







作者:Jason
时间:2017.10.22
RNN的引出
在没有RNN(循环神经网络)的时候,我们通常使用前馈神经网络来处理时序预测问题。
一、用前馈神经网络处理时间序列预测有什么问题?
依赖受限,网络规格固定:前馈网络是利用窗处理将不同时刻的向量并接成一个更大的向量。以此利用前后发生的事情预测当前所发生的情况。如下图所示:
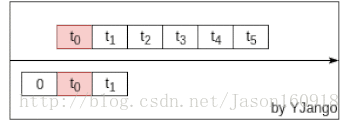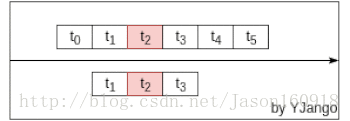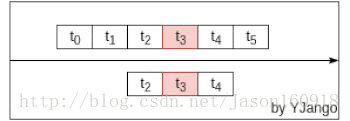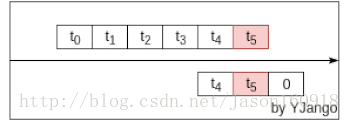
但其所能考虑到的前后依赖受限于将多少个向量(window size)并接在一起。所能考虑的依赖始终是固定长度的。想要更好的预测,需要让网络考虑更多的前后依赖。
例子:
比如在“我()”的后面预测一个字,可能出现很多种类似于“我们”、“我的”等等大概率下的可能性。进一步考虑“我想()”,则可选的范围会缩小,更进一步例如“我想骑自行()”则很有把握的给出预测为“车”。
所以要想预测更为准确的话,我们能首先想到的办法就是扩大拼接的向量长度,但是考虑这样一种情况:假如每个向量的维度是30,经过长度为3移动窗口处理之后,输入input的维度变为30*3=90,输入层与隐藏层(n的神经元)的连接权重矩阵就会变成90*n,其中很多权重是冗余的,但却不得不一直存在每一次预测中。
神经网络的学习黑洞
几乎所有的神经网络都可以看作为一种特殊制定的前馈神经网络,这里“特殊制定”的作用在于缩减寻找映射函数的搜索空间,也可以理解为减少VC维(目前神经网络没有明确界定VC维大小的方法,暂且把它等于可训练参数量),也正是因为搜索空间的缩小,才使得网络可以用相对较少的数据量学习到更好的规律。
例子
解一元二次方程y=ax+b。我们需要两组配对的(x,y)关系式来解该方程。但是如果我们知道y=ax+b实际上是y=ax,则只要搜索a的大小,这时就只需要一对(x,y)就可以确定x与y的关系。循环神经网络和卷积神经网络等神经网络的变体就具有类似的功效。
二、相比前馈神经网络,循环神经网络究竟有何不同之处?
需要注意的是循环网络并非只有一种结构(LSTM、GRU),这里介绍一种最为常用和有效的循环网络结构。
数学视角
首先让我们用从输入层到隐藏层的空间变换视角来观察,不同的地方在于,这次将时间维度一起考虑在内。
注:这里的圆圈不再代表节点,而是状态,是输入向量和输入经过隐藏层后的向量。
例子:用目前已说的所有字预测下一个字。
前馈网络:window size为3帧的窗处理后的前馈网络
数学公式: ,concat表示将向量并接成一个更大维度的向量。
学习参数: 需要从大量的数据中学习W和b,要学习各个时刻(3个)下所有维度(39维)的关系(39*3个),就需要很多数据。
循环网络:不再有window size的概念,而是time step
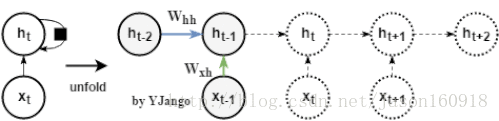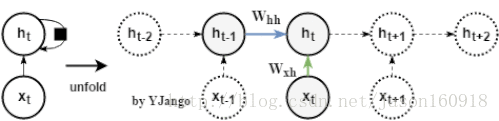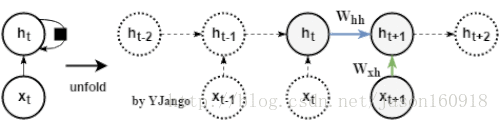
数学公式:,h_t同样也由x_t经W_xh的变化后的信息决定,但这里多另一份信息:W_hh* h_t_1,而该信息是从上一时刻的隐藏状态h_t_1经过一个不同的W_hh变换后得出的。
注:W_xh的形状是行为dim_input,列为dim_hidden_state,而W_hh是一个行列都为dim_hidden_state的方阵。
学习参数:前馈网络需要3个时刻来帮助学习一次W_xh,而循环网络可以用3个时刻来帮助学习3次W_xh和W_hh。**换句话说:所有时刻的权重矩阵都是共享的(更新的对象是不变的)。这是循环网络相对于前馈网络而言最为突出的优势。
循环神经网络是在时间结构上存在共享特性的神经网络变体。随着时间的改变而神经网络的参数共享是递归网络的核心中的核心,相比于前馈神经网络加上窗口移动的方式可以大大的减少可训练参数。
物理视角
使用下面的例子可能更容易体会共享特性对于数据量的影响。
![https://pic2.zhimg.com/v2-c84b8f3c65a62e4ceee81899c5126365_b.gif]
若用前馈网络:网络训练过程相当于不用转盘,而是徒手依次按各个角度捏成想要的形状(类比于移动窗口)。不仅工作量大,效果也难以保证。
若用循环网络:网络训练过程相当于在不断旋转的转盘上(times_steps),以一种手势捏造所有角度(结构循环和共享)。工作量降低,效果也可保证。
递归网络特点
时序长短可变 : 只要知道上一时刻的隐藏状态h_t-1与当前时刻的输入x_t,就可以计算当前时刻的隐藏状态h_t。并且由于计算所用到的W_xh与W_hh在任意时刻都是共享的。循环网络可以处理任意长度的时间序列。
顾及时间依赖:若当前时刻是第5帧的时序信号,那计算当前的隐藏状态h_5就需要当前的输入x_5和第4帧的隐藏状态h_4,而计算h_4又需要h_3,这样不断逆推到初始时刻为止。意味着常规递归网络对过去所有状态都存在着依赖关系。
注:在计算h_0的值时,若没有特别指定初始隐藏状态,则会将h_-1全部补零,表达式会变成前馈神经网络:
未来信息依赖:前馈网络是通过并接未来时刻的向量来引入未来信息对当前内容判断的限制,但常规的循环网络只对所有过去状态存在依赖关系。所以循环网络的一个扩展就是双向(bidirectional)循环网络:两个不同方向的循环层叠加。
关系图:正向(forward)循环层是从最初时刻开始,而反向(backward)循环层是从最末时刻开始。
![https://pic1.zhimg.com/v2-a9c81692067bca508bc88ba3f3ecb7b8_r.jpg]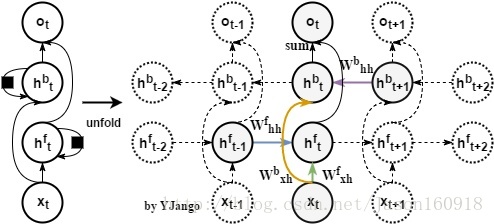
数学式子:
正向循环层:
反向循环层:
双向循环层:
注:最后一般除了相加的方式,还有一种拼接的方式:,反向循环层的作用是引入未来信息对当前预测判断的额外限制。
注:隐藏状态h_t通常不会是网络的最终结果,一般都会将h_t再接着另一个将其投射到输出状态o_t。一个最基本的循环网络不会出现前馈神经网络那样从输入层直接到输出层的情况,而是至少会有一个隐藏层。
注:双向循环层可以提供更好的识别预测效果,但却不能实时预测,由于反向循环的计算需要从最末时刻开始,网络不得不等待着完整序列都产生后才可以开始预测。在对于实时识别有要求的线上语音识别,其应用受限。
递归网络输出:循环网络的输出实际上是对前馈网络在时间维度上的扩展。
关系图:常规网络可以将输入和输出以向量对向量(无时间维度)的方式进行关联。而循环层的引入将其扩展到了序列对序列的匹配。从而产生了one to one右侧的一系列关联方式。较为特殊的是最后一个many to many,发生在输入输出的序列长度不确定时,其实质两个循环网络的拼接使用,公共点在紫色的隐藏状态。
![https://pic3.zhimg.com/v2-78c48d9ca0b66d6b46202b019b5ecb66_b.png]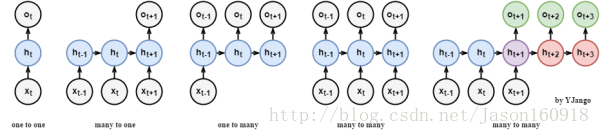
many to one:常用在情感分析中,将一句话关联到一个情感向量上去。
many to many:第一个many to many在DNN-HMM语音识别框架中常有用到
many to many(variable length):第二个many to many常用在机器翻译两个不同语言时。
前馈网络的数据形式:输入和输出:矩阵
输入矩阵形状:(n_samples, dim_input)
输出矩阵形状:(n_samples, dim_output)
注:真正测试/训练的时候,网络的输入和输出就是向量而已。加入n_samples这个维度是为了可以实现一次训练多个样本,求出平均梯度来更新权重,这个叫做Mini-batch gradient descent。
如果n_samples等于1,那么这种更新方式叫做Stochastic Gradient Descent (SGD)。
循环网络:输入和输出:维度至少是3的张量,如果是图片等信息,则张量维度仍会增加。
输入张量形状:(time_steps, n_samples, dim_input)
输出张量形状:(time_steps, n_samples, dim_output)
(这种情况一般在TensorFlow里面设置为time_major=True)
注:同样是保留了Mini-batch gradient descent的训练方式,但不同之处在于多了time step这个维度。
Recurrent 的任意时刻的输入的本质还是单个向量,只不过是将不同时刻的向量按顺序输入网络。你可能更愿意理解为一串向量 a sequence of vectors,或者是矩阵。
网络层视角
请以“层”的概念对待所有网络。循环神经网络是指拥有循环层的神经网络,其关键在于网络中存在循环层。
每一层的作用是将数据从一个空间变换到另一个空间下。可以视为特征抓取方式,也可以视为分类器。二者没有明显界限并彼此包含。关键在于使用者如何理解。
以层的概念理解网络的好处在于,今后的神经网络往往并不会仅用到一种处理手段。往往是前馈、循环、卷积混合使用。 这时就无法再以循环神经网络来命名该结构。
例:下图中就是在双向循环层的前后分别又加入了两个前馈隐藏层。也可以堆积更多的双向循环层,人们也会在其前面加入“深层”二字,提高逼格。
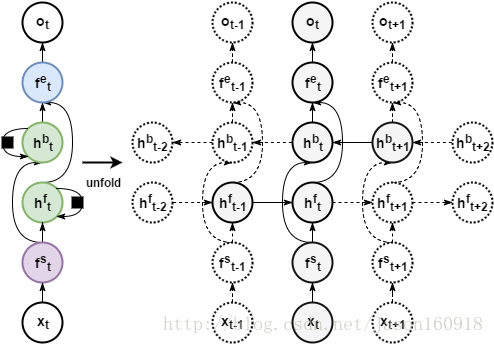
注:层并不是图中所画的圆圈,而是连线。圆圈所表示的是穿过各层前后的状态。
循环网络训练步骤
首先我们来看看循环神经网络从输入——>预测值——>计算误差——>误差反向传播——>更新权重的示意图。
看看下面的动态图,蓝色表示输入、红色表示隐藏层、绿色表示隐藏层里面保留着状态值state,紫色表示更新后的state,黑色代表预测值,黄色代表预测误差,暗黄色代表梯度反向传播。
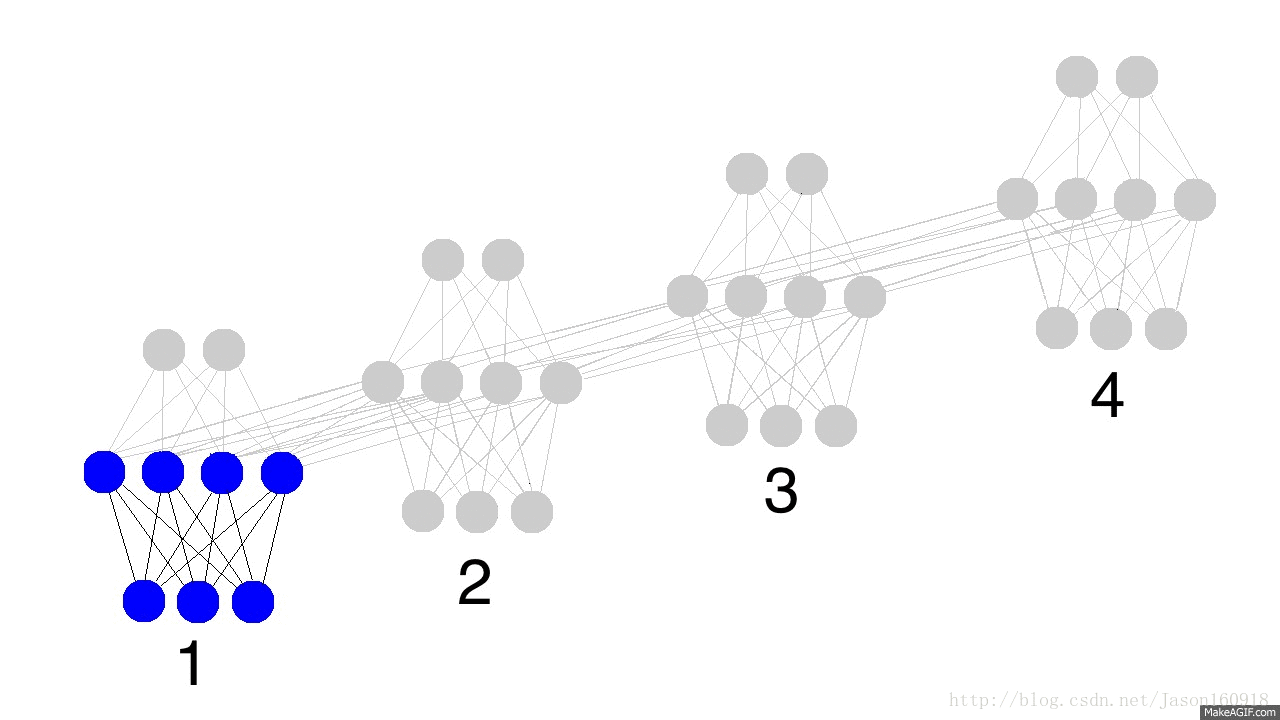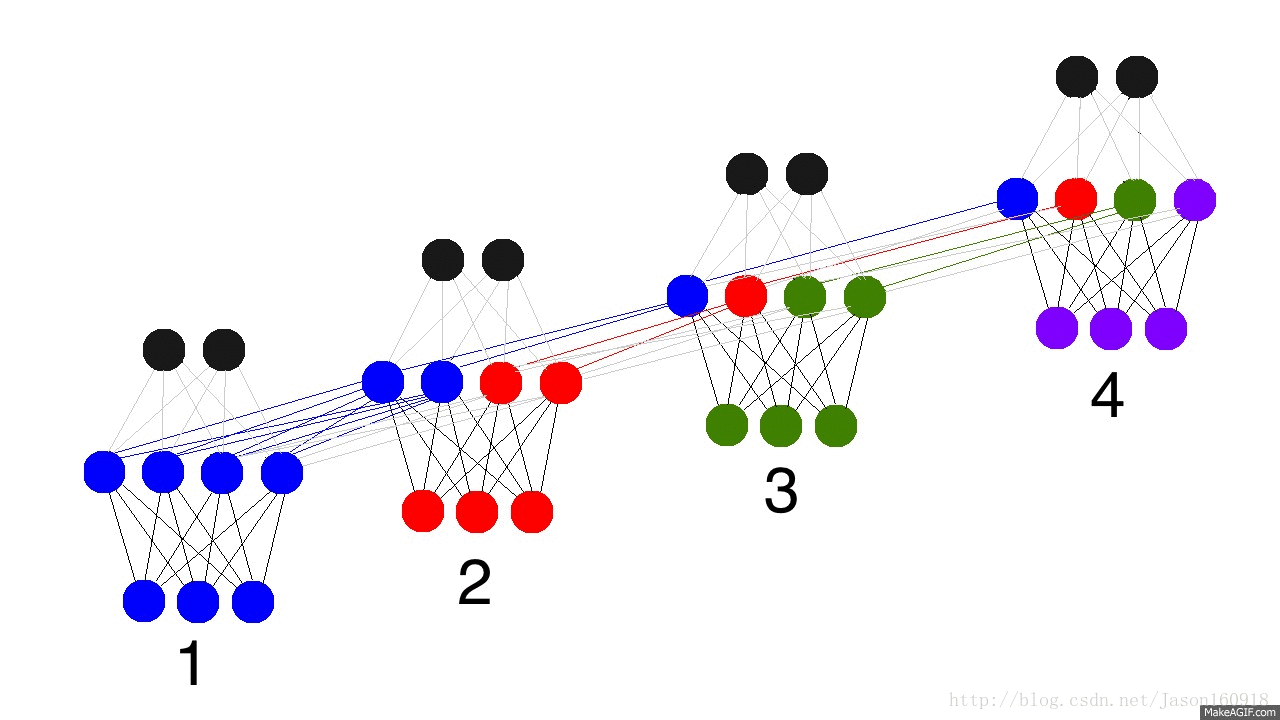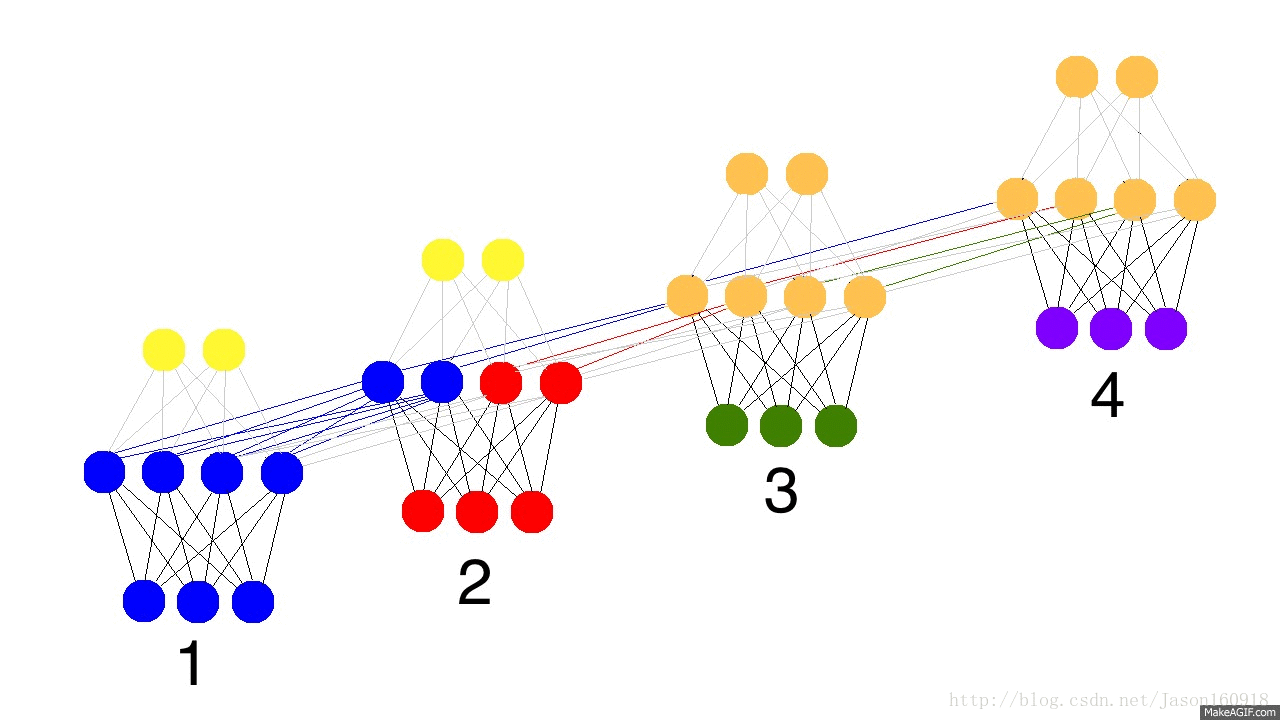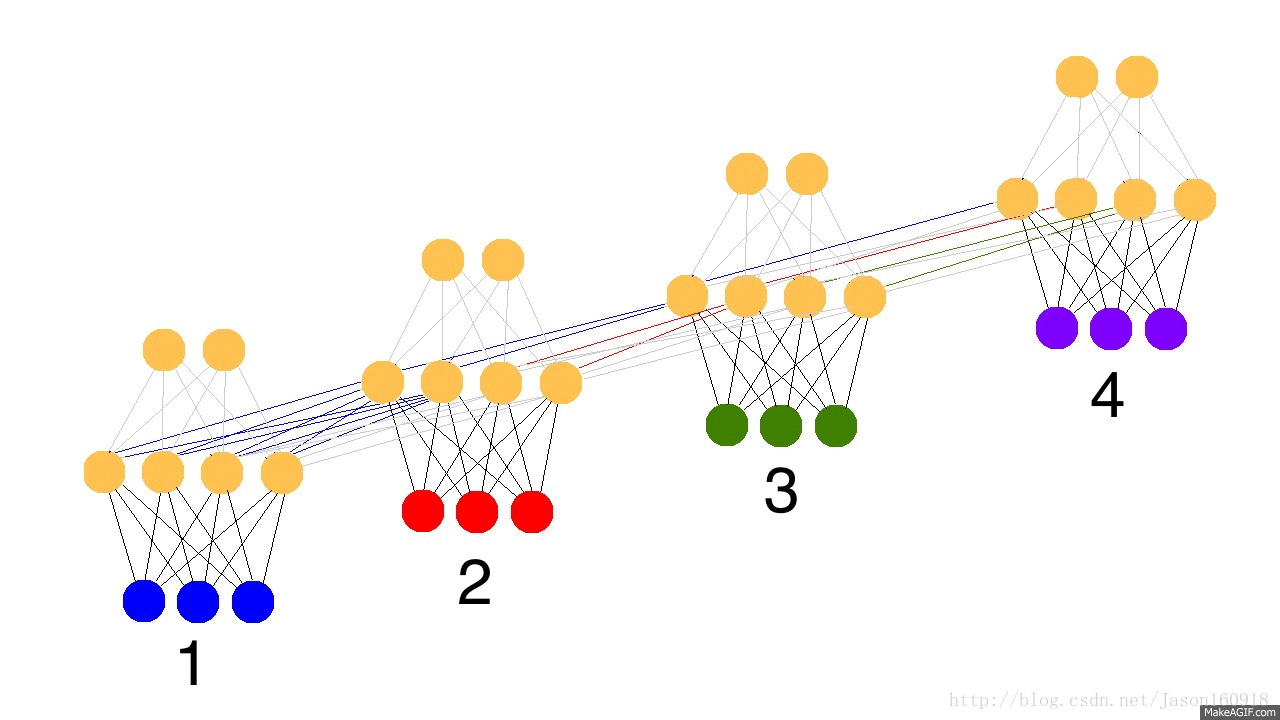
循环网络流程图
如上图所示:在循环神经网络(many_to_many)中,梯度反向传播算法成为BPTT算法,误差在每个时间步上横向传播。
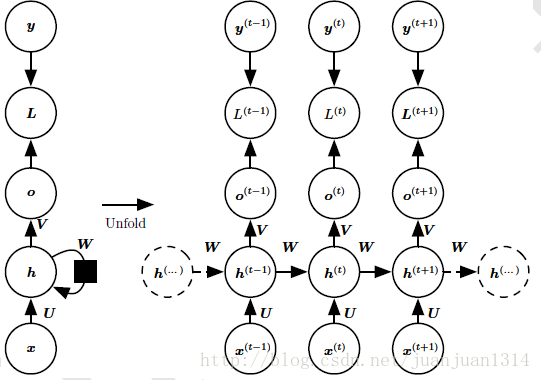
循环神经网络展开图
在循环神经网络中,横向传递的只有状态,而状态是一个固定长度的向量h。h的表达式可写作:这里写图片描述 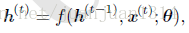
其中,θ是w和b的组合。 根据上图,各节点的公式表示为:
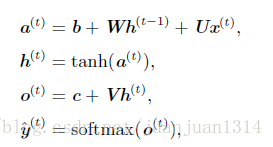
注:,将循环神经网络按时间维度展开之后,传播方式与深层神经网络类似,唯一区别就是循环神经网络中的U、V、W是共享的!,也可以说是训练对象是一致的。
循环网络问题
常规递归网络从理论上应该可以顾及所有过去时刻的依赖,然而实际却无法按人们所想象工作。原因在于梯度消失(vanishinggradient)和梯度爆炸(exploding gradient)问题。下一节继续讨论RNN的弊端以及RNN的改进版LSTM以及GRU网络原理和代码实现。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









