









文章目录
前言
有的网页查看起来不是很方便,于是就想到了,转成pdf转下来慢慢看?
先看下成果图哈
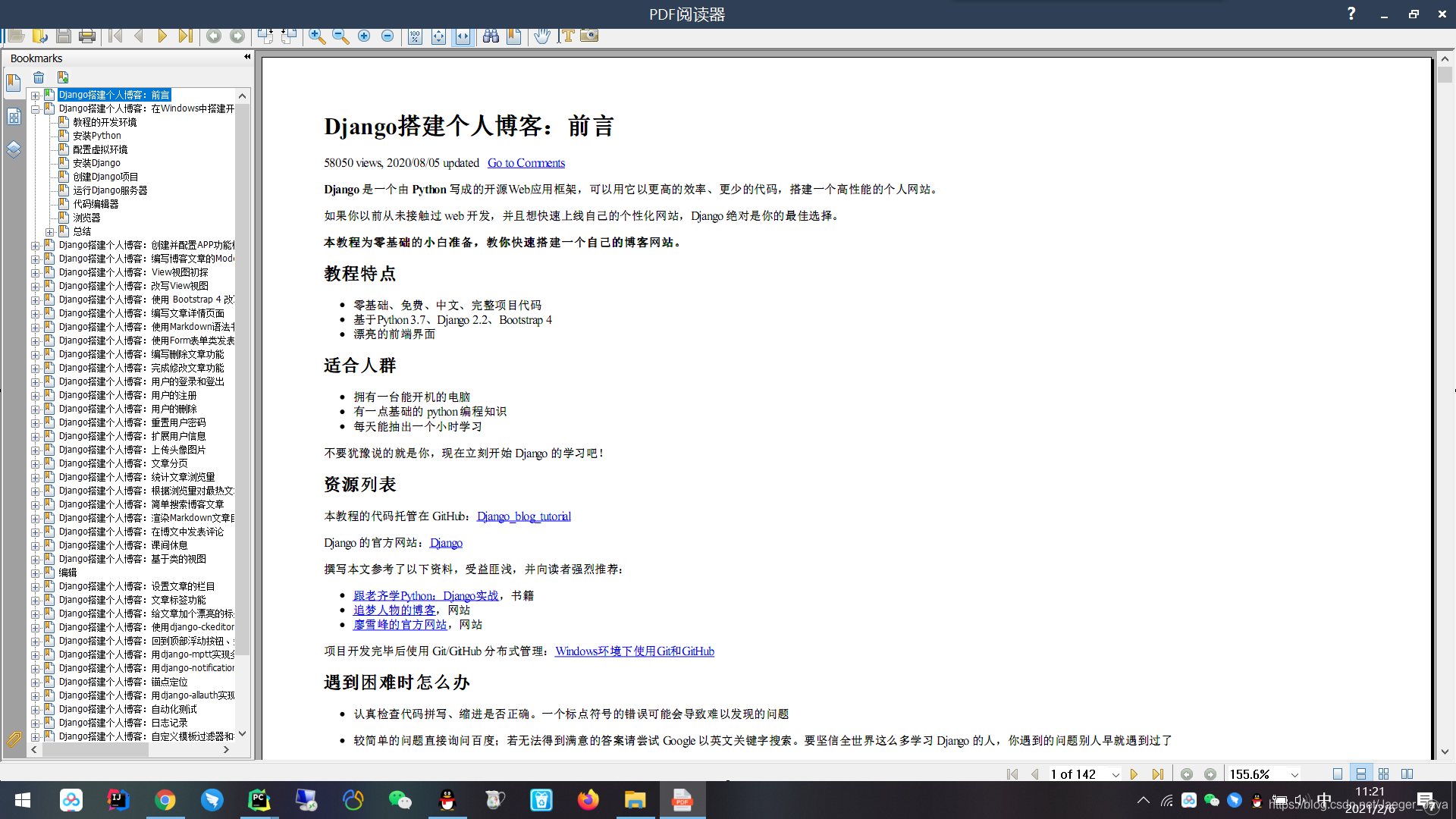
最终效果就是这样子,感觉是不是很炫酷,哈哈哈
一、安装必要软件
感觉下载慢的直接加群也可以
群里工具太多,需要的随便拿
二、开怼代码
1.引入库
pip install pdfkit
2.导包
import pdfkit
import requests
from lxml import etree
import re
3.糟糕网站
self.url = "https://www.dusaiphoto.com/article/detail/2/"
4.创建对象HtP
Html转Pdf简写对象名HtP,pdfkit.configuration换成自己的路径哦
对,现在你就有对象了,不是单身了
class HtP:
def __init__(self):
self.uu = 'https://www.dusaiphoto.com%s'
self.url = "https://www.dusaiphoto.com/article/detail/2/"
self.contents = ''
self.confg = pdfkit.configuration(wkhtmltopdf=r'F:\pdf\wkhtmltopdf\bin\wkhtmltopdf.exe')
self.list_url = ["https://www.dusaiphoto.com/article/detail/2/", ]
def __del__(self):
print("------------------------打印结束--------------------------")
5.获取链接
因为你要的pdf不是一个,所以要把所有界面的Html组装起来
思路:
- 找到第一个地址,打开后根据正则获取到每个链接
- 这里使用什么方法不限制,Xpath?BS4?Re?随意
- 我这里使用Re获取到每个连接,然后拼接到数组
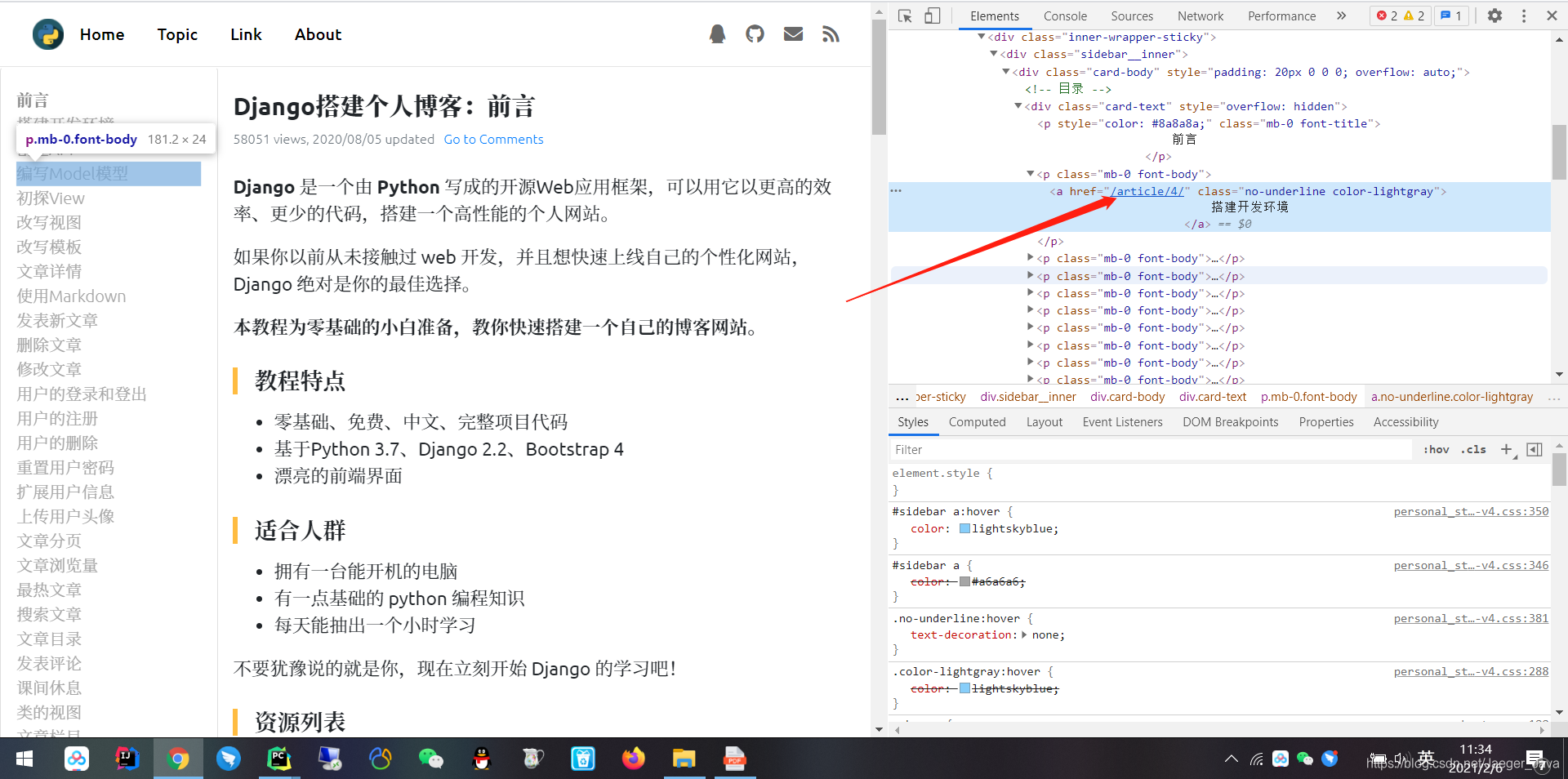
# 获取链接
def get_list_url(self):
html = requests.get(self.url).content.decode('utf-8')
con = \
re.findall(r'<div class="card-text" style="overflow: hidden">(.+?)<div class="container-fluid">', html,
re.S)[0]
lists = re.findall(r'<p class="mb-0 font-body">.+?<a href="(.+?)".+?class="no-underline color-lightgray"',
con, re.S)
for isurl in lists:
isurl = self.uu % isurl
self.list_url.append(isurl)
return self.list_url
6.获取正文内容
每个连接都是一个页面,获取内容返回即可,依旧三种方法,都可以,这里我用的依旧是正则Re
# 获取正文内容
def get_content(self, url):
html = requests.get(url).content.decode('utf-8')
content = \
re.findall(r'<div class="mt-4">(.+?)<div class="alert alert-secondary text-muted mt-4 mb-4 font-body">',
html, re.S)[0]
return content
7.循环每个内容拼接成大的页面
for url in urls:
print(url)
content = self.get_content(url)
self.contents = '%s%s%s' % (self.contents, content, '<p><br><p>')
这里的拼接用的%s%s%s,当然使用+=也没错,看自己喜好,开心就好啦
8.开始打印内容!
# 保存html为pdf文档
def dypdf(self, contents):
contents = etree.HTML(contents)
s = etree.tostring(contents).decode()
print("开始打印内容!")
pdfkit.from_string(s, r'out.pdf', configuration=self.confg)
print("打印保存成功!")
打印为什么不直接打印内容?
答:这个问题问的好,直接打文字,你以为是打稿机?输入什么就进去什么?写入pdf肯定是2进制的写入,直接写汉字进去,计算机听不懂的
那三个参数分别代表什么?
pdfkit.from_string(s, r'out.pdf', configuration=self.confg)
答:点开源码看看?
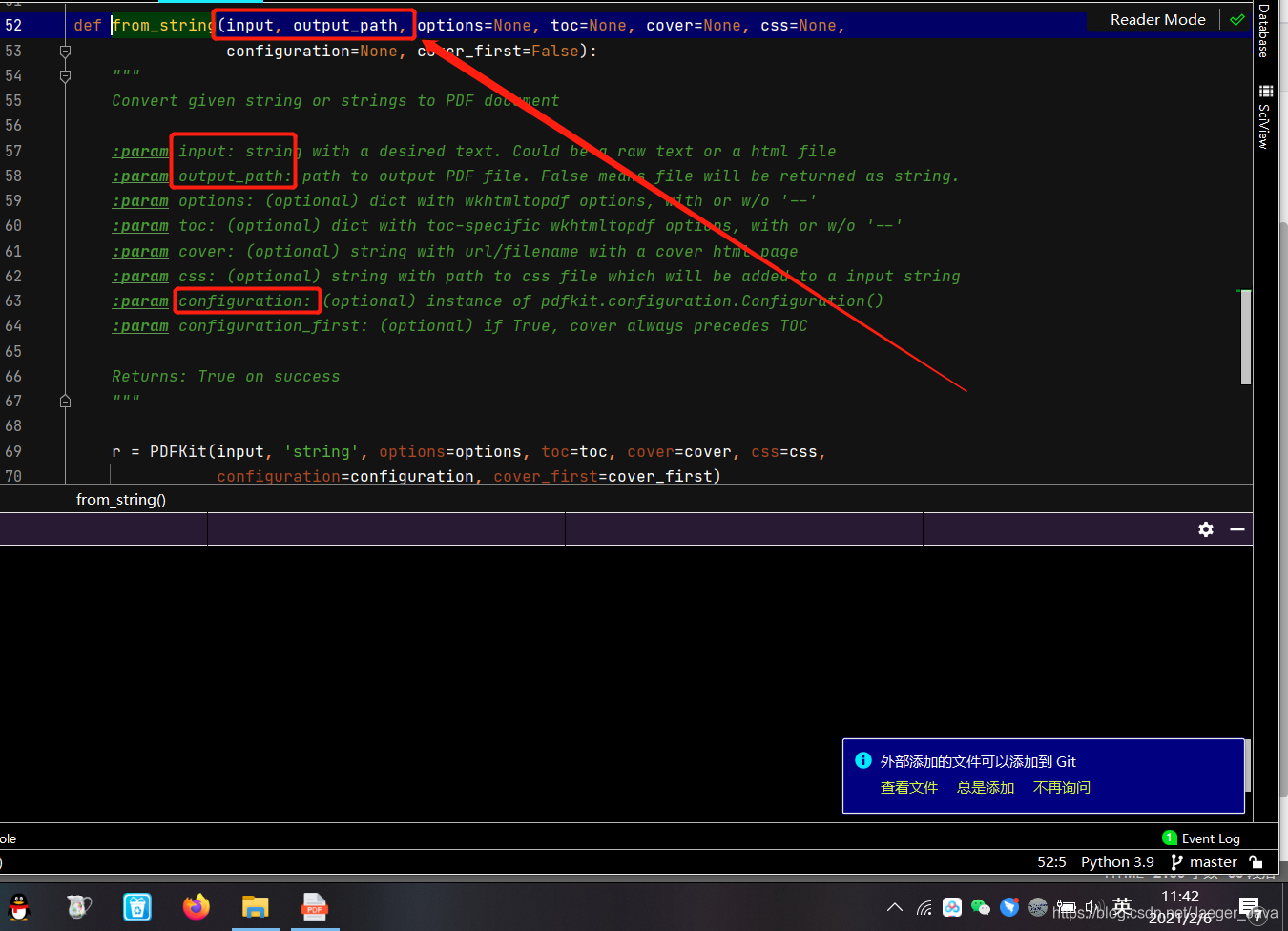
我还解释吗?写入文件,输出路径,打印程序,看不懂英语的百度翻译去好了,其他很多参数用不到,所以不需要写
9.最后一步来个main跑起来
if __name__ == '__main__':
HtP().run()
OK,完事
最后,附上源码?
哦哦,太占地方了,不上源码了,有兴趣的可以看我码云
总结
代码一步步分析很到位,应该看的懂
这就是Html转Pdf的所有内容了,俺的演讲完毕,谢谢大家聆听















 3081
3081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









