





神经网络可由torch.nn包构建。
在粗略地了解了自动求导后,现在可以理解通过自动求导来定义模型和对其求导的nn了。nn.Module包括图层,和返回output的forward(input)方法。
举个例子,下图是一个分类数字图像的神经网络:

它是一个简单的前馈网络。它获得一个输入,并将其一个接一个的穿过数个图层,并最终得到输出。
一个典型的神经网络处理流程如下:
- 定义一个有学习参数(或权重)的神经网络。
- 迭代地输入数据集
- 使用神经网络处理输入
- 计算损失(输出距离正确值的距离)
- 将梯度传递回神经网络的参数
- 更新神经网络的权重,一般使用一个简单的更新规则:weight = weight - learning_rate * gradienr。
Define the network
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
## 此处super指代nn.module
super(Net,self).__init__()
## 三个参数分别为输入图像的通道数,输出通道数以及正方形卷积的边长
self.conv1 = nn.Conv2d(1,6,3)
self.conv2 = nn.Conv2d(6,16,3)
## 建立仿射函数 y = Wx + b
## 两个参数分别为该层神经网络的输入参数数和输出参数数
## fc即full connection,全连接层,即神经网络中除输入层之外的每个节点都和上一层的所有节点有连接
## 关于Linear,见 https://blog.csdn.net/m0_37586991/article/details/87861418
self.fc1 = nn.Linear(16 * 6 * 6,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
## 通过(2,2)的窗口进行最大池化
x = F.max_pool2d(F.relu(self.conv1(x)),(2,2))
## 当窗口为正方形时,参数可以为一个数
x = F.max_pool2d(F.relu(self.conv2(x)),2)
## 将x拍扁为一维向量,以传入fc1,num_flat_features为元素数量
x = x.view(-1,self.num_flat_feature(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self,x):
size = x.size()[1:]
print(x.size())
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
结果为:

你只需要定义前向传播的函数,而后向传播函数(用来计算梯度)在使用自动求导时会自动定义。你可以在前向传播函数里使用任何张量操作。
模型的学习参数通过net.parameters()传回:
params = list(net.parameters())
print(len(params))
print(params[0].size())
结果为:
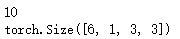
我们也可以尝试下随机的32×32的输入。注意,该神经网络(LeNet)的输入大小为32×32.如果要把它应用到MNIST数据集上,则要把图片的大小转化为32×32.
input = torch.randn(1,1,32,32)
out = net(input)
print(out)
结果为:

使用随机梯度将所有参数和反向的梯度缓冲区归零:
net.zero_grad()
out.backward(torch.randn(1,10))
Note:
torch.nn仅支持小批量。整个torch.nn包仅支持小批量样本的输入,而不是单个样本。例如,nn.Conv2d可以将4D张量(nSamples × nChannels × Height × Width).
如果你有一个单个样本,使用input.unsqueeze(0)来添加虚假的批维度。
在前进得更远前,让我们先概括一下目前出现过的所有类。
recap:
- torch.Tensor: 一个支持像backward()这样的自动求导操作的多维数组。且保留关于张量的梯度。
- nn.Module: 神经网络模块。方便的封装参数的方法,包含将神经网络移动到GPU,及对其进行输出,加载等操作。
- nn.Parameter: 一种张量,当被指定为模型的属性时自动作为参数被注册。
- autograd.Function: 实现自动编程操作的前向和后向定义。每个Tensor操作都至少会创建一个Function节点,该节点连接至创建张量和编码其历史的函数。
目前我们已经了解了:
- 定义神经网络。
- 处理输入数据及调用后向传播。
仍需了解:
- 计算损失。
- 更新神经网络的权重。
Loss Function
损失函数将(output,target)作为输入,并计算二者之间的距离。
nn包里有很多种损失函数。一种简单的损失函数为:nn.MSELose,它计算输出和目标间的均方误差。
例如:
output = net(input)
target = torch.randn(10)
target = target.view(1,-1)
criterion = nn.MSELoss()
loss = criterion(output,target)
print(loss)
结果为:
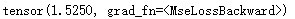
现在,如果你在后向方向上跟随损失,使用它的.grad_fn属性,你将会看到如下的计算图:

所以,当我们调用loss.backward()时,整个计算图都关于损失求导,且所有计算图中requires_grad为True的张量将会使它们的.grad张量累积梯度。
为了说明白,我们进行以下步骤:
print(loss.grad_fn)
print(loss.grad_fn.next_functions[0][0])
print(loss.grad_fn.next_functions[0][0].next_funtions[0][0])
结果为:
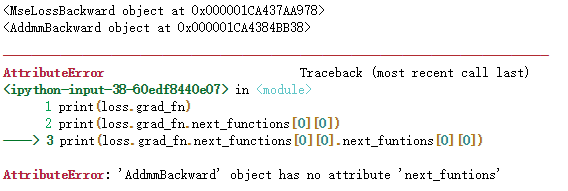
(注:未搜到该问题的答案,初步认为是PyTorch1.1版本中该属性做了改变,但教程中还未修改。)
Backprop
我们只需要使用loss.backward()就可以后向传播该错误。你需要清除现有梯度,否则梯度将会累积到现存梯度。
现在我们可以调用loss.backward(),且观察在后向传播前后conv1的偏差梯度。
net.zero_grad()
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
结果为:

Update the weights
实践中最简单的更新方法为随机梯度下降法(Stochastic Gradient Descent,SGD)。

我们可以使用简单的python代码来应用它:
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
然而,当你使用神经网络时,你可能想要使用很多种不同的更新规则,如SGD,Nesterov-SGD,Adam,RMSProp等。为了达到这个目标,我们构建了一个简单的包:torch.optim,用来实现以上所有的规则。它用起来非常简单:
import torch.optim as optim
optimizer = optim.SGD(net.parameters(),lr=0.01)
optimizer.zero_grad()
output = net(input)
loss = criterion(output,target)
loss.backward()
## 进行更新
optimizer.step()
Note:
观察到梯度缓冲区必须使用optimizer.zero_grad()手动置零。这是因为梯度会累积——如Backprop节解释的那样。















 6099
6099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









