







总结
utils.py里面的函数
都是封装了一下,
感觉没必要,
不清楚变量的shape和值就一个一个print输出
多看官方文档和里面的例子
【参考:模型训练、评估与推理-使用文档-PaddlePaddle深度学习平台】
项目一
本项目来源于:【参考:『NLP经典项目集』02:使用预训练模型ERNIE优化情感分析 - 飞桨AI Studio】
Stack,Pad,Tuple
注意,在早前的PaddleNLP版本中,token_type_ids叫做segment_ids
# 单句输入
single_seg_input = tokenizer(text="请输入测试样例")
# 句对输入
multi_seg_input = tokenizer(text="请输入测试样例1", text_pair="请输入测试样例2")
print("单句输入token (str): {}".format(tokenizer.convert_ids_to_tokens(single_seg_input['input_ids'])))
print("单句输入token (int): {}".format(single_seg_input['input_ids']))
# 注意,在早前的PaddleNLP版本中,token_type_ids叫做segment_ids
print("单句输入segment ids : {}".format(single_seg_input['token_type_ids']))
print()
print("句对输入token (str): {}".format(tokenizer.convert_ids_to_tokens(multi_seg_input['input_ids'])))
print("句对输入token (int): {}".format(multi_seg_input['input_ids']))
print("句对输入segment ids : {}".format(multi_seg_input['token_type_ids']))

Dataset
from functools import partial
from paddlenlp.data import Stack, Tuple, Pad
from utils import convert_example, create_dataloader
# 模型运行批处理大小
batch_size = 32
max_seq_length = 128
#使用partial()来固定convert_example函数的tokenizer, label_list, max_seq_length, is_test等参数值
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
# 对获取的批次数据进行处理
batchify_fn = lambda samples, fn=Tuple(
# 这里要和返回的data 里面的数据相对应,data里面有三个值,下面就写三个
# axis=0 按行堆叠 pad_val:填充值
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack(dtype="int64") # label
): [data for data in fn(samples)] # samples每个batch的数据,类型List[List[]],data类型为 List[]
train_data_loader = create_dataloader(
train_ds, # MapDataset
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
【参考:“此苹果非彼苹果”看意图识别的那些事儿】
3.调用map()方法批量处理数据
由于我们传入了lazy=False,所以我们使用load_dataset()自定义的数据集是MapDataset对象。
MapDataset是paddle.io.Dataset的功能增强版本。其内置的map()方法适合用来进行批量数据集处理。
map()方法传入的是一个用于数据处理的function。正好可以与tokenizer相配合。
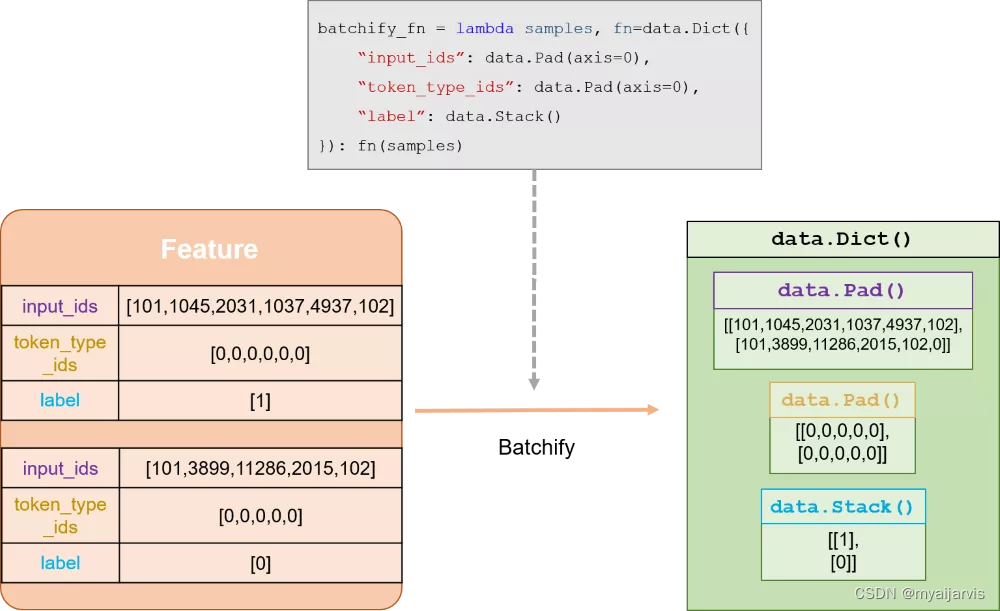
4.Batchify和数据读入
使用paddle.io.BatchSampler和paddlenlp.data中提供的方法把数据组成batch。
然后使用paddle.io.DataLoader接口多线程异步加载数据。
Batchify功能详解:
utils.py
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
def predict(model, data, tokenizer, label_map, batch_size=1):
"""
Predicts the data labels.
Args:
model (obj:`paddle.nn.Layer`): A model to classify texts.
data (obj:`List(Example)`): The processed data whose each element is a Example (numedtuple) object.
A Example object contains `text`(word_ids) and `seq_len`(sequence length).
tokenizer(obj:`PretrainedTokenizer`): This tokenizer inherits from :class:`~paddlenlp.transformers.PretrainedTokenizer`
which contains most of the methods. Users should refer to the superclass for more information regarding methods.
label_map(obj:`dict`): The label id (key) to label str (value) map.
batch_size(obj:`int`, defaults to 1): The number of batch.
Returns:
results(obj:`dict`): All the predictions labels.
"""
examples = []
for text in data:
input_ids, segment_ids = convert_example(
text,
tokenizer,
max_seq_length=128,
is_test=True)
examples.append((input_ids, segment_ids))
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input id
Pad(axis=0, pad_val=tokenizer.pad_token_id), # segment id
): fn(samples)
# Seperates data into some batches.
batches = []
one_batch = []
for example in examples:
one_batch.append(example)
if len(one_batch) == batch_size:
batches.append(one_batch)
one_batch = []
if one_batch:
# The last batch whose size is less than the config batch_size setting.
batches.append(one_batch)
results = []
model.eval()
for batch in batches:
input_ids, segment_ids = batchify_fn(batch)
input_ids = paddle.to_tensor(input_ids)
segment_ids = paddle.to_tensor(segment_ids)
logits = model(input_ids, segment_ids)
probs = F.softmax(logits, axis=1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
results.extend(labels)
return results
@paddle.no_grad()
def evaluate(model, criterion, metric, data_loader):
"""
Given a dataset, it evals model and computes the metric.
Args:
model(obj:`paddle.nn.Layer`): A model to classify texts.
data_loader(obj:`paddle.io.DataLoader`): The dataset loader which generates batches.
criterion(obj:`paddle.nn.Layer`): It can compute the loss.
metric(obj:`paddle.metric.Metric`): The evaluation metric.
"""
model.eval()
metric.reset() # 重置
losses = []
for batch in data_loader:
input_ids, token_type_ids, labels = batch
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
losses.append(loss.numpy())
correct = metric.compute(logits, labels)
metric.update(correct)
accu = metric.accumulate()
print("eval loss: %.5f, accu: %.5f" % (np.mean(losses), accu))
model.train() # 继续训练
metric.reset()
def convert_example(example, tokenizer, max_seq_length=512, is_test=False):
"""
Builds model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens. And creates a mask from the two sequences passed
to be used in a sequence-pair classification task.
A BERT sequence has the following format:
- single sequence: ``[CLS] X [SEP]``
- pair of sequences: ``[CLS] A [SEP] B [SEP]``
A BERT sequence pair mask has the following format:
::
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
If only one sequence, only returns the first portion of the mask (0's).
Args:
example(obj:`list[str]`): List of input data, containing text and label if it have label.
tokenizer(obj:`PretrainedTokenizer`): This tokenizer inherits from :class:`~paddlenlp.transformers.PretrainedTokenizer`
which contains most of the methods. Users should refer to the superclass for more information regarding methods.
max_seq_len(obj:`int`): The maximum total input sequence length after tokenization.
Sequences longer than this will be truncated, sequences shorter will be padded.
is_test(obj:`False`, defaults to `False`): Whether the example contains label or not.
Returns:
input_ids(obj:`list[int]`): The list of token ids.
token_type_ids(obj: `list[int]`): List of sequence pair mask.
label(obj:`numpy.array`, data type of int64, optional): The input label if not is_test.
"""
encoded_inputs = tokenizer(text=example["text"], max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
return input_ids, token_type_ids
def create_dataloader(dataset,
mode='train',
batch_size=1,
batchify_fn=None,
trans_fn=None):
if trans_fn:
# 相当于给convert_example函数传入example=dataset(dataset:paddlenlp.datasets.dataset.MapDataset, dataset.data:List[str])
# 【参考:[dataset — PaddleNLP 文档](https://paddlenlp.readthedocs.io/zh/latest/source/paddlenlp.datasets.dataset.html)】
# MapDataset下有map函数,默认给fn传入一个single sample
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False #如果不是训练集,则不打乱顺序
if mode == 'train':
# DistributedBatchSampler 分布式批采样器加载数据
batch_sampler = paddle.io.DistributedBatchSampler(
dataset, batch_size=batch_size, shuffle=shuffle)
else:
# 生成一个取样器
batch_sampler = paddle.io.BatchSampler(
dataset, batch_size=batch_size, shuffle=shuffle)
return paddle.io.DataLoader(
dataset=dataset,
batch_sampler=batch_sampler, # 批次采样
collate_fn=batchify_fn, # 对抽取的批次数据进行处理
return_list=True) # 返回List
项目二
【参考:『NLP经典项目集』01:seq2vec是什么? 瞧瞧怎么用它做情感分析_副本 - 人工智能学习与实训社区】
使用高阶API训练
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from collections import defaultdict
import re
from paddlenlp import Taskflow
import numpy as np
import paddle
word_segmenter = Taskflow("word_segmentation") # 分词器
def create_dataloader(dataset,
trans_fn=None,
mode='train',
batch_size=1,
batchify_fn=None):
"""
Creats dataloader.
Args:
dataset(obj:`paddle.io.Dataset`): Dataset instance.
trans_fn(obj:`callable`, optional, defaults to `None`): function to convert a data sample to input ids, etc.
mode(obj:`str`, optional, defaults to obj:`train`): If mode is 'train', it will shuffle the dataset randomly.
batch_size(obj:`int`, optional, defaults to 1): The sample number of a mini-batch.
batchify_fn(obj:`callable`, optional, defaults to `None`): function to generate mini-batch data by merging
the sample list, None for only stack each fields of sample in axis
0(same as :attr::`np.stack(..., axis=0)`).
Returns:
dataloader(obj:`paddle.io.DataLoader`): The dataloader which generates batches.
"""
# 相当于给convert_example函数传入example=dataset(dataset:paddlenlp.datasets.dataset.MapDataset, dataset.data:List[str])
# 【参考:[dataset — PaddleNLP 文档](https://paddlenlp.readthedocs.io/zh/latest/source/paddlenlp.datasets.dataset.html)】
# MapDataset下有map函数,默认给fn传入一个single sample
if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False # 如果不是训练集,则不打乱顺序
if mode == "train":
# DistributedBatchSampler 分布式批采样器加载数据
sampler = paddle.io.DistributedBatchSampler(
dataset=dataset, batch_size=batch_size, shuffle=shuffle)
else:
# 生成一个取样器
sampler = paddle.io.BatchSampler(
dataset=dataset, batch_size=batch_size, shuffle=shuffle)
dataloader = paddle.io.DataLoader(
dataset,
batch_sampler=sampler, # 批次采样
collate_fn=batchify_fn) # 对抽取的批次数据进行处理
return dataloader
# 数据转换 str->int
def convert_example(example, tokenizer, is_test=False):
"""
Builds model inputs from a sequence for sequence classification tasks.
It use `jieba.cut` to tokenize text.
Args:
example(obj:`list[str]`): List of input data, containing text and label if it have label.
tokenizer(obj: paddlenlp.data.JiebaTokenizer): It use jieba to cut the chinese string.
is_test(obj:`False`, defaults to `False`): Whether the example contains label or not.
Returns:
input_ids(obj:`list[int]`): The list of token ids.
valid_length(obj:`int`): The input sequence valid length.
label(obj:`numpy.array`, data type of int64, optional): The input label if not is_test.
"""
input_ids = tokenizer.encode(example["text"])
valid_length = np.array(len(input_ids), dtype='int64')
input_ids = np.array(input_ids, dtype='int64')
if not is_test:
label = np.array(example["label"], dtype="int64")
return input_ids, valid_length, label
else:
return input_ids, valid_length
def preprocess_prediction_data(data, tokenizer):
"""
It process the prediction data as the format used as training.
Args:
data (obj:`List[str]`): The prediction data whose each element is a tokenized text.
tokenizer(obj: paddlenlp.data.JiebaTokenizer): It use jieba to cut the chinese string.
Returns:
examples (obj:`List(Example)`): The processed data whose each element is a Example (numedtuple) object.
A Example object contains `text`(word_ids) and `seq_len`(sequence length).
"""
examples = []
for text in data:
ids = tokenizer.encode(text)
examples.append([ids, len(ids)])
return examples
# 构建词汇表
def build_vocab(texts,
stopwords=[],
num_words=None,
min_freq=10,
unk_token="[UNK]",
pad_token="[PAD]"):
"""
According to the texts, it is to build vocabulary.
Args:
texts (obj:`List[str]`): The raw corpus data.
num_words (obj:`int`): the maximum size of vocabulary.
stopwords (obj:`List[str]`): The list where each element is a word that will be
filtered from the texts.
min_freq (obj:`int`): the minimum word frequency of words to be kept.
unk_token (obj:`str`): Special token for unknow token.
pad_token (obj:`str`): Special token for padding token.
Returns:
word_index (obj:`Dict`): The vocabulary from the corpus data.
"""
word_counts = defaultdict(int) # defaultdict默认找不到键时返回默认值,int对应0
for text in texts:
if not text: # text为None时
continue
for word in word_segmenter(text): # word_segmenter(text) 返回一个分词后的列表
if word in stopwords: # 去停用词
continue
word_counts[word] += 1
wcounts = []
for word, count in word_counts.items():
if count < min_freq: # 词的频率小于min_freq
continue
wcounts.append((word, count))
wcounts.sort(key=lambda x: x[1], reverse=True) # 按照词的频率递减排序(高频排前面)
# -2 for the pad_token and unk_token which will be added to vocab.
if num_words is not None and len(wcounts) > (num_words - 2):
wcounts = wcounts[:(num_words - 2)] # 取频率最大的前num_words - 2个
# add the special pad_token and unk_token to the vocabulary
sorted_voc = [pad_token, unk_token]
sorted_voc.extend(wc[0] for wc in wcounts) # 获取词典中所有的词
# list(range(len(sorted_voc)))) 根据sorted_voc的长度生成[1,...len]的序列,序列的值即为词的编号
# zip返回一个tuple,然后依据这个tuple生成字典
word_index = dict(zip(sorted_voc, list(range(len(sorted_voc)))))
return word_index















 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









