




引言:追赶者的“后发优势”
在智能驾驶的赛道上,第一梯队已经进入了数据驱动的深水区。对于正在发力追赶的主机厂而言,我们不需要去赌未知的技术路线,我们的核心战略是:“拥抱工业界验证过的 SOTA 方案,用极致的数据工程效率抹平算法代差。”
本文将从算法栈选型、数据流水线构建、闭环自动化三个维度,拆解一套可落地、低成本、高效率的工程化蓝图。

一、 算法架构:从“看得见”到“博弈”
我们不追求学术界的“新奇特”,只选择头部玩家(如Tesla、小鹏、华为)已经量产验证的成熟架构。
1. 感知层:BEV + Transformer 是绝对基座
传统的“2D检测+后处理融合”已无法应对复杂的城市路况(遮挡、截断)。我们采用 3D 特征级融合 路线。
-
视觉核心:轻量化 BEV (Bird's Eye View)
-
架构选择: 采用 BEVDet 或 StreamPETR 架构。
-
核心难点: 放弃计算量巨大的 Transformer Attention 投影,采用改进版 LSS (Lift-Splat-Shoot)。
-
工程细节: LSS 的 Voxel Pooling 步骤是计算瓶颈,必须在 TensorRT 层面编写专用 Plugin 算子,实现深度的并行化计算,确保推理延迟控制在 30ms 以内。
-
时序融合: 引入 Temporal Module,在 BEV 空间内缓存过去 T 帧(如2秒)的特征,利用 GRU 或 Attention 机制融合,解决测速和遮挡问题。
-
-
多模态融合:TransFusion (前融合)
-
融合策略: 放弃卡尔曼滤波后融合。采用 Soft Association 机制。
-
技术细节: 以 Lidar 提取的稀疏 Query(位置准)去查询 Camera 的 Dense Feature(语义准)。为了加速,利用 Lidar 生成 Heatmap 进行 Query 初始化(Heatmap Initialization),只在有物体的区域进行计算,大幅降低算力消耗。
-
-
最后一道防线:Occupancy Network (OccNet)
-
目标: 通用障碍物检测(GOD)。识别训练集中没有的“异形障碍物”(如侧翻车辆、落石)。
-
工程落地: 输出 200×200×16 的 Voxel Grid。为了解决显存爆炸问题,采用 Cascaded(级联)结构:先预测粗粒度网格,再对“占据”区域进行细粒度细分。
-

2. 规控层:规则保底,学习致胜
-
高速/封闭场景:Lattice Planner + MPC
-
路径规划: 使用 Lattice Planner,在 Frenet 坐标系下进行时空采样。
-
控制执行: 部署 MPC (模型预测控制),建立车辆动力学模型预测未来 N 步状态,处理系统延迟,解决高速过弯“画龙”问题。
-
-
城市博弈场景:Learning-based Planner
-
策略: 引入 模仿学习 (Imitation Learning)。
-
输入: 矢量化的感知结果(VectorNet编码)+ 高精/局部地图。
-
输出: 拟人化的轨迹和速度。
-
安全兜底: 结合 RSS (责任敏感安全模型) 进行校验,确保学习模型的输出不违反物理安全边界。
-
二、 大数据基建:构建“AI 数据工厂”
算法是引擎,数据是燃料。作为大数据开发团队,我们的任务是把“死”的 Log 数据变成“活”的 Training Data。
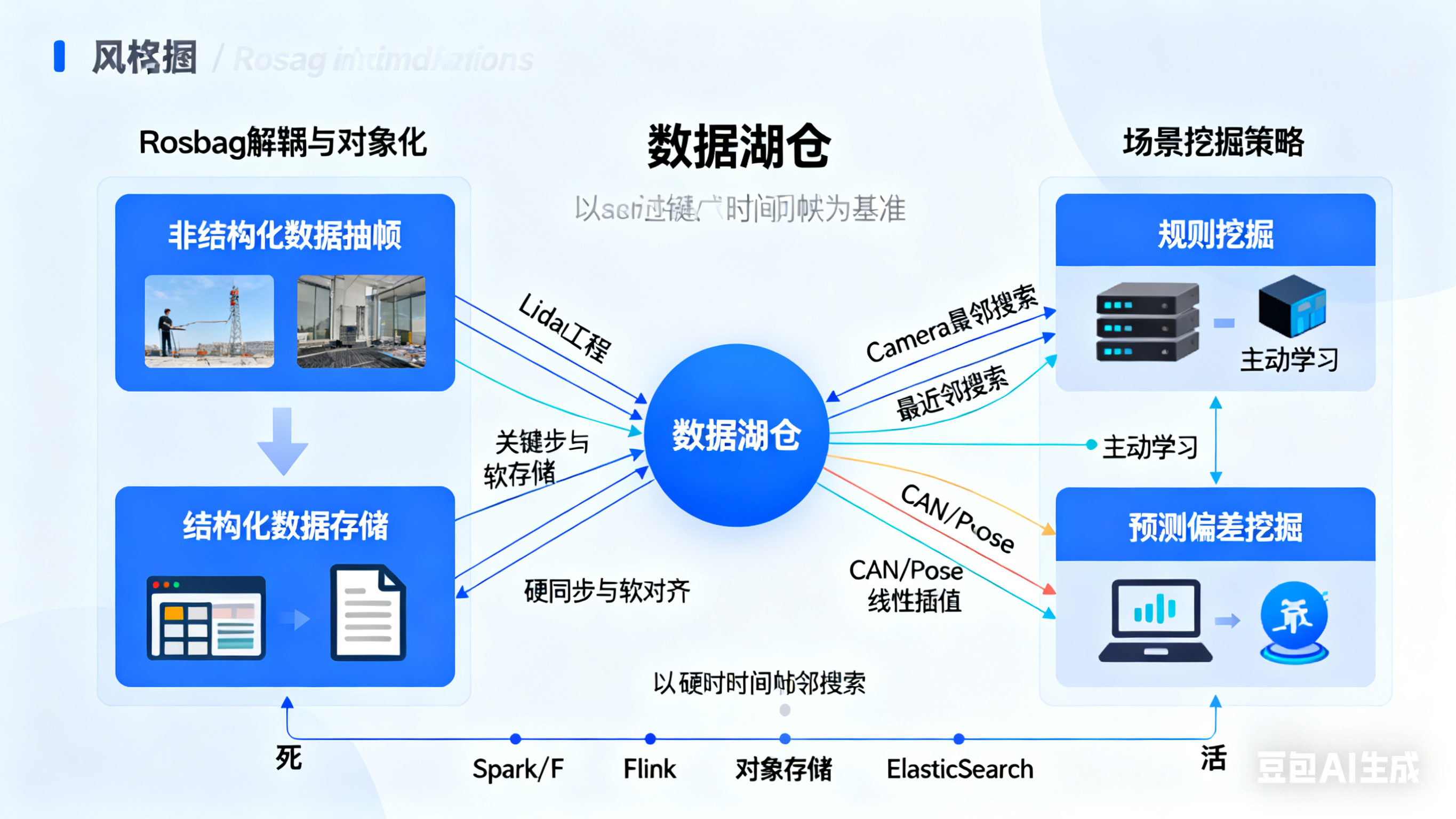
1. 基础架构:Frame-based 数据湖仓
告别以 Rosbag 文件为单位的低效处理模式,构建基于 Spark/Flink + 对象存储 的帧级数据湖。
-
Rosbag 解耦与对象化:
-
编写分布式解析器,将 Rosbag “炸开”。
-
非结构化数据: H264 抽帧为图像,点云转为 PCD/BIN,存入 S3/MinIO。
-
结构化数据: CAN、IMU、GPS 写入时序数据库或 Parquet。
-
-
关键工程:硬同步与软对齐
-
痛点: 传感器频率不一致(雷达10Hz,相机30Hz)。
-
解决方案: 编写 Spark UDF。以 Lidar 时间戳 为 Pivot(基准):
-
Camera: 执行最近邻搜索(Nearest Neighbor Search)。
-
CAN/Pose: 执行线性插值(Linear Interpolation)。
-
坐标系: 统一转换至 Ego-Vehicle 坐标系。
-
-
清洗规则: 自动丢弃时间戳漂移超过 20ms 或 丢帧的数据,保证送入模型的数据绝对“干净”。
-
2. 场景挖掘:从海量数据中“淘金”
只有高价值数据才值得被标注和训练。
-
元数据索引:
-
利用 Elasticsearch 建立场景库。标签包含:天气、路型、光照、车辆行为。
-
-
挖掘策略:
-
规则挖掘: 基于 Spark SQL 筛选,如 brake_pedal > 30% (急刹)、steer_angle_rate > threshold (急打方向)。
-
主动学习 (Active Learning): 在 ETL 链路中部署轻量级模型。计算模型预测的 熵 (Entropy),对于预测“犹豫不决”(置信度低)的帧,标记为 High_Value,优先推送标注。
-
预测偏差挖掘: 部署预测模型,当算法预测旁车“直行”但实际数据中旁车“切入”时,捕获该 Corner Case。
-
三、 闭环流水线:全链路自动化
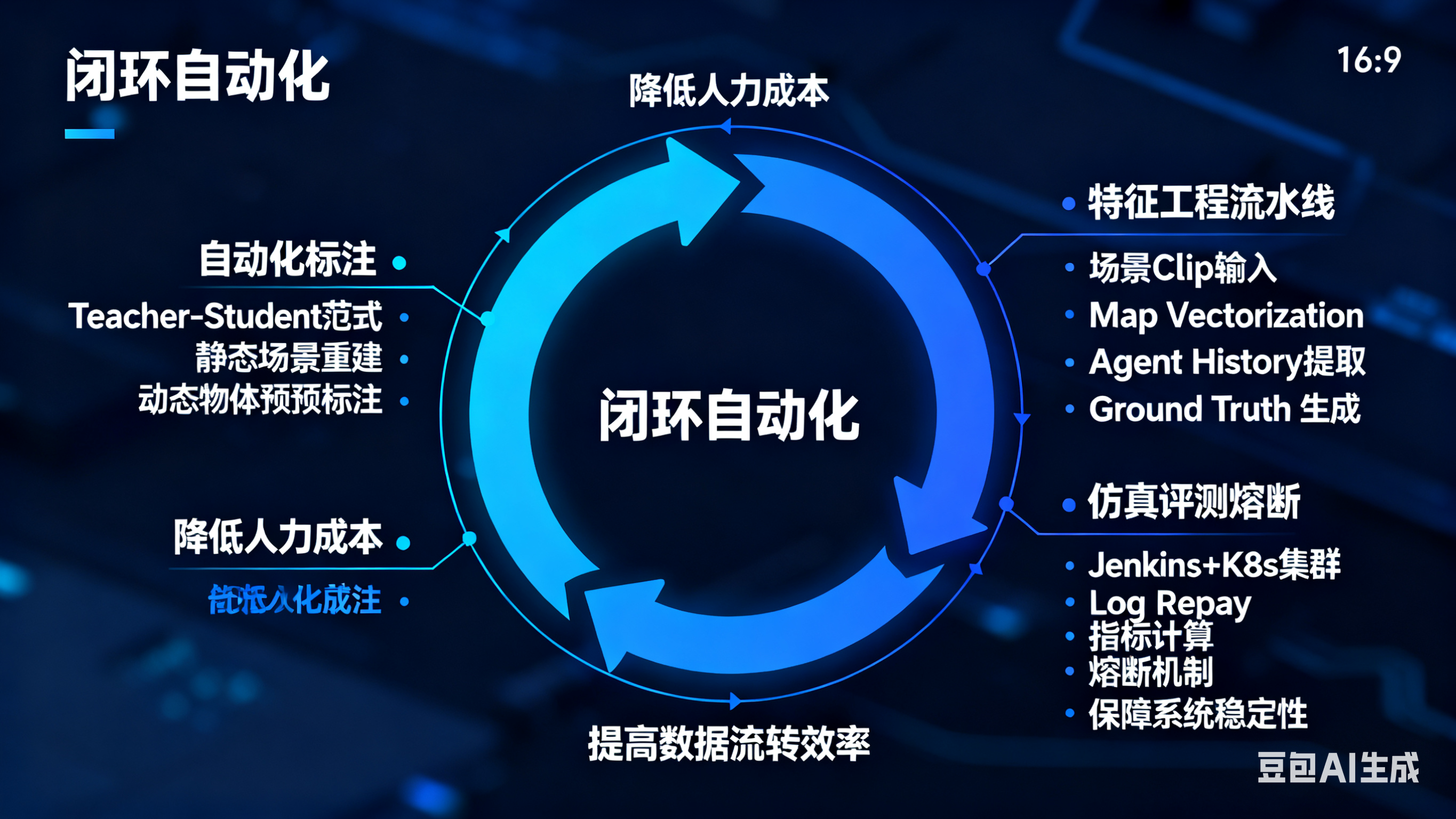
为了弥补人力不足,必须用算力换人力,实现自动化的数据流转。
1. 自动化标注
-
Teacher-Student 范式:
-
在云端部署 超大参数量 的感知模型(如 32线 Lidar 升级为融合大模型)。
-
静态场景重建: 利用多帧点云拼接与 NeRF/3D Reconstruction 技术,自动化生成高精度的静态背景真值(用于 OccNet 和 Mapless 训练)。
-
动态物体标注: 利用云端大模型对数据进行预标注(Pre-labeling),人工仅需对低置信度结果进行微调。
-
2. 特征工程流水线
针对规划算法的训练,构建自动化特征提取流:
-
输入: 挖掘出的场景 Clip。
-
处理:
-
Map Vectorization: 将车道线转化为矢量 Polyline。
-
Agent History: 提取周围车辆过去 T秒的轨迹。
-
Ground Truth: 提取人类驾驶员未来 N 秒的真实轨迹与速度。
-
-
产出: 序列化为 .tfrecord 或 .pkl,直接喂给 Learning-based Planner。
3. 仿真评测熔断
代码上车前的最后一道关卡。
-
架构: Jenkins + K8s 集群。
-
流程:
-
代码提交触发构建。
-
自动拉起 500+ 个仿真容器。
-
Log Replay: 回放历史高危场景(接管数据),注入新算法。
-
指标计算: 对比新算法轨迹与人类轨迹的 DTW (动态时间规整) 距离,检查碰撞率 (Collision Rate) 和 急动度 (Jerk)。
-
熔断: 核心指标下降,自动拦截合并。
-
四、 总结与路线图
对于务实的追赶者,我们的技术演进路线图如下:
-
阶段一(活下来):
-
算法: BEVDet + EM Planner + PID/LQR。
-
数据: 搭建 Spark 清洗链路,实现传感器硬同步,跑通基础标注。
-
-
阶段二(好用 - 高速NOA):
-
算法: 升级为 TransFusion + Lattice Planner + MPC。
-
数据: 上线 Auto-labeling 平台,利用大模型预标注;建立基于规则的场景挖掘库。
-
-
阶段三(领先 - 城市NOA):
-
算法: 引入 OccNet + Mapless + Learning-based Planner。
-
数据: 影子模式全量上线,闭环迭代周期缩短至“周级”。
-
智驾下半场,拼的不是 PPT 上的概念,而是数据工厂中每一帧数据的流转效率。



















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











