







前两篇讲清楚基础和基本api调用,接下来我们就是要进入优化篇章了。
本系列:
(1)SSM框架构建积分系统和基本商品检索系统(Spring+SpringMVC+MyBatis+Lucene+Redis+MAVEN)(1)框架整合构建
(2)SSM框架构建积分系统和基本商品检索系统(Spring+SpringMVC+MyBatis+Lucene+Redis+MAVEN)(2)建立商品数据库和Lucene的搭建
(3)Redis系列(一)–安装、helloworld以及读懂配置文件
(4)Redis系列(二)–缓存设计(整表缓存以及排行榜缓存方案实现)
(5) Lucene总结系列(一)–认识、helloworld以及基本的api操作。
(6)Lucene总结系列(二)–商品检索系统的文字检索业务(lucene项目使用)
文章结构:
(1)总述优化方案;
(2)呈现实时内存目录索引(结合源码解析);
一、总述优化方案:
(1)索引创建优化:
1. 先将索引写入RAMDirectory,再批量写 入FSDirectory
不管怎样,目的都是尽量少的文件IO,因为创建索引的最大瓶颈在于磁盘IO。
2. 通过设置IndexWriter的参数优化索引建立
IndexWriter的forceMerge方法。当小文件达到多少个时,就自动合并多个小文件为一个大文件,因为它的使用代价较高不意见使用此方法,默认情况下lucene会自己合并。合并cfs文件。比如设定10,就是当小文件达到10个就自动合并成一个索引cfs文件。(而且只能在close前一步使用)
打开 IndexWriter 的时候,设置 autoCommit = false同传统的数据库操作一样,批量提交事务性能总是比每个操作一个事务的性能能好很多。
3.在建立索引过程中,使用单例的 IndexWriter基于内存执行 Flush 而不是基于 document count–也就是内存消耗flush代替文档数量flush。
indexWriter可以自动根据内存消耗调用flush()。可以使用indexWriterConfig.setRAMBufferSizeMB(double)设置缓冲区大小。测试表明48MB为叫合适值。
4. 重用Document和Field。
创建Document单一实例,使用Field的setValue方法重用Field。而通过 setValue 实现,这将有助于更有效的减少GC开销而改善性能。
5.创建单例的IndexWriter。
6.关闭复合文件格式(Compound file format)调用setUseCompoundFile(false),可以关闭。
建立复合文件,将可能使得索引建立时间被拉长,有可能达到7%-33%。而关闭复合文件格式,将可能大大增加文件数量,而由于减少了文件合并操作,索引性能被明显增强。
7.不要使用太多的小字段
如果字段过多,尝试将字段合并到一个更大的字段中,以便于查询和索引适当增加 mergeFactor,但是不要增加的太多。关闭所有不需要的特性使用更快的 Analyzer特别是对于中文分词而言,分词器对于性能的影响更加明显。
(2)搜索索引时优化:
1. 建立实时内存索引,将索引放入内存(注意:针对数量小型的索引,当索引大于1G就要考虑分布式索引了)
通过RAMDirectory内存读写缓写提高性能
2. 合适使用api选择适合的范围索引:
[一]RangeQuery范围搜索。
设置范围,但是RangeQuery的实现实际上是将时间范围内的时间点展开,组成一个个BooleanClause加入 到 BooleanQuery中查询,因此时间范围不可能设置太大,经测试,范围超过一个月就会抛 BooleanQuery.TooManyClauses,可以通过设 置 BooleanQuery.setMaxClauseCount(int maxClauseCount)扩大,但是扩大也是有限的,并且随着 maxClauseCount扩大,占用内存也扩大。
[二]RangeFilter替代。
用RangeFilter代替RangeQuery,经测试速度不会比RangeQuery慢,但是仍然有性能瓶颈,查询的90%以上时间耗费在 RangeFilter,研究其源码发现RangeFilter实际上是首先遍历所有索引,生成一个BitSet,标记每个document,在时间范围内的标记为true,不在的标记为false,然后将结果传递给Searcher查找,这是十分耗时的。
针对Filter再进一步的优化:
**[1]**缓存Filter结果。
既然RangeFilter的执行是在搜索之前,那么它的输入都是一定的,就是IndexReader, 而 IndexReader是由Directory决定的,所以可以认为RangeFilter的结果是由范围的上下限决定的,也就是由具体 的 RangeFilter对象决定,所以我们只要以RangeFilter对象为键,将filter结果BitSet缓存起来即可。 lucene API已经提供了一个CachingWrapperFilter类封装了Filter及其结果,所以具体实施起来我们可以 cache CachingWrapperFilter对象,需要注意的是,不要被CachingWrapperFilter的名字及其说明误 导, CachingWrapperFilter看起来是有缓存功能,但的缓存是针对同一个filter的,也就是在你用同一个filter过滤不 同 IndexReader时,它可以帮你缓存不同IndexReader的结果,而我们的需求恰恰相反,我们是用不同filter过滤同一 个 IndexReader,所以只能把它作为一个封装类。
**[2]**降低时间精度。
研究Filter的工作原理可以看出,它每次工作都是遍历整个索引的,所以时间粒度越大,对比越快,搜索时间越短,在不影响功能的情况下,时间精度越低越好,有时甚至牺牲一点精度也值得,当然最好的情况是根本不作时间限制。
针对上面的优化例子:
第一组,时间精度为秒:方式 直接用RangeFilter 使用cache 不用filter 。平均每个线程耗时 10s 1s 300ms
第二组,时间精度为天:方式 直接用RangeFilter 使用cache 不用filter。平均每个线程耗时 900ms 360ms 300ms。
所以:
尽量降低时间精度,将精度由秒换成天带来的性能提高甚至比使用cache还好,最好不使用filter。
在不能降低时间精度的情况下,使用cache能带了10倍左右的性能提高。
3.IndexSearcher单例化。
(3)其余零散的优化点:
1. 使用最新版本的Lucene。
使用本地文件系统(尽量不使用虚拟机),使用更快的硬件设备,尤其是SSD。
2. 使用更快的分析器。
主要是对磁盘空间的优化,可以将索引文件减小将近一半,相同测试数据下由600M减少到380M。但是对时间并没有什么帮助,甚至会需要更长时 间,因为较好的分析器需要匹配词库,会消耗更多cpu
3. 关键词区分大小写。
or AND TO等关键词是区分大小写的,lucene只认大写的,小写的当做普通单词。
4.设置boost。
有些时候在搜索时某个字段的权重需要大一些,例如你可能认为标题中出现关键词的文章比正文中出现关键词的文章更有价值,你可以把标题的boost设置的更大,那么搜索结果会优先显示标题中出现关键词的文章(没有使用排序的前题下)。使用方法:Field. setBoost(float boost);默认值是1.0,也就是说要增加权重的需要设置得比1大。
部分参考
方案大致列举这些,然后后面的文章会以这个为根结点不断去扩散的,并且结合源码解读下进一步的优化方案。
二、呈现实时内存索引(结合源码解析):
(1)代码实现以及优化效果展示:
第一次索引平均时间(无内存索引)

第一次索引后平均时间(无内存索引)
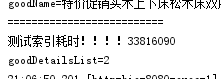
第一次索引平均时间(建立内存索引)。
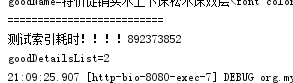
第一次索引后平均时间(建立内存索引)。比无内存快一倍多。
//查看我们demo工程的LuceneUtil类
static {
try {
directory_sp = FSDirectory.open(new File(Constant.INDEXURL_ALL));
matchVersion = Version.LUCENE_44;
analyzer = new IKAnalyzer();
config = new IndexWriterConfig(matchVersion, analyzer);
System.out.println("directory_sp " + directory_sp);
// 创建内存索引库,让硬盘的库交给内存库
ramDirectory = new RAMDirectory(directory_sp, null);
} catch (IOException e) {
e.printStackTrace();
}
}
public static IndexSearcher getIndexSearcherOfSP() throws IOException {
System.out.println("directory_sp " + directory_sp);
//打开的是内存库
IndexReader indexReader = DirectoryReader.open(ramDirectory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
return indexSearcher;
}
(2)源码分析:
RAMDirectory类是一个驻留内存的(memory-resident)Directory抽象类的实现。
public class RAMDirectory extends Directory {
/**
* 存放了一个fileName 和 RAMFile的键值对。
*/
protected final Map<String, RAMFile> fileMap;
protected final AtomicLong sizeInBytes;//jdk1.8才有的
/*
初始化时:
LockFactory抽象类的一个具体实现类SingleInstanceLockFactory。SingleInstanceLockFactory类的特点是,所有的加锁操作必须通过该SingleInstanceLockFactory的一个实例而发生,也就是说,在进行加锁操作的时候,必须获取到这个SingleInstanceLockFactory的实例。
*/
public RAMDirectory() {
this.fileMap = new ConcurrentHashMap();//线程安全
this.sizeInBytes = new AtomicLong();
try {
//实际上,在获取到一个SingleInstanceLockFactory的实例后,那么对该目录Directory进行的所有的锁都已经获取到,这些锁都被存放到SingleInstanceLockFactory类定义的locks中。
this.setLockFactory(new SingleInstanceLockFactory());
} catch (IOException var2) {
;
}
}
/*
* 仅仅当硬盘中的索引能全部放入内存中的时候才能调用此方法,它会将所有的现有Index放入到内存中来。。也就是索引比较小的时候才用的方案。大概小于1G。否则得话将会发生OOM的异常。
* 通过这种方法得到的RAMDirectory对象是一个独立于以前的directory对象的新的索引对象
* 对于以前的Directory对象的任何修改都不会对新的RAMDirectory对象造成影响
* 因为新的对象中包含所有的已有index的文件信息
*/
public RAMDirectory(Directory dir, IOContext context) throws IOException {
this(dir, false, context);
}
private RAMDirectory(Directory dir, boolean closeDir, IOContext context) throws IOException {
this();//先初始化fileMap,并加锁
String[] arr$ = dir.listAll();//存放索引名字
int len$ = arr$.length;
for(int i$ = 0; i$ < len$; ++i$) {
String file = arr$[i$];
dir.copy(this, file, file, context);//把索引copy一份给本实例变量,也就是RAMDirectory,从而实现内存目录索引
}
if(closeDir) {
dir.close();//然后?把Directory给关了,以后用内存目录索引。
}
}
//列出内存中所有的文件信息
public final String[] listAll() {
this.ensureOpen();
Set<String> fileNames = this.fileMap.keySet();
List<String> names = new ArrayList(fileNames.size());
Iterator i$ = fileNames.iterator();
while(i$.hasNext()) {
String name = (String)i$.next();
names.add(name);
}
return (String[])names.toArray(new String[names.size()]);
}
//判断内存目录中是否存在我们想查的filename
public final boolean fileExists(String name) {
this.ensureOpen();
return this.fileMap.containsKey(name);
}
//其实操作的是内存上的File对象,也就是RAMFile
public final long fileLength(String name) throws IOException {
this.ensureOpen();
RAMFile file = (RAMFile)this.fileMap.get(name);
if(file == null) {
throw new FileNotFoundException(name);
} else {
return file.getLength();
}
}
public final long sizeInBytes() {
this.ensureOpen();
return this.sizeInBytes.get();
}
// 从当前集合中删除名为name的文件对象
public void deleteFile(String name) throws IOException {
this.ensureOpen();
RAMFile file = (RAMFile)this.fileMap.remove(name);
if(file != null) {
file.directory = null;
this.sizeInBytes.addAndGet(-file.sizeInBytes);
} else {
throw new FileNotFoundException(name);
}
}
/**
* 创建一个新的文件RAMFile
* 如果Directory中已经存在一个当前Name的File,
* 则删除现有的这个File,将新的File加入到Directory中来.
这个函数是创建一个名称为name的输出流。这里牵扯到一个RAMFile对象和RAMOutputStream对象。RAMFile对象就是在内存中维护一个当前file信息的对象.
RAMFile ---内存中组织的一个File对象 ,实际上是一个byte[]的数组链表。
*/
public IndexOutput createOutput(String name, IOContext context) throws IOException {
this.ensureOpen();
RAMFile file = this.newRAMFile();
RAMFile existing = (RAMFile)this.fileMap.remove(name);
/**
* 加入一个File对象已经存在,需要将原有的那个从集合中排除掉
* 但是它所对应的相关信息没有消失
* 由于没有其它对象引用这个排除掉的File对象,因此它很快会被GC回收掉
*/
if(existing != null) {
this.sizeInBytes.addAndGet(-existing.sizeInBytes);
//这个地方需要将existing中引用的directory对象置为空
existing.directory = null;
}
this.fileMap.put(name, file);
return new RAMOutputStream(file);
}
protected RAMFile newRAMFile() {
return new RAMFile(this);
}
public void sync(Collection<String> names) throws IOException {
}
//打开一个input流对象
public IndexInput openInput(String name, IOContext context) throws IOException {
this.ensureOpen();
RAMFile file = (RAMFile)this.fileMap.get(name);
if(file == null) {
throw new FileNotFoundException(name);
} else {
return new RAMInputStream(name, file);
}
}
//关闭内存目录操作
public void close() {
this.isOpen = false;
this.fileMap.clear();
}
}
在并发状态下,管理锁资源的关键点就在SingleInstanceLockFactory 类
/*
因此,多个线程要进行加锁操作的时候,需要考虑同步问题。这主要是在获取SingleInstanceLockFactory中的SingleInstanceLock的时候,同步多个线程,包括请求加锁、释放锁,以及与此相关的共享变量。
*/
public class SingleInstanceLockFactory extends LockFactory {
private HashSet<String> locks = new HashSet();
public SingleInstanceLockFactory() {
}
public Lock makeLock(String lockName) {
//从锁工厂中, 根据指定的锁lockName返回一个SingleInstanceLock实例
return new SingleInstanceLock(this.locks, lockName);
}
public void clearLock(String lockName) throws IOException {
HashSet var2 = this.locks;
synchronized(this.locks) { // 从SingleInstanceLockFactory中清除某个锁的时候,需要同步
if(this.locks.contains(lockName)) {
this.locks.remove(lockName);
}
}
}
}
RAMFile —内存中组织的一个File对象 ,实际上是一个byte[]的数组链表。用这个对象去操作内存中的目录。
public class RAMFile {
//buffers 保存了File对象中的所有数据信息。RAMOutputStream和RAMInputStream都是对这个buffers对象进行操作。
protected ArrayList<byte[]> buffers = new ArrayList();
long length;
RAMDirectory directory;
protected long sizeInBytes;
public RAMFile() {
}
RAMFile(RAMDirectory directory) {
this.directory = directory;
}
//得到File长度
public synchronized long getLength() {
return this.length;
}
protected synchronized void setLength(long length) {
this.length = length;
}
//扩容Buffer
protected final byte[] addBuffer(int size) {
byte[] buffer = this.newBuffer(size);
synchronized(this) {
this.buffers.add(buffer);
this.sizeInBytes += (long)size;
}
if(this.directory != null) {
this.directory.sizeInBytes.getAndAdd((long)size);
}
return buffer;
}
//得到这个字节流对象
protected final synchronized byte[] getBuffer(int index) {
return (byte[])this.buffers.get(index);
}
protected final synchronized int numBuffers() {
return this.buffers.size();
}
protected byte[] newBuffer(int size) {
return new byte[size];
}
public synchronized long getSizeInBytes() {
return this.sizeInBytes;
}
}
源码下载:Lucene总结系列Demo
好了,Lucene总结系列(三)–总述优化方案和呈现实时内存目录索引讲完了
这是项目过程中针对lucene的优化思路,现在一一罗列给大家,并用这一系列的文章结合源码去深入讲解这些优化思路,这是积累的必经一步,我会继续出这个系列文章,分享经验给大家。欢迎在下面指出错误,共同学习!!你的点赞是对我最好的支持!!














 5344
5344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









