







线性表,链表,哈希表是常用的数据结构,在JAVA开发时,JDK已经提供,包含在java.util包中。
Java集合(用来存储实例的容器)框架主要是有Collection和Map两个根接口及其子接口、实现类组成。大致可以分为Set 、List、Map三种。Set代表无序、
不可重复的集合;List代表有序、重复的集合;Map则代表具有映射关系的集合。在Java5之后,增加了Queue集合,代表一种队列集合。
1.Collection 接口
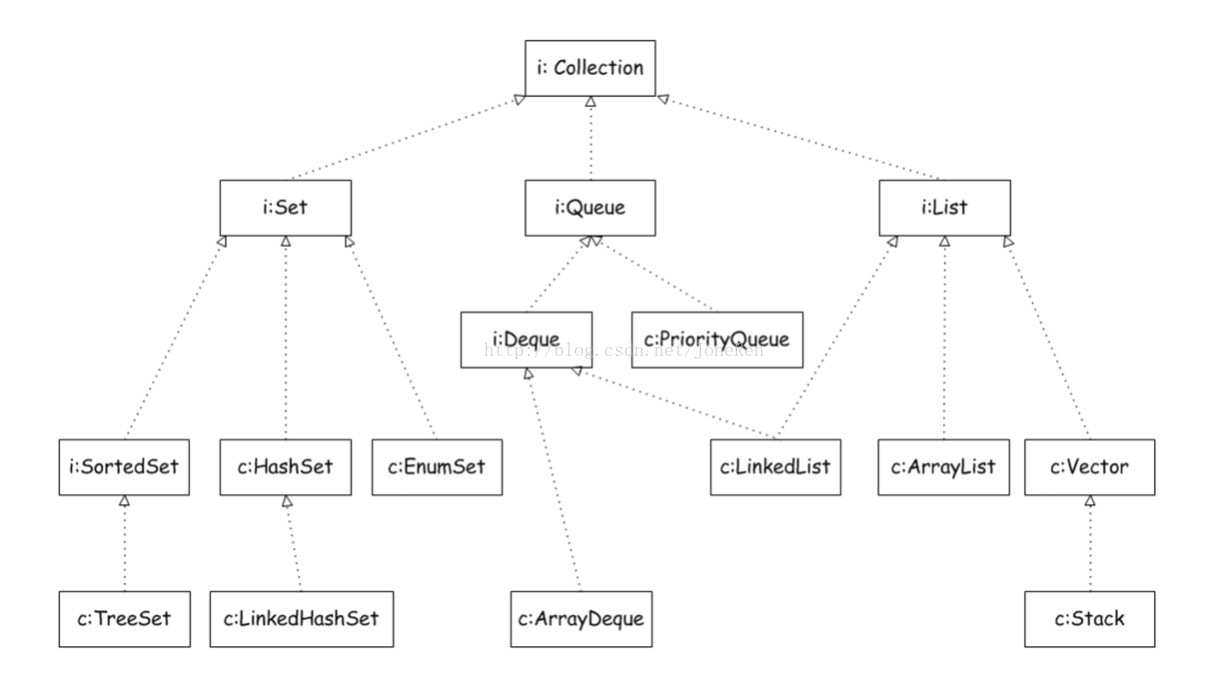
Collection接口是Set、List、Queue接口的父接口,Collection的遍历可以使用Iterator或者for循环来实现,但是在边遍历边删除的时候必须使用Iterator.remove()。
Iterator<Object> objects =list.iterator();
while(objects.hasNext()){
objects.remove();
}不要使用for循环方法,回报:ConcurrentModificationException错误,for(…)会自动生成一个iterator来遍历objects,但同时objects正在被Iterator.remove()修改。
在Java中不允许一个线程在遍历Collection的同时另一个线程在删除它。
List接口
List接口是有序的,相比set接口,会多一些与索引位置有关的方法。
ArrayList 和Vector 都是基于数组实现的List类,是线性表,使用Object数组作为容器去存储数据。特点相比LinkedList的是查询、遍历速度快,删除和插入速度慢。
ArrayList是线程不安全的,Vector是线程安全的,Vector提供了一个子类Stack,可以方便的模拟“栈”这种数据结构。Vector的性能会比ArrayList低,两者有很多重复方法,不推荐使用Vector类,即使需要考虑同步,即也可以通过其它方法实现。同样我们也可以通过ArrayDeque类或LinkedList类实现“栈”的相关功能。所以Vector与子类Stack,建议不在使用。
LinkedList基于链表实现的List类,是线程不安全的。特点是:相对于ArrayList是查询遍历速度慢,删除插入速度快。
List 拷贝有两种方法:一种使用ArrayList的构造器
Iterator<Object> objects =list.iterator();
while(objects.hasNext()){
objects.remove();
}第二种是Collection.copy():该,方法的话目标list至少跟源list长度一样长,否则
indexOutOfBoundsException
List<String> mLists = new ArrayList<>();
for (int i = 0; i < 4; i++) {
mLists.add("name" + i);
}
List<String> reCopy =new ArrayList<>(mLists.size());
Collections.copy(reCopy,mLists);
Set子接口
Set集合不允许包含相同的元素,判断对象是否相同根据equals
HashSet:底层是基于哈希表(HashMap)数据结构存储实例,为快速查找而设计的set,特点:1.不能保证元素的排列顺序,加入的元素要特别注意hashCode()方法的实现; 2. HashSet线程是不安全的,多线程访问,需要手动同步。3.集合元素值可以是null。
public HashSet() {
map = new HashMap<>();
}
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
} LinkedHashSet:底层是基于双向链表数据结构来存储数据结构的,特点:1.元素按照插入顺序排序,元素除了根据hasCode值来决定元素的存储位置,链表结构也在维护元素的位置,所以有序;2.性能低于HashSet,要维护元素的插入顺序。
TreeSet是SortedSet接口的实现类,保持次序的set,特点:1.实例都是有序的,按照排序顺序;2底层的数据结构是红黑二叉树;3.元素是相互兼容的类型,不同类型的实例不具备比较性。这里元素必须实现Comparable接口。可以定义比较器(Comparator)来实现自定义的排序
EnumSet:是专为枚举设计的集合类,EnumSet所有元素指定枚举类型的枚举值。
Queue子接口
Queue用于模拟队列这种数据结构,实现“FIFO”等数据结构。通常,队列不允许随机访问队列中的元素。且并未定义阻塞队列的方法,而这在并发编程中是很常见的。BlockingQueue 接口定义了那些等待元素出现或等待队列中有可用空间的方法,这些方法扩展了此接口
Queue 实现通常不允许插入 null 元素,尽管某些实现(如 LinkedList)并不禁止插入 null。即使在允许 null 的实现中,也不应该将 null 插入到 Queue 中,因为 null 也用作 poll 方法的一个特殊返回值,表明队列不包含元素。
boolean add(E e) : 将元素加入到队尾,不建议使用
boolean offer(E e): 将指定的元素插入此队列(如果立即可行且不会违反容量限制),当使用有容量限制的队列时,此方法通常要优于 add(E),后者可能无法插入元素,而只是抛出一个异常。推荐使用此方法取代add
E remove(): 获取头部元素并且删除元素,不建议使用
E poll(): 获取头部元素并且删除元素,队列为空返回null;推荐使用此方法取代remove
E element(): 获取但是不移除此队列的头
E peek(): 获取队列头部元素却不删除元素,队列为空返回null
public void testQueue() {
Queue<String> queue = new LinkedList<String>();
queue.offer("1.你在哪儿?");
queue.offer("2.我在这里。");
queue.offer("3.那你又在哪儿呢?");
String str = null;
while ((str = queue.poll()) != null) {
System.out.println(str);
}
}
PriorityQueue: 保存队列元素的顺序并不是按照加入序列的顺序,是按照队内元素的大小重新排序,当你调用peek()或是poll(),返回队列中的最小元素。也可以自定义排序。
public void testPriorityQueue() {
PriorityQueue<Integer> pq = new PriorityQueue<Integer>(20, new Comparator<Integer>() {
public int compare(Integer i, Integer j) {
// 对数字进行奇偶分类,然后比较返回;偶数有较低的返回值(对2取余数然后相减),奇数直接相减。
int result = i % 2 - j % 2;
if (result == 0)
result = i - j;
return result;
}
});
// 倒序插入测试数据
for (int i = 0; i < 20; i++) {
pq.offer(20 - i);
}
// 打印结果,偶数因为有较低的值,所以排在前面
for (int i = 0; i < 20; i++) {
System.out.println(pq.poll());
}
}
Deque子接口
Deque代表一个双端队列,可以当作一个双端队列使用,也可以当作“栈”来使用,因为它包含出栈pop()与入栈push()方法。
ArrayDeque类是Deque的实现类,数组方式实现:
addFirst(Object o):元素增加至队列开头
addLast(Object o):元素增加至队列末尾
poolFirst():获取并删除队列第一个元素,队列为空返回null
poolLast():获取并删除队列最后一个元素,队列为空返回null
pop():“栈”方法,出栈,相当于removeFirst()
push(Object o):“栈”方法,入栈,相当于addFirst()
removeFirst():获取并删除队列第一个元素
removeLast():获取并删除队列最后一个元素
补充说明:
LinkedList类是List接口的实现类,同时它也实现了Deque接口。因此它也可以当做一个双端队列来用,也可以当作“栈”来使用。并且,它是以链表的形式来实现的,这样的结果是它的随机访问集合中的元素时性能较差,但插入与删除操作性能非常出色。
2.Map接口:映射表,核心思想是键值关联,存储键值对,key是唯一的
HashTable 集成map接口,实现一个key-value映射的哈希表。任何非空的对象都可以作为key或者value使用,是线程安全的。
HashMap : Map 基于散列表的实现(取代了Hashtable),插入和查询“键值对”的开销是固定的,可以通过设置容量和负载因子,调整容器的性能。HashMap结构的实现原理是将put进来的key-value封装成一个Entry对象存储到一个Entry数组中,位置(数组下标)由key的哈希值与数组长度计算而来。它的特点:1. 它是线程不安全的,允许null,即null value和null key;2. 它是无需的;3.HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。从下图中可以看出,HashMap底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个HashMap的时候,就会初始化一个数组。
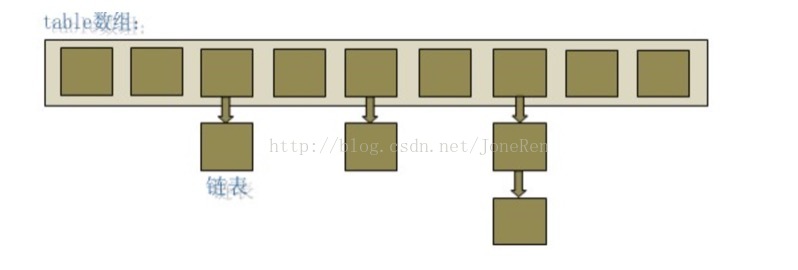
LinkedHashMap:类似于HashMap,是HashMap的子类,但是它迭代遍历时,取的“键值对”的顺序是其插入的顺序,或者是最少使(LRU)用的次序,只比HashMap慢一点,但是它的迭代速度更快,它是用来链表维护内部的次序。它的特点:1.底层结构是双向链表;2.有序摆列。
Properties: 是HashTable的子类,一般用来读取资源文件。资源文件后缀是.properties文件,内容采取的是键值对方式存储。
TreeMap :由Entry对象为节点组成的一颗红黑树,put到TreeMap的数据默认按key的自然顺序排序,new TreeMap时传入Comparator自定义排序。它是基于红黑树的实现,查看“键”或“键值对”时,它们会被排序(由Comparable或Comparator决定),得到的结果自然是排序的,它是唯一带有subMap()方法的Map,可以返回一个子书。
WeakHashMap 是一种改进的HashMap(),它对key实行“弱引用”,如果如果一个key不再被外部所引用,那么该key可以被GC回收
=====================================================》
一些使用方法的补充:
1.如何将List转化成int[]?
很多人可能认为只需用list.toArray()即可,其实不然。List.toArray()方法只可能得到Integer[],无法得到int[]。正确方法:
int[] array = new int[list.size()];
for(int i = 0; i < list.size(); i++){
array[i] = list.get(i);
}2.如何将int[]转化成List?
int[] array = {1,2,3,4,5};
List<Integer> list = new ArrayList<Integer>();
for(int i: array) {
list.add(i);
}3. 过滤一个Collection最好的方法是什么?
如过滤掉list中大于5的整数。
Iterator<Integer> it = list.iterator();
while(it.hasNext()){
int i = it.next();
if(i > 5) { //过滤掉大于5的整数
it.remove();
}
}有两种方法,取决于你怎么要怎么定义两个元素相等。第一种方法是将list放入HashSet里,该方法元素是否相等是通过它们的hashCode()来比较的。如果需要自己定义比较的方法,需要用TreeSet。
Set<Integer> set = new HashSet<Integer>(list);
Set<Integer> set = new TreeSet<Integer>(aComparator);
set.addAll(list);如果不关心元素在ArrayList中的顺序,可以将list放入set中来删除重复元素,然后在放回list。
Set<Integer> set = new HashSet<Integer>(list);
list.clear();
list.addAll(set);
如果关心元素在ArrayList中的顺序,可以用LinkedHashSet。6. 有序的collectionJava里有很多方法来维持一个collection有序。有的需要实现Comparable接口,有的需要自己指定Comparator。
1.Collections.sort()可以用来对list排序。该排序是稳定的,并且可以保证nlog(n)的性能。
2.PriorityQueue提供排序的队列。PriorityQueue和Collections.sort()的区别是,PriorityQueue动态维护一个有序的队列(每添加或删除一个元素就会重新排序),但是只能获队列中的头元素。
3.如果collection中没有重复的元素,TreeSet是另一个选择。跟PriorityQueue一样的是,TreeSet也动态维护一个有序的集合。可以从TreeSet中获取最大和最小的元素。
总结:Collections.sort()提供一个一次排序的list。PriorityQueue和TreeSet动态维护排序的collection。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









