






 当进行tensort加速的cmake编译时遇到zlibwapi.dll缺失的问题,可以按照以下步骤解决:从指定链接下载zlibwapi.dll,解压后将dll文件复制到CUDA的bin目录,将lib文件复制到CUDA的lib目录。这样可以修复编译错误。
当进行tensort加速的cmake编译时遇到zlibwapi.dll缺失的问题,可以按照以下步骤解决:从指定链接下载zlibwapi.dll,解压后将dll文件复制到CUDA的bin目录,将lib文件复制到CUDA的lib目录。这样可以修复编译错误。
进行tensort加速,cmake编译失败,缺少zlibwapi.dll文件,解决详细步骤:
1. 下载zlibwapi.dll,下载地址:www.winimage.com/zLibDII/
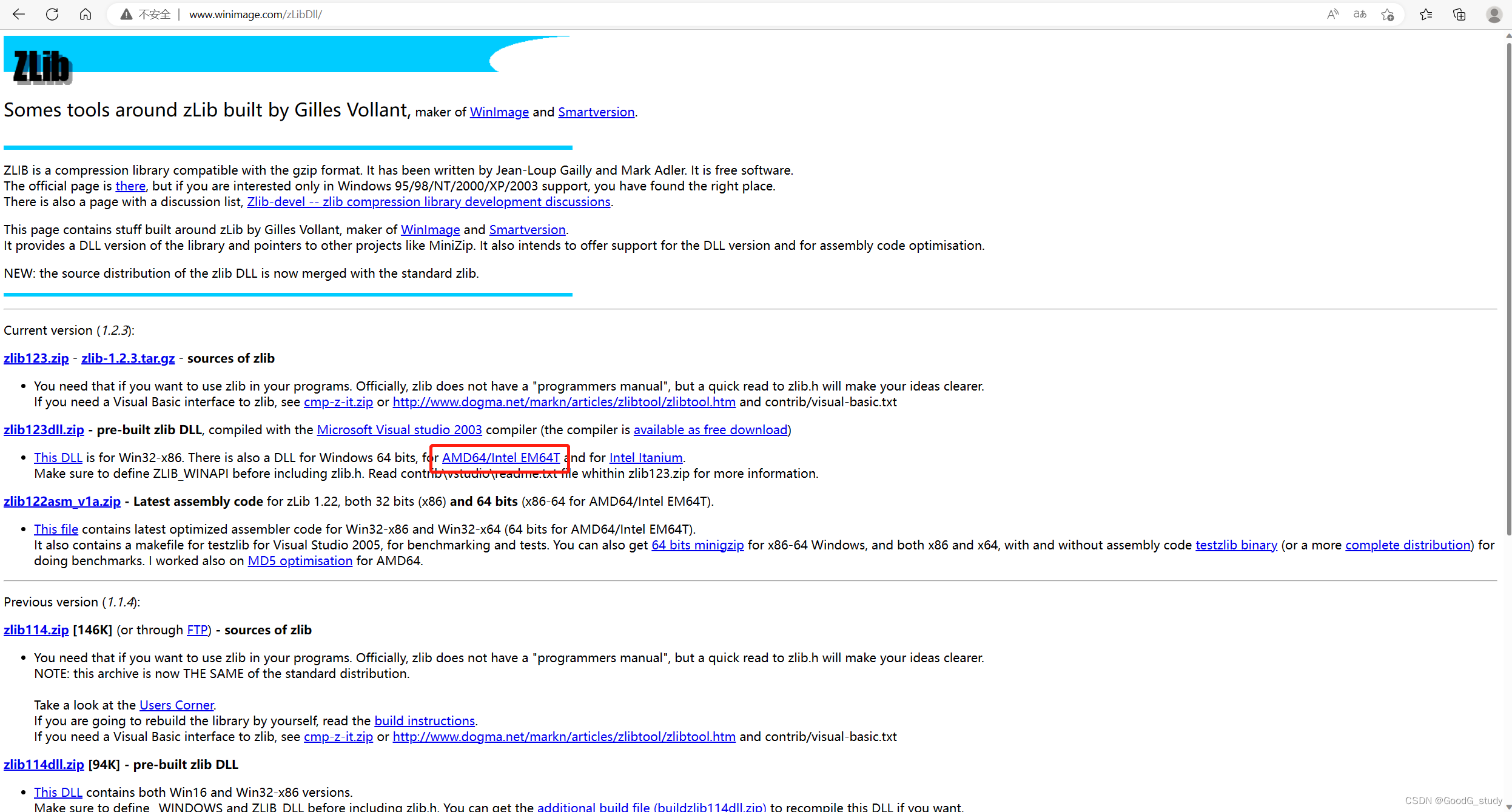
( zlibwapi.dll资源:链接:https://pan.baidu.com/s/1oLVRk6XL40iNIqRzKEkLyQ
提取码:1111
)
2. 解压下载好的文件
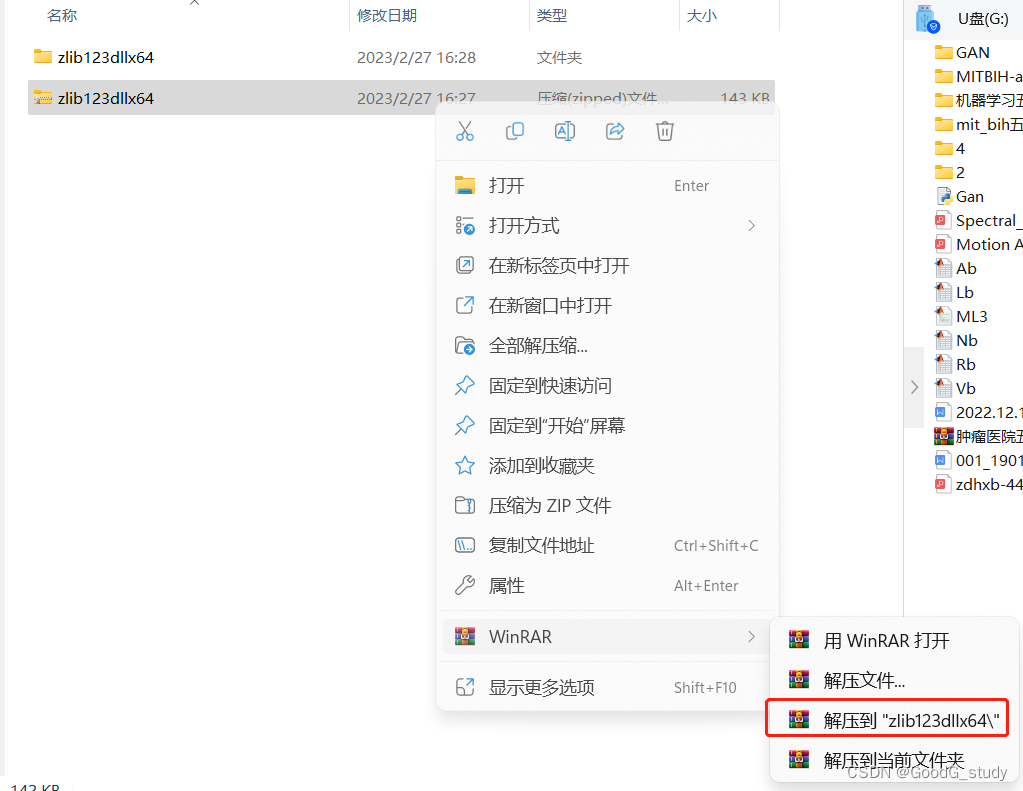
3. 进入文件.\zlib123dllx64\dll_x64,将文件夹下的zlibwapi.dII复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin目录下
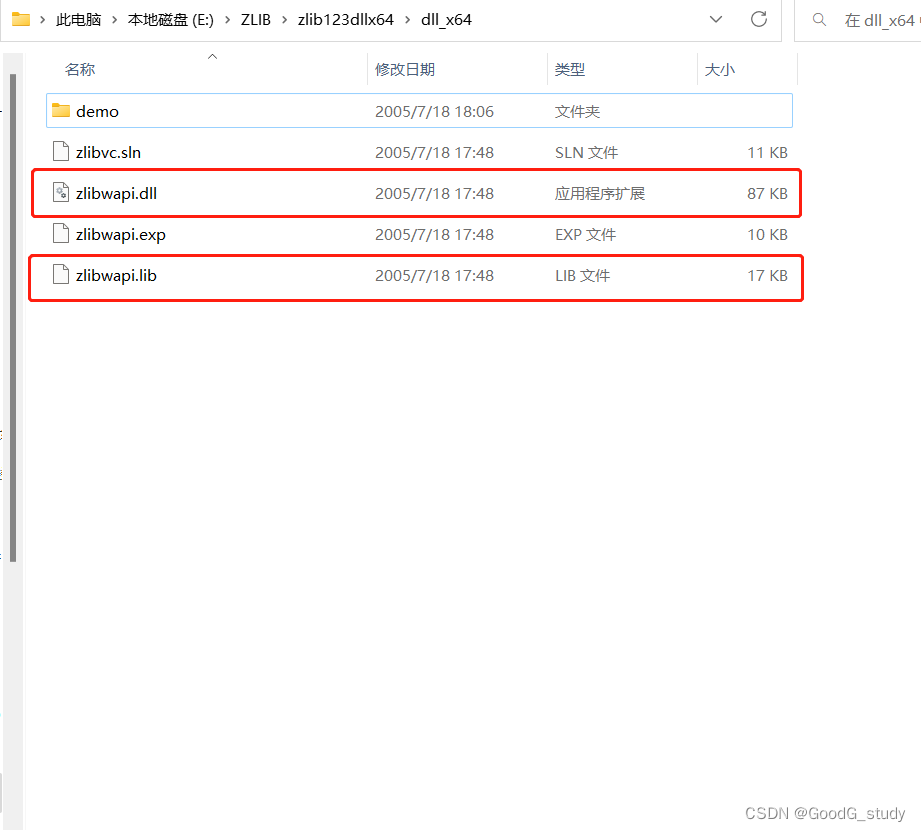
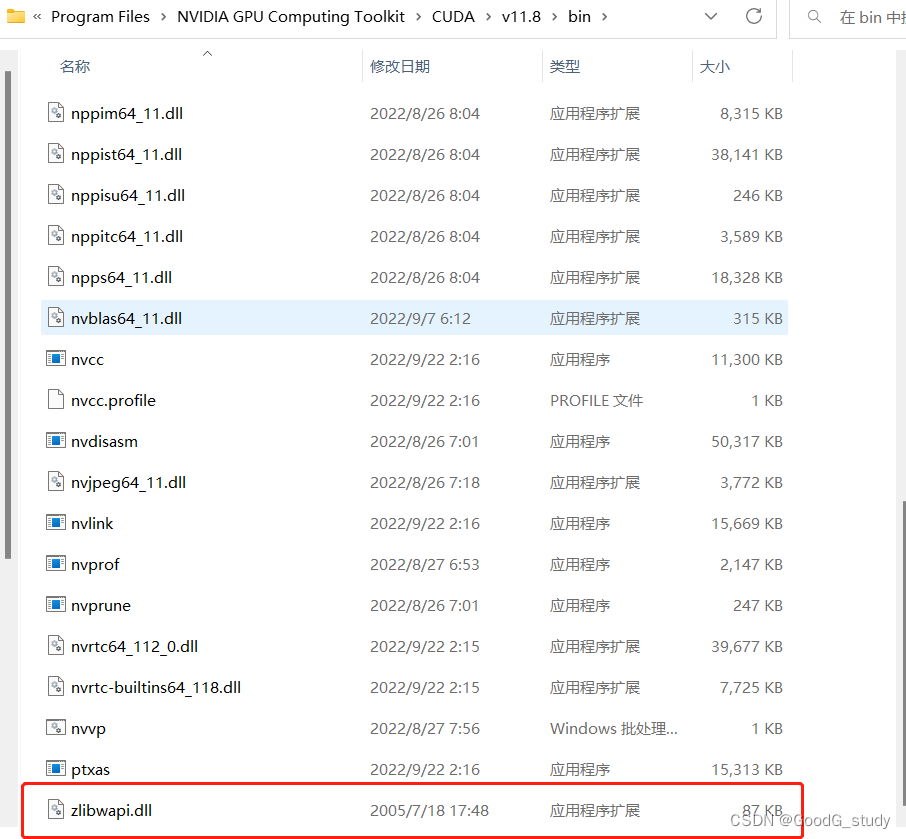
将zlibwapi.lib复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\lib目录下
4.问题解决


















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









