个next数组中,每次匹配失败时,就根据next数组中的值对模式串指针进行回退;(next数组就是所谓的前缀表)
我们当然可以手写中退出next数组的值,可是如何将这一推导过程变得更科学?即搞清楚为什么右移,右移多少位的本质;
我们将已匹配的模式串分成几个部分:
0 1 2 3 4 5 6 7 8 9
a a b a a b a a f a // 文本串
a a b a a f // 模式串,模式串指针指向f,正在匹配字符f时匹配失败
[a a] b [a a] f // 模式串,[a a]时已匹配字符串的部分前缀,[a a]也是已匹配字符串的部分后缀
前缀 后缀
0 1 2 3 4 5 6 7 8 9
a a b a a b a a f a // 文本串
[a a] b [a a] f // 模式串在字符f发生不匹配,此时前缀[a a]右移到后缀[a a]位置后继续比较匹配
[a a] b [a a] f // 匹配成功
之所以能向右移,是因为匹配失败的字符的前面的部分和已匹配成功的子串的前面部分有相同的地方,正因为模式串中有这一规律,所以我们才能减少不必要的比较;
在字符"f"匹配失败,那已经匹配成功的子串就是"[a a b a a]",这个子串有一定的规律,我们可以看出前缀中的"[a a]"和后缀中的"[a a]"是一致的,而由于子串是匹配成功的子串,所以前缀"[a a]"和后缀"[a a]"都匹配成功了,所以现在我们将前缀的"[a a]"移动到后缀的"[a a]"的位置,一定是匹配成功的,这也是我们不用从头匹配的原因;
那么寻找右移位数的本质也就呼之欲出了——找到匹配失败的字符前的子串中的最长相同的前缀和后缀的位数;
注意:匹配失败时,找子串的前缀和后缀,子串是不包含匹配失败的字符的子串;
前缀、后缀、最长相同前后缀:
- 字符串的前缀:不包含最后一个字符的所有以第一个字符开头的连续子串。比如字符串
"hello"的前缀包含"h"、"he"、"hel"、"hell"; - 字符串的后缀:不包含第一个字符的所有以最后一个字符结尾的连续子串。比如字符串
"hello"的后缀包含"ello"、"llo"、"lo"、"o"; - 字符串的最长相同前后缀的长度:字符串的最长相同前后缀的长度是指字符串从开头开始的最长相同的前缀和后缀的长度。比如字符串
"abcab"的最长相同前后缀为"ab",其长度为2。
而我们可以看出,这一过程和主串没有任何关系,只是和当前匹配的字符前所有字符组成的子串有关系,我们将整个右移的过程描述如下:
- 匹配成功时:继续往后匹配,模式串指针和文本串指针同步往右;
- 匹配失败时:将模式串中匹配失败的字符左边的所有字符提取出来当成一个子串,将子串中的前缀和后缀最长的相同部分找到,然后右移模式串,让前缀部分右移到和其相同的后缀的位置;
- 移动后模式串指针位置变化:之前模式串指针在后缀的最后一个位置的下一个位置,右移后前缀移动到后缀位置,模式串指针应该在前缀的最后一个字符位置的下一个位置;前缀字符位置从0开始,所以移动后
模式串指针位置 = 前缀长度 = 后缀长度 = 最长相同前后缀长度; - 将不同匹配失败位置得到的模式串指针位置写入next数组(即可得到模式串的前缀表);
0 1 2 3 4 5 6 7 8 9
a a b a a b a a f a // 文本串
[a a] b [a a] f // 模式串,[a a]时已匹配字符串的部分前缀,[a a]也是已匹配字符串的部分后缀
j // 模式串指针j所指位置:子串后缀的下一个字符位置
[a a] b [a a] f // 右移,使得子串前缀移动到原来的后缀位置
j // 右移后,模式串指针j所指位置:子串前缀的下一个字符位置
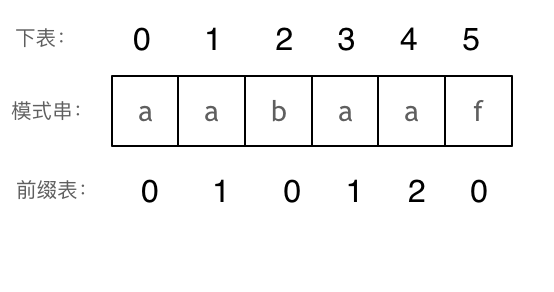
| 子串 | 最长相同前后缀 | 前缀表 | next数组(前缀表减一) |
|---|---|---|---|
| a | 无 | 0 | -1 |
| aa | a | 1 | 0 |
| aab | 无 | 0 | -1 |
| aaba | a | 1 | 0 |
| aabaa | aa | 2 | 1 |
| aabaaf | 无 | 0 | -1 |
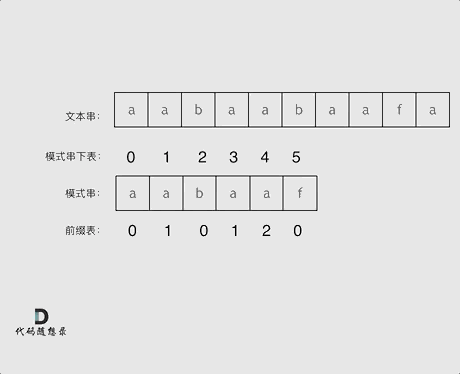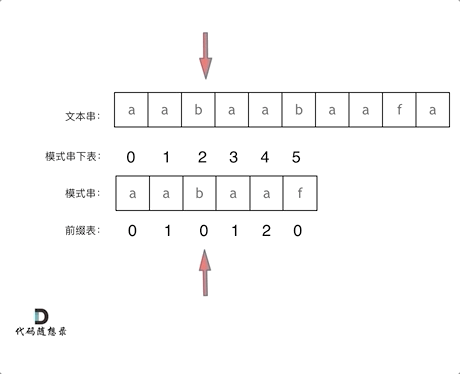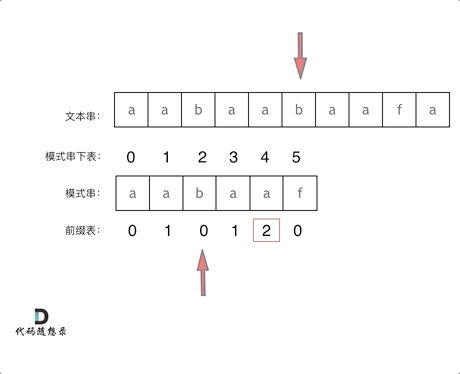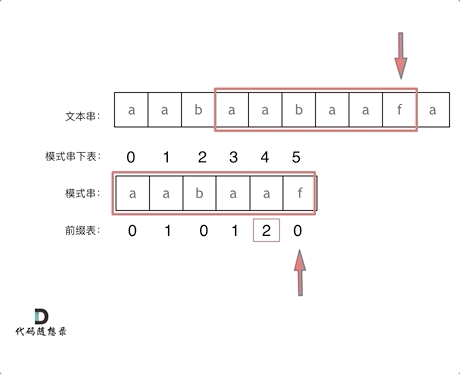
根据next数组就可以实现匹配失败后不一定从头开始匹配,例如:文本串string str = "aabaabaafa",模式串string substr = "aabaaf";
str[5] = 'b',substr[5] = 'f',匹配失败;- 文本串指针不改变,不回溯;
- 模式串指针查找前一个字符(即最后匹配成功的字符)的next数组,
next[4] = 2; - 模式串指针指向2,即
substr[2] = 'b'和str[5] = 'b'继续比较;
next数组就可以是前缀表,但是很多实现都是把前缀表统一减一(右移一位,初始位置为-1)之后作为next数组。
为什么next数组要在最大相同前缀后缀的长度的基础上加一减一?为了在模式串匹配时,当发生不匹配时,可以根据next数组快速移动模式串的指针,从而提高匹配效率。
代码实现思路:
要在子串中找到最大相同前缀和后缀的长度,首先找到相同的前缀和后缀,所以需要两个指针分别指向前缀和后缀的起始位置,然后依次比较两个指针指向的字符是否相同,如果相同,指针继续向右走,相同前缀和后缀长度加1;
a a b a a f
a a b a a x // 子串为a a b a a时
j i // 比较,发现相同,两个指针自增
j i // 相同,自增
j i // i越界,结束
看上去很像是将"[a a b a a]"当成主串,然后将"[a a]"当成模式串进行匹配;(事实上本质就是如此,求next数组的过程和主串模式匹配的过程十分近似)
j指针和i指针从哪开始找?j指针指向前缀,所以可以从开头开始找,i指针指向后缀,由于前缀和后缀的长度要相等,所以后缀的起始位置一定是小于等于子串长度的一半;
a a b a a c
j i
j i
j i // 不相等,都回退
j i // j回退到开头,i从上一次的起点右移1位
j i // 不相等,都回退
j i // 不相等,i到头了,最长前后缀长度为0;
明显整个回退过程感觉很冗余;和之前的模式串匹配一样,能不能利用之前的**“经验”**来优化这一过程;即能不能用之前子串得到的结果来优化当前子串的结果;
a a b a a
j i // 之前的j停在了第二个字符位置
a a b a a f
j i // 继续在之前j停的位置往后匹配(下一个子串的长度增加1,所以已经上一次匹配的后缀后面多了一个字母,现在让j加一,即让前缀也多一个字母,如果此时j和i所指字符相同,则next数组就是比上一个多1即可;
j i // j回退,而i不回退,j和i所指字符不相等
j i // 不相等
// j继续则小于0了,所以aabaaf的最长前后缀长度为0
优化:从上一个子串的j出发,s[i]和s[j + 1]进行比较,如果不等,则j自减,直到j退无可退(s[i]之前的部分和s[j]之前的部分已经在上一个子串中证实已经匹配了);如果相等,则直接让j自增,则最长前后缀长度即前缀长度,即从s[0]到s[j]的长度,即j + 1;
指针i的位置一直不变,就像模式串匹配中,主串的指针不回退,而子串的指针回退;
继续优化,j的回退一定是自减吗?可以利用next数组已经求得的值让回退的步伐变大一点吗?当然可以,以next[j]进行回退;
next[j]的含义:长度为j + 1的子串的最长前后缀,则回退过程:
a a b a a f
j i
// 发现不匹配,则回退,从a a b看,j指向b,即指向子串a a b的最后一个字符,next[j]为0,则退无可退
a a f
a a b // 不匹配,a a b应该相对于a a f右移,右移多少位?看next数组
a a b
a a b
a a b // 如果每次右移1位,类比之前的模式串匹配,匹配失败后右移1位可以优化为右移到next[j]
此时我们越来越发现,找next数组的过程,实际上和模式串匹配的过程太相似了!
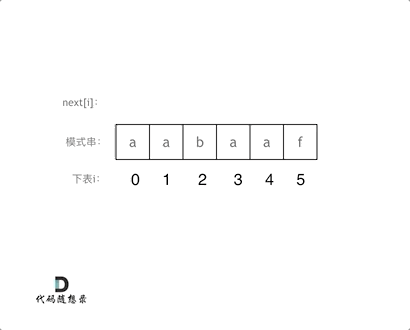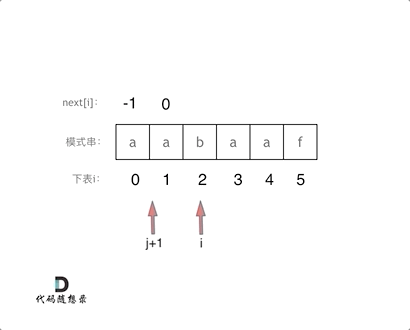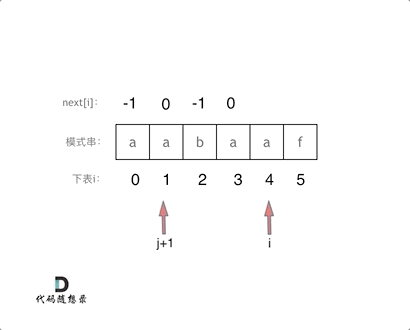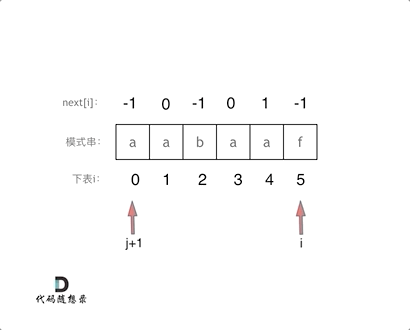
-1 0 1 2 3 4 5
a a b a a f // 模式串
// 为了方便next[0]设置为-1,j初始值为-1(相当于最长前后缀长度减一)
a a
j j+1 i // 循环开始,i = 1,s[j+1] == s[i],匹配成功,j自增然后next[i] = j = next[1] = 0
a a b
j j+1 i // s[i] != s[j+1],则j+1要回退;回退的本质看成子串相对子串右移到next[j](不是next[j+1])
a a b // 主串看成aab
a a // 模式串看成aa,匹配失败,模式串右移,即j = next[j],而next[0] = -1,j回退到尽头,退无可退则更新next[i] = j = next[2] = -1;
a a b a
j j+1 i // s[i] == s[j+1]
j j+1 i // j++且next[i] = j = next[3] = 0
a a b a a
j j+1 i // s[i] == s[j+1]
j j+1 i // j++且next[i] = j = next[4] = 1
a a b a a f
j j+1 i // s[i] != s[j+1]
a a b a a f // 主串
a a b // 模式串,s[i] != s[j+1],模式串右移,令j = next[j] = next[1] = 0
a // s[i] != s[j+1],继续令j = next[0] = -1,j < 0结束,next[i] = next[5] = 0
一旦s[i] != s[j+1],就可以看成模式串s[0] s[1] ... s[j+1]和主串s[0] s[1] ... s[j] ... s[i]不匹配,不匹配时就要右移模式串,而主串指针i不变,即i大小不变,j = next[j],模式串指针变化;
我们不是要从模式串中找到next数组,而这一过程不是只有模式串参与没有主串参与吗?没错,next数组只与模式串本身有关,可是在求解next数组时,我们又将模式串看成主串,将模式串的子串看成模式串(有点绕);所以求解next数组的过程的本质和用next数组进行模式串匹配的本质是一样的!
// 获取模式串的next数组(前缀表减一);(双指针法)
void getNext(int* next, const string& s){
int j = -1; // 前缀表减一作为next数组,j作为模式串指针
next[0] = j;
// 主串指针i(文本串指针i)
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
// 比较i之前的字符组成的子串(不包括i)的前缀和后缀
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同,如果j小于0,则说明退无可退
j = next[j]; // 向前回退
}
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}
// 模式串匹配:
int subStr(string ss, string s) {
if (ss.size() == 0) return 0;
int next[s.size()] = {0};
getNext(next, s); // 获取前缀表
int j = -1; // next数组里记录的起始位置为-1
for (int i = 0; i < ss.size(); i++) {
while (j >= 0 && ss[i] != s[j + 1]) { // 匹配失败回退指针j
j = next[j]; // j回退到next[j]
}
if (ss[i] == s[j + 1]) {
j++; //匹配成功,两个指针同步增加;
}
if (j == (s.size() - 1)) return i - s.size() + 1; // 匹配成功,结束返回
}
}
int main () {
string ss = "aabaabaafa"; // 主串
string s = "aabaaf"; // 模式串
cout << subStr(ss, s) << endl;
int i = 0;
cin >> i; // 暂停看输出,返回3,即匹配到的模式串在主串中的起始位置
}
可以看出模式串匹配和获取next数组在代码实现上也几乎一致!
j代表前缀长度,i代表子串长度;- 当两个指针指向的元素的值相同时:
j + 1和i两个指针都往右走一步,next[i]更新,继续比较; - 当两个指针指向的元素的值不相同时:
j + 1指针往左走到next[j]位置,继续比较,直到j + 1等于0时,说明前缀后缀没有相同部分;
注意j+1回退时,不是回退一步,而是回退到next[j];
时间复杂度分析
若n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n + m)的。
暴力的解法显而易见是O(n × m),所以KMP在字符串匹配中极大地提高了搜索的效率。
但事实上,没有多大优势。KMP算法本质利用模式串自身的规律性,但是在实际情况中,模式串一般没有很多相同前缀,而且模式串一般很短,文本串一般很长,实际应用时和暴力破解的效率差不多。而且使用KMP算法时要维护next数组,反而不如暴力破解用得多;
KMP算法的进一步改进(nextval数组)
之前的前缀和后缀,都指的是真前缀和真后缀:
- 真前缀(Proper Prefix):不包括自身的前缀。
- 真后缀(Proper Suffix):不包括自身的后缀。
即next[i] = next[i] = 最长相同真前缀(相同前缀去掉最后一个字符)和真后缀(相同后缀去掉第一个字符)的长度;
next数组的缺陷:
在next数组构造时,对模式串的最长相同真前缀和真后缀长度进行了减1操作,从而在匹配过程中可能会丢失一些有用的匹配信息。例如模式串"ababc"的next数组为[0, 0, 1, 2, 0],如果文本串为"abababc",在第5个字符发生不匹配,则跳到模式串next[4] = 0 处匹配,即从头开始匹配模式串,之前比较的"abab"要重新比较。
next数组无法有效地解决"后缀重复"的问题。例如,对于模式串"aaaaab",next数组为[0, 1, 2, 3, 4, 0],当发生不匹配时,模式串的指针会回溯到开头,而忽略了已经匹配的"aaaa"这部分信息。
为了解决next数组这一缺陷,引入了nextval数组;
nextval数组的构造方式是,如果存在最长相同真前缀和真后缀,那么nextval[i]就记录它们的长度(包括最后一个字符);否则为0。这样,在匹配过程中,nextval数组可以更好地利用已经匹配的信息,避免重复比较,从而提高匹配效率。
对于上述例子,nextval数组可以更好地处理匹配信息:
- 对于模式串
"ababc",nextval数组为[0, 1, 0, 1, 2],在第5个字符处发生不匹配时,模式串的指针会移动到位置2,从而利用了已经匹配的"ab"这部分信息。 - 对于模式串
"aaaaab",nextval数组为[0, 1, 2, 3, 4, 5],在发生不匹配时,模式串的指针会移动到最后一个字符'b'的位置,从而充分利用了已经匹配的"aaaa"这部分信息。
注意区别,nextval数组看子串时,不包括i位置,即对于模式串"aaaaab",nextval[5]是在"aaaaa"中找前缀和后缀,即找到"aaaaa",所以nextval[5] = 5;
字符串题目示例
| 题目 | 方法 | 思路 | 库函数代替实现 |
|---|---|---|---|
| 反转字符串 | 双指针法 | 字符串本质也是数组,反转字符串的本质就是将数组中的元素掉头,所以用双指针法 | reverse()库函数 |
| 反转字符串II | 双指针法、模拟 | 先模拟分组,然后组内反转字符串,反转字符串用双指针法 | reverse()库函数 |
| 替代数字 | 数组扩容、双指针法 | 根据字符串中数字字符的数量扩容数组,然后用双指针从后往前遍历替换 | |
| 反转字符串里的单词 | 模拟、双指针法、切割字符串 | 去除多余空格后,反转整个字符串,然后根据空格反转每个单词 | 库函数分隔单词后reverse()后相加字符串 |
| 实现substr()函数 | KMP算法 | KMP算法,先getNext()获取next数组,然后进行模式串匹配 | |
| 重复的子字符串 | 移动匹配或者KMP算法 | KMP算法 |
给定一个字符串 s,它包含小写字母和数字字符,请编写一个函数,将字符串中的字母字符保持不变,而将每个数字字符替换为number。
例如,对于输入字符串 "a1b2c3",函数应该将其转换为 "anumberbnumbercnumber"。
对于输入字符串 "a5b",函数应该将其转换为 "anumberb"
输入:一个字符串 s,s 仅包含小写字母和数字字符。
输出:打印一个新的字符串,其中每个数字字符都被替换为了number
最直观的方法是直接新建一个数组,然后遍历旧数组,填充新数组;(字符串的题目一般要求原地算法才有难度)
但更好的方法是数组扩容;
- 首先遍历字符串,获取到字符串中数字的个数,然后就可以计算出转换完成后字符串的长度;
- 扩容原字符串数组(使用resize函数修改字符串长度);
- 设置两个指针,一个指针指向旧字符串的末尾,一个指针指向扩容后字符串的最后一个字符,然后两个指针都从后向前;
- 前面指针指向字母,则后面指针直接赋值字母;然后两个指针都向前;
- 前面指针指向数字,则后面指针向前依次填充number这几个字符,然后前面指针向前走一步;
- 前面指针到达字符串的起点或者两个指针相遇则结束;
数组填充类问题:其做法都是先预先给数组扩容带填充后的大小,然后在从后向前进行操作(一般是双指针法操作)。
给定一个字符串,逐个翻转字符串中的每个单词。(多余空格要去除)
示例 1:
输入: "the sky is blue"
输出: "blue is sky the"
思路:
- 移除多余空格;
- 将整个字符串反转;
- 将每个单词反转;
class Solution {
public:
string reverseWords(string s) {
// 使用双指针
int m = s.size() - 1;
string res;
// 除去尾部空格
while (s[m] == ' ' && m > 0) m--;
int n = m; // n是另一个指针
while (m >= 0) {
while (m >= 0 && s[m] != ' ') m--;
res += s.substr(m + 1, n - m) + " "; // 获取单词并加上空格
while (m >= 0 && s[m] == ' ') m--;
n = m;
}
return res.substr(0, res.size() - 1); // 忽略最后一位的空格
}
};
实现 subStr() 函数。
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例 1: 输入: haystack = "hello", needle = "ll" 输出: 2
示例 2: 输入: haystack = "aaaaa", needle = "bba" 输出: -1
说明: 当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。 对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符
见之前的KMP算法中的代码实现;
给定一个非空的字符串,判断它是否可以由它的一个子串重复多次构成。给定的字符串只含有小写英文字母,并且长度不超过10000。
示例 1:
输入: "abab"
输出: True
解释: 可由子字符串 "ab" 重复两次构成。
三种实现方式:暴力匹配、移动匹配和KMP算法;
暴力匹配:
for循环获取子串的终止位置, 然后判断子串是否能重复构成字符串,又嵌套一个for循环,所以是 O ( n 2 ) O(n^2) O(n2)的时间复杂度。
移动匹配:
当一个字符串s:abcabc,内部由重复的子串组成,那么这个字符串的结构一定是这样的:
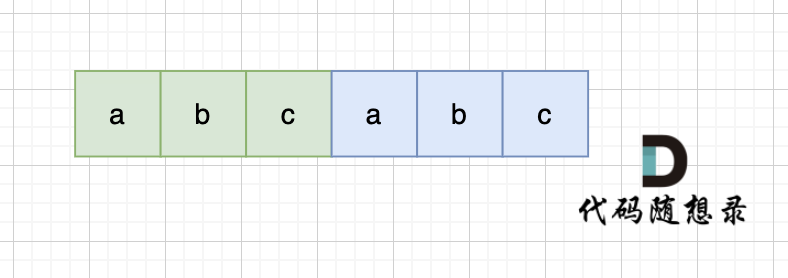
那么既然前面有相同的子串,后面有相同的子串,用 s + s,这样组成的字符串中,后面的子串做前串,前面的子串做后串,就一定还能组成一个s,如图:
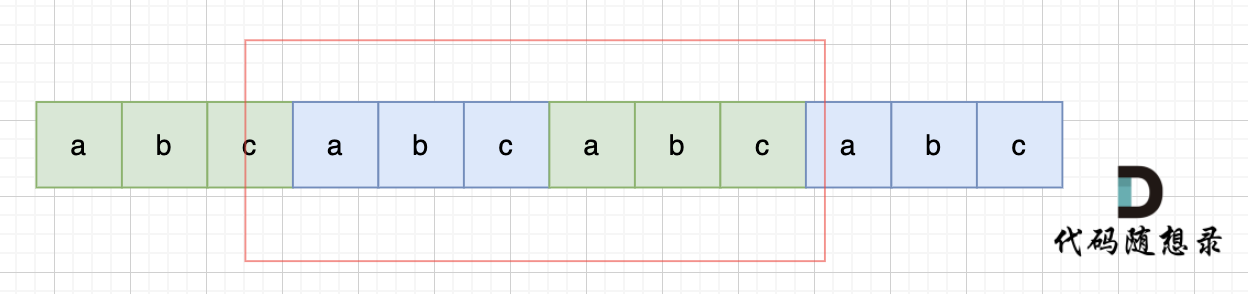
所以判断字符串s是否由重复子串组成,只要两个s拼接在一起,里面还出现一个s的话,就说明是由重复子串组成。
当然,我们在判断 s + s 拼接的字符串里是否出现一个s的的时候,要刨除 s + s 的首字符和尾字符,这样避免在s+s中搜索出原来的s,我们要搜索的是中间拼接出来的s。(拼接后掐头去尾,然后模式串设置为s,进行模式串匹配)
class Solution {
public:
bool repeatedSubstringPattern(string s) {
string t = s + s;
t.erase(t.begin()); t.erase(t.end() - 1); // 掐头去尾
if (t.find(s) != std::string::npos) return true; // r
return false;
}
};
- 时间复杂度: O ( n ) O(n) O(n)
- 空间复杂度: O ( 1 ) O(1) O(1)
不过这种解法还有一个问题,就是 我们最终还是要判断一个字符串(s + s)是否出现过 s 的过程,大家可能直接用contains,find之类的库函数。 却忽略了实现这些函数的时间复杂度(暴力解法是
m
∗
n
m * n
m∗n,一般库函数实现为$ O(m + n)$)。
KMP算法(本质是使用KMP算法中的next数组):
在一个串中查找是否出现过另一个串,这是KMP的看家本领。那么寻找重复子串怎么也涉及到KMP算法了呢?
KMP算法中next数组为什么遇到字符不匹配的时候可以找到上一个匹配过的位置继续匹配,靠的是有计算好的前缀表。 前缀表里,统计了各个位置为终点字符串的最长相同前后缀的长度。
在由重复子串组成的字符串中,最长相等前后缀不包含的子串就是最小重复子串,这里拿字符串s:abababab 来举例,ab就是最小重复单位,如图所示:
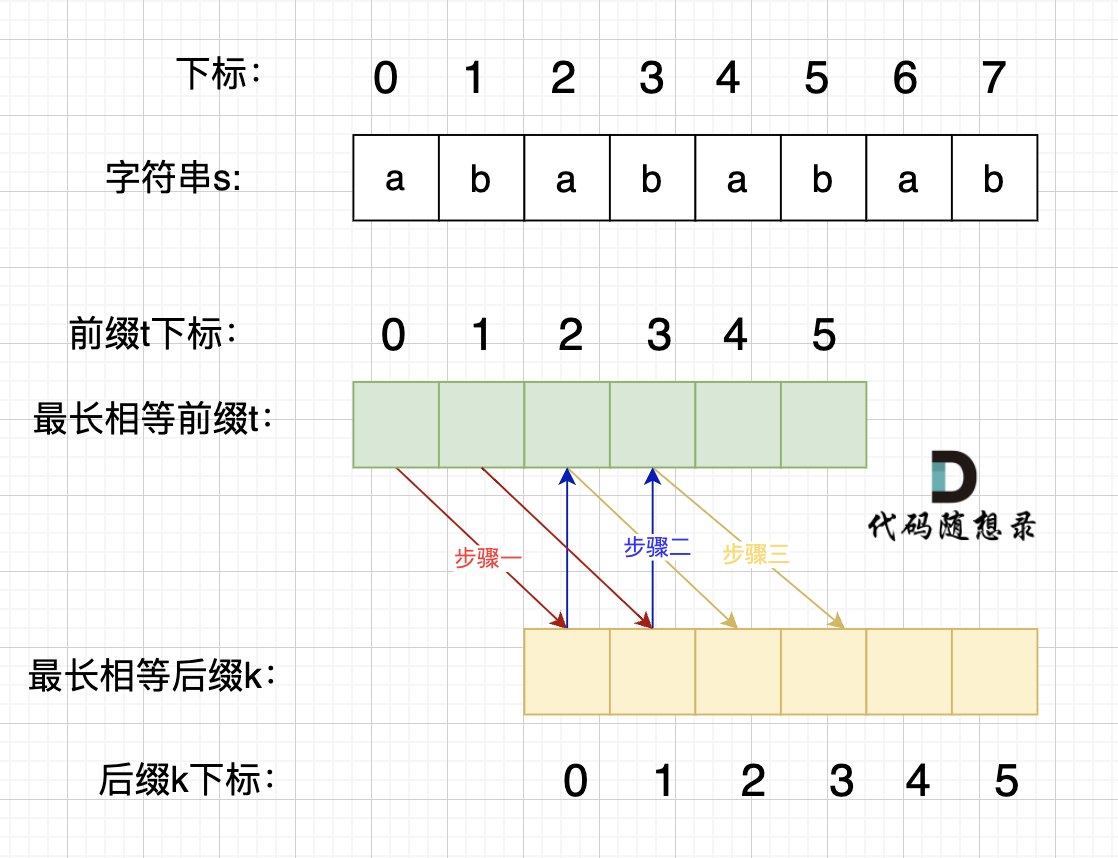
将最长相等前缀看为字符串t,最长相等后缀看为字符串k,则有t和k相同,且:
- 由于
t和k相同,所以:t[0] == k[0],t[1] == k[1]; - 由于
k[0]和t[2]实际上在字符串s中指一个字符,所以k[0] = t[2],同样k[1] = t[3]; - 由于
t和k相同,所以:t[2] == k[2],t[3] == k[3]; - 由于
k[2]和t[4]实际上在字符串s中指一个字符,所以k[2] = t[4],同样k[3] = t[5]; - 由于
t和k相同,所以:t[4] == k[4],t[5] == k[5]; - 综上所述,
k[0] = k[2] = k[4] = t[0] = t[2] = t[4]、k[1] = k[3] = k[5] = t[1] = t[3] = t[5]; - 即:
s[0] = s[2] = s[4]、s[1] = s[3] = s[5],即s由s[0]和s[1]构成;
字符串总结
字符串类类型的题目,往往想法比较简单,但是实现起来并不容易,复杂的字符串题目非常考验对代码的掌控能力。字符串算法一般都要求是原地算法;
双指针法是字符串处理的常客,KMP算法、数组扩容之后的处理,都使用了双指针法;
KMP算法是字符串查找最重要的算法,如何求next数组,以及next数组的原理要清楚;同时KMP算法的思想要知道,用之前的经验来减少比较次数;

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











