







目录
1. 问题背景与挑战
1.1.YouTube推荐系统规模
YouTube是全球最大的视频平台,用户量和视频内容数量非常庞大。论文指出,推荐系统需要在海量视频中快速选取少量对用户个性化且相关性高的内容,这对计算资源和实时性提出极高要求。
1.2.主要挑战
-
规模问题:传统的推荐算法在面对YouTube这种规模下的海量候选视频时难以胜任,需要采用特殊的分布式训练和高效的模型推理。
-
内容新鲜度:平台每天上传海量新视频,推荐系统必须能及时捕捉用户最新兴趣,同时不忽略热门视频。
-
数据噪声:用户的历史行为存在稀疏性且受许多不可观测因素影响,反馈信号(如视频观看时长)较为隐晦,标签噪声明显。这要求模型在设计和训练时对噪声具有鲁棒性。
2、系统架构概述——双塔架构简介
YouTube 推荐系统采用了 Two-Tower 模型(双塔模型) 架构来高效处理大规模候选召回任务:
-
左边是用户塔(User Tower):用来学习用户兴趣的表示。
-
右边是物品塔(Item Tower):用来学习视频的嵌入向量。
-
中间通过点积计算相似度:用户和视频向量计算相似度,用于召回排序。
+-------------------+ +------------------+
| | | |
| User Tower | | Item Tower |
| | | |
+--------+----------+ +---------+--------+
| |
用户稀疏 + 密集特征嵌入 视频ID嵌入
| |
多层DNN网络提取兴趣向量 视频Embedding
| |
+-------------+--------------------+
|
点积相似度(内积)
|
得分越高表示越相关
2.1 核心目标
快速召回“最可能感兴趣”的 Top N 视频,而不是从百万视频中一个个比对。
2.2 实现细节
论文将整个推荐流程划分为两个阶段,每个阶段都用到了深度神经网络模型:
-
第一个步骤:筛选候选视频
-
系统会观察你以前都看了哪些视频、搜索了什么内容、你的基本信息(比如年龄、地区等),然后把这些信息通过“深度学习”转化成一些数字,理解你可能喜欢什么;
-
因为视频库实在太大了(数以百万计),系统用一种叫“负采样”的方法,快速地从中选出一小部分视频作为候选,既能保证速度又保持一定的准确性。
-
负采样的本质,是在海量类别中,用一小部分“假的目标”来逼迫模型学会区分“谁是真的”。
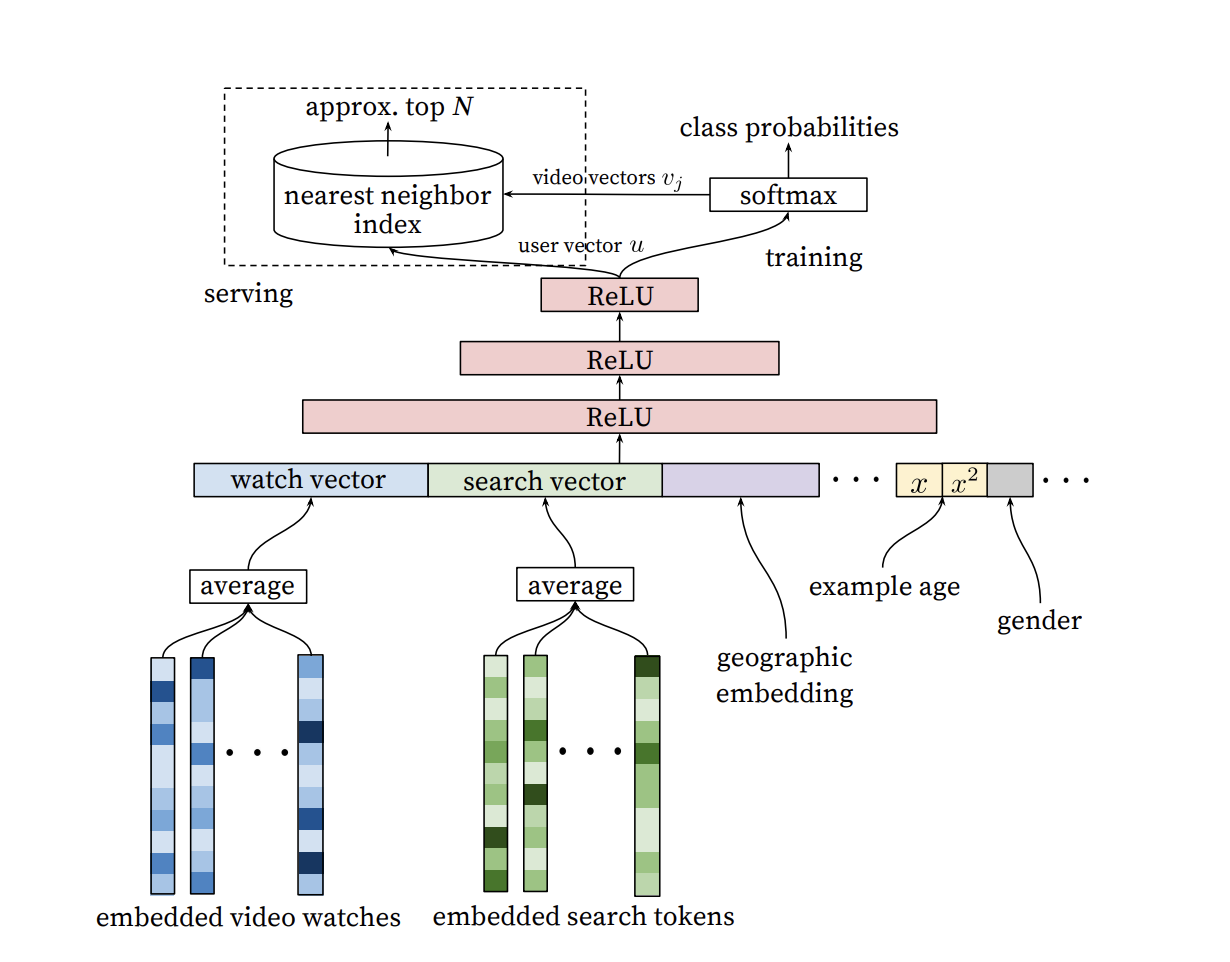
-
第二个步骤:再细挑细选
-
在已经筛选出来的视频中,系统会结合更多的细节特征,比如视频的具体内容、发布时间、频道信息等,用一个更精细的模型重新打分;
-
这里有个特别之处:系统不是单纯看你会不会点视频,而是
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











