






一、网络爬虫基础概念
1. 爬虫的工作流程
- 发送请求:通过 HTTP 协议向目标网站发送请求
- 获取响应:接收服务器返回的 HTML、JSON 等数据
- 解析数据:从响应中提取需要的信息
- 存储数据:将提取的数据保存到文件或数据库
- 循环抓取:根据链接结构爬取更多页面
2. 爬虫的应用场景
- 数据采集(价格监控、舆情分析)
- 搜索引擎索引
- 社交媒体分析
- 学术研究(文献、统计数据)
二、核心库与框架
1. Requests 库 - HTTP 请求
Requests 库以简洁易用著称,能轻松构造各种 HTTP 请求。例如,获取网页内容只需一行代码response = requests.get('https://example.com');发送POST请求提交表单数据时,通过requests.post(url, data=payload),将表单数据以字典形式传入data参数即可。同时,还能灵活设置请求头、超时时间等参数,满足复杂的网络请求需求。

2. BeautifulSoup - HTML 解析
BeautifulSoup 将 HTML 文档解析成树形结构,方便通过标签名、类名、ID 等属性查找元素。如 soup.find('div', class_='article')可找到页面中 class 为article的div标签;soup.select('p a')能选中所有p标签内的a标签。相比正则表达式,它对不规范的 HTML 结构有更好的兼容性,在解析复杂网页时优势明显

3. 正则表达式 - 高级文本匹配(回顾)
正则表达式通过特殊字符和模式组合,实现强大的文本匹配功能。例如,\d{4}-\d{2}-\d{2}可精准匹配日期格式;https?://[^\s]+用于提取网页中的 URL。在爬虫中,常用于从 HTML 源代码中提取特定标签内的内容,或是从 JavaScript 代码里获取隐藏的数据信息,但编写复杂正则时需格外小心,避免出现匹配错误或性能问题。

4. Scrapy 框架 - 高效爬虫
Scrapy 是专业的爬虫框架,具备高效的异步请求处理、自动调度请求队列等特性。通过定义 Item、Spider、Pipeline 等组件,可实现数据提取、清洗、存储的全流程管理。比如,在电商爬虫项目中,利用 Scrapy 快速抓取商品详情页,自动处理分页,同时通过 Pipeline 将数据存入数据库或文件,大幅提升开发效率
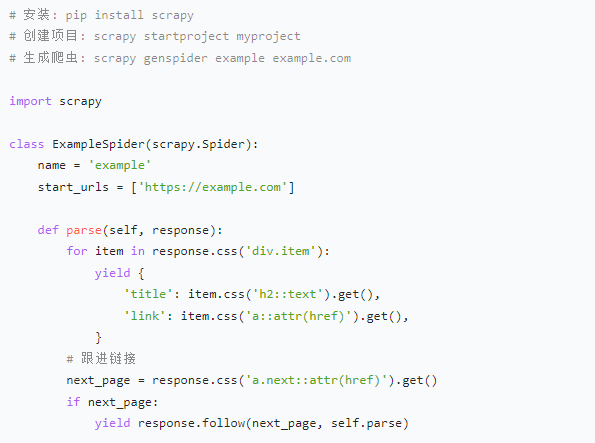
5. Selenium - 动态页面处理
对于依赖 JavaScript 动态渲染的页面,Selenium 模拟浏览器操作,驱动真实浏览器(如 Chrome、Firefox)加载页面。例如,自动登录网站时,使用driver.find_element_by_id('username').send_keys('your_username')输入用户名,driver.find_element_by_id('password').send_keys('your_password')输入密码,driver.find_element_by_id('login_button').click()模拟点击登录按钮,从而获取动态加载后的页面数据。

三、爬虫实战技巧
1. 处理反爬机制
- 设置请求头:模拟浏览器访问
网站常通过识别请求头中的User-Agent判断访问来源,将爬虫的User-Agent设置为常见浏览器标识,如Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36,可伪装成浏览器访问,降低被识别为爬虫的风险。

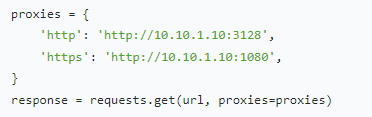
IP 代理池:轮换 IP 避免封禁
当爬虫频繁访问同一网站时,IP 可能被封禁。使用 IP 代理池,定期更换 IP 地址,如从代理 IP 服务商获取一批代理 IP,随机选取使用,保持爬虫的正常访问。
控制爬取频率:添加随机延时
设置合理的请求间隔,避免短时间内大量请求给服务器造成压力。可使用time.sleep(random.uniform(1, 3))在每次请求后随机等待 1 - 3 秒,模拟人类正常访问行为。

2. 动态内容处理
- AJAX 请求分析:通过浏览器开发者工具的网络面板,找到页面动态加载数据的 AJAX 接口,直接发送请求获取 JSON 格式数据,比解析 HTML 更高效。例如,微博的用户动态通过 AJAX 加载,找到对应接口后,可直接获取动态内容、评论等信息
- 无头浏览器:Selenium 和 Playwright 支持无头模式,无需可视化界面即可运行浏览器,在后台渲染页面,快速获取动态数据,同时减少资源占用。
- 逆向工程:部分网站对请求参数进行加密处理,如登录密码加密。通过分析 JavaScript 代码,逆向破解加密算法,在爬虫中模拟加密过程,正确构造请求参数。
3. 数据存储
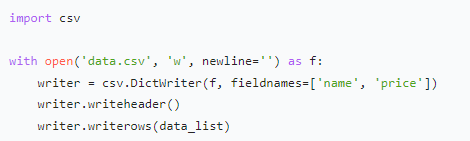
- CSV 文件:适合存储结构化数据,如表格形式的商品信息。使用 Python 的
csv模块,可轻松写入数据,且 CSV 文件能被 Excel 等软件直接打开,方便数据查看和初步分析。
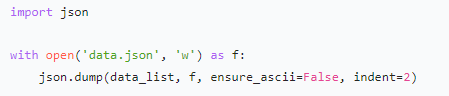
JSON 文件:对数据格式要求灵活,常用于存储非结构化或半结构化数据,如新闻文章的标题、正文、发布时间等信息。其格式简洁,便于在不同系统间传输和解析。
数据库:MySQL 等关系型数据库适合存储结构化强、有复杂关联关系的数据;MongoDB 等非关系型数据库则对数据格式限制少,适合存储大量非结构化数据,且具有良好的扩展性和读写性能。
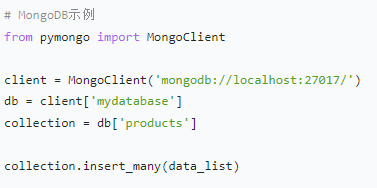
四、高级爬虫技术
1. 分布式爬虫
- Scrapy-Redis:基于 Redis 的分布式爬虫框架
- 多进程 / 多线程:提高爬取效率

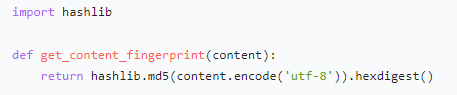
2. 增量式爬虫
- 记录已爬取的 URL 和内容指纹(如 MD5 哈希)
- 只处理新增或更新的内容
3. 爬虫监控与日志
- 记录爬取状态、错误信息
- 监控爬取速度和数据质量

五、法律与道德准则
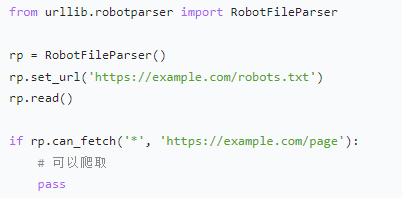
-
遵守 robots.txt:检查网站允许的爬取范围
2.数据使用限制:
- 不爬取敏感信息(如用户隐私)
- 遵守网站条款和版权法律
- 合理使用数据(不用于商业竞争)
3.爬虫理论:
- 控制爬取频率,避免影响网站正常运行
- 公开爬虫身份(通过 User-Agent)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









