






本文是看完该教程https://www.51zxw.net/list.aspx?cid=732后的实践
分析
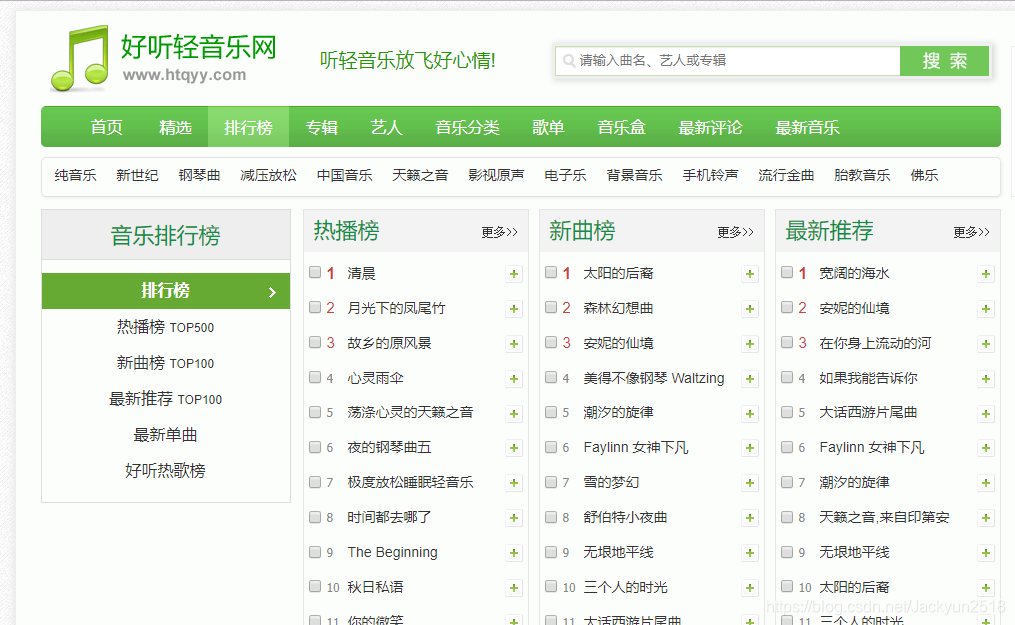
第一步:进入轻音乐网的热搜榜页面
第二步:ctrl+shift+i 打开开发者页面
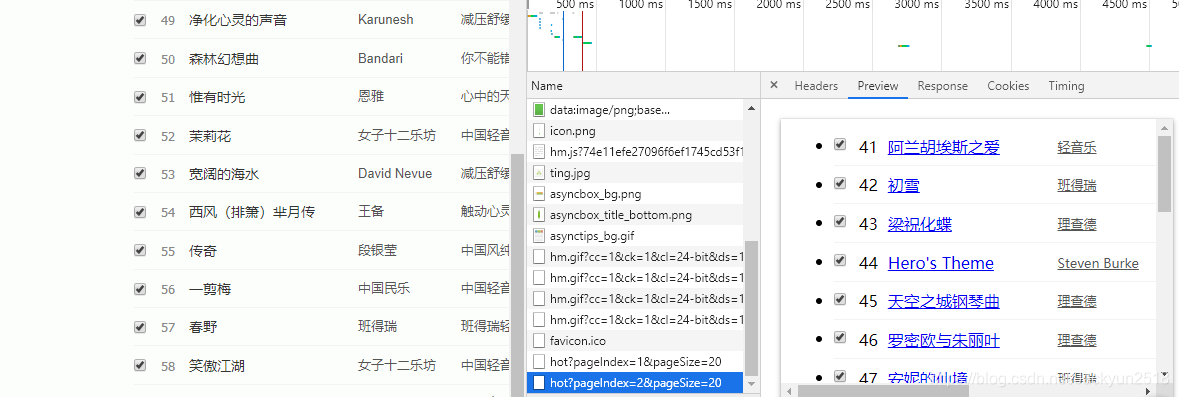
第三步:找寻页面1,2,3的网址
页面1:http://www.htqyy.com/top/musicList/hot?pageIndex=0&pageSize=20
页面2:http://www.htqyy.com/top/musicList/hot?pageIndex=1&pageSize=20
页面3:http://www.htqyy.com/top/musicList/hot?pageIndex=2&pageSize=20
可知pageIndex=页码-1
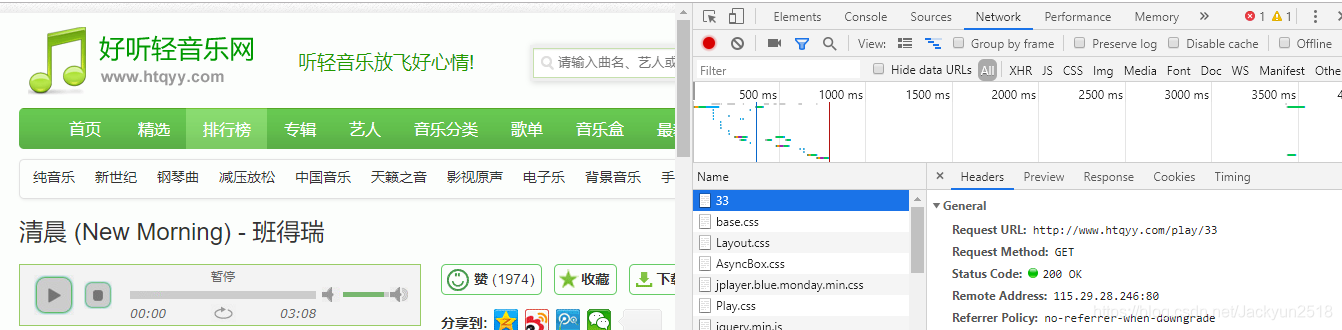
第四步,歌曲URL:http://www.htqyy.com/play/33
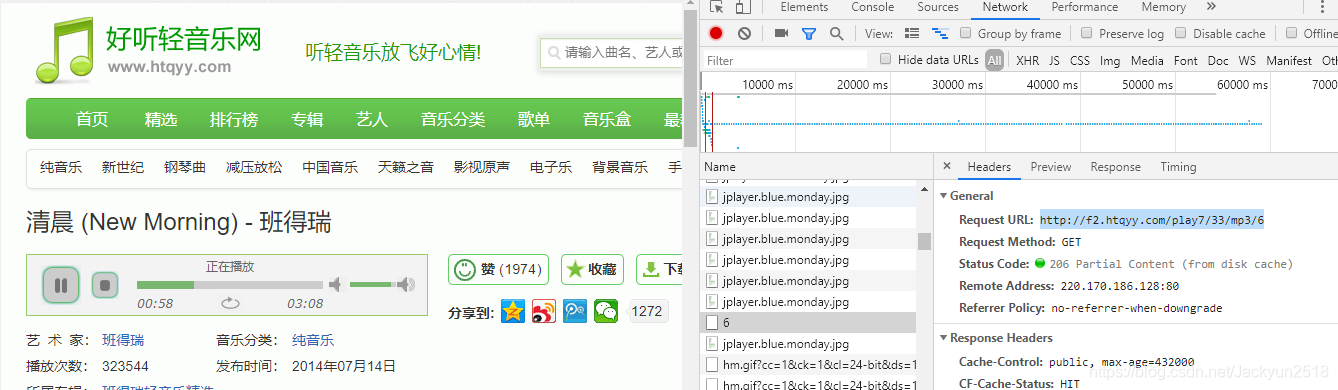
第五步:资源URL:http://f2.htqyy.com/play7/33/mp3/6 属于媒体type
实例代码:
import requests
import re
import time
#http://www.htqyy.com/top/musicList/hot?pageIndex=0&pageSize=20 第一页
#http://www.htqyy.com/top/musicList/hot?pageIndex=1&pageSize=20 第二页
#http://www.htqyy.com/top/musicList/hot?pageIndex=2&pageSize=20 第三页
#pageIndex=页数-1
#歌曲网址 http://www.htqyy.com/play/33
#<a href="/play/33" target="play" title="清晨" sid="33">清晨</a>
songName=[] #title
songID=[] #sid
page = int(input("请输入您要爬取的页数:")) #page传入以下参数
#遍历爬取的页面
for i in range(0, page): #如果是从1开始,str(i-1)
url="http://www.htqyy.com/top/hot?pageIndex="+str(i)+"&pageSize=20"
#获取第n个网页信息
html =requests.get(url)
#获取网页源码
strr = html.text
#正则表达式提取数据
pat1=r'title="(.*?)" sid' #<a href="/play/33" target="play" title="清晨" sid="33">清晨</a>
pat2=r'sid="(.*?)"'
titlelist=re.findall(pat1, strr)
idlist=re.findall(pat2, strr)
songName.extend(titlelist) #将歌名的列表放入定义的songName空列表即两个列表合并
songID.extend(idlist)
#获取到了歌名和ID,下一步获取歌曲资源所在链接
for i in range(0, len(songID)):
songurl = "http://f2.htqyy.com/play7/"+str(songID[i])+"/mp3/6"
data = requests.get(songurl).content #歌曲资源属于媒体类型,须二进制读出
#保存资源到本地
print("正在下载第", i+1, "首")
with open("F:\\SpiderData\\music\\{}.mp3".format(songName[i]), "wb")as f:
f.write(data)
time.sleep(0.5)
运行结果














 690
690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









