






© 作者|周远航
机构|中国人民大学硕士一年级
研究方向 | 推荐系统
1. 引语
最近,transformer 结构的模型在 ImageNet-1k 中取得了优异的表现。回顾历史,CV 任务的网络结构,存在往最少先验方向发展的发展趋势:早期基于手工设计的方法,需要大量的手工选择;CNN 抛弃了大量的手工选择,使用自动学习参数的卷积核;而最近的 Vision Transformer 则避免了对卷积结构固有的假设,并且显著避免了平移不变性。[1]
同样一篇论文[2]指出,随着数据量的增加和计算能力的提高,神经网络的模式不断变化。其中一个趋势是不断移模型中的除手工设计与 Inductive bias,让模型自动从原始数据中学习。
在这个去 Inductive bias 浪潮中,出现了若干篇使用 MLP 构建神经网络,并在现代大型数据集上取得不错效果的的论文,本文将对部分论文进行解读。
2. CV
2.1 Inductive bias
2.1.1 什么是 Inductive bias
Inductive bias 是指在通过人为偏好,认为某一种解决方案优先于其他解决方案。这里的解决方案既可以指数据假设上,也可以指模型设计等。在深度学习时代,卷积神经网络认为信息具有空间局部性,可以用滑动卷积共享权重方式降低参数空间和提高性能;循环神经网络强调时序信息时间顺序的重要性;图神经网络则是认为中心节点与邻居节点的相似性会更好引导信息流动。可以说深度学习时代,不同网络结构的创新就体现了不同的归纳性偏。
2.1.2 图像数据的 Inductive bias
Local prior
图像具有 locality(局域性),例如一个像素与它邻近的像素更相关,与它远离的像素更不相关。
Global capacity
图像还具有 long-rangeS dependencies,例如一个像素与距离更远的像素同属于一个物体的相关性。
Positional prior
有些图像有 positional prior,例如人脸图片中,脸一般在图像中间位置,眼睛总是在脸部上方,嘴巴总是在脸部下方。
2.2 CV任务的网络结构
2.2.1 MLP
MLP 的工作模式可以是这样的:将 feature map 展开成一维向量,通过 FC层,最终再 reshape 成原来 feature map 的形状。因为 FC 的参数的作用是与位置相关的,因此 FC 就有建模 positional prior 的能力。又因为输出 feature map 的每一个点都与输入 feature map 的每一个点有关,所以 FC 也有捕捉 long-range dependencies 的能力。
2.2.2 CNN
CNN 通过手工设计卷积核尺寸、个数、stride 等超参数,进而在数据上自动学习卷积核参数。CNN 具有捕捉 local prior 的能力,在图像识别任务中取得成功。但是传统的 CNN 只能通过加深卷积层数、增大感受野来建模 long-range dependencies。这种建模 long-range dependencies 的模式效率较低,并且可能导致优化困难。
2.2.3 Transformer
Transformer 最早被用于 NLP 任务。最近 ViT[3] 等论文将 Transformer 用于 CV,取得了成功。Transformer 中的 self-attention,具有 global capacity 和 positional prior,MLP-Blocks 具有 global capacity。但是由于 Vision Transformer 不具有建模 local prior 的能力,因此需要大量的训练数据。最近这些基于 Transformer 的研究表明,更长的训练时间、更多的参数、更多的数据和或更多的正则化,就足以恢复像 ImageNet 分类这样复杂任务的重要先验。
3. RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
由于 MLP 具有建模 long-range dependencies 和 positional prior 的能力, 而 CNN 具有建模 local prior 的能力,因此这篇论文[4]将 MLP 与 CNN 联合使用,提高多种计算机视觉任务的性能。
3.1 Contribution
首先,为了更好地完成图像分类任务,论文提出使用具有 global capacity 和 positional perception 的 FC,但是需要为 FC 增加 local prior
接着,论文提出了结构化重参数技术。训练时构建卷积层和 BN 层,推理时将卷积层、BN 层合并入 FC 层,给 FC 带来 local prior
最后,论文提出了 RepMLP,一种由具有 local prior 的 FC 构成的高效模块,可以作为传统卷积网络的通用组件,实现多种视觉任务效果提升
3.2 模型
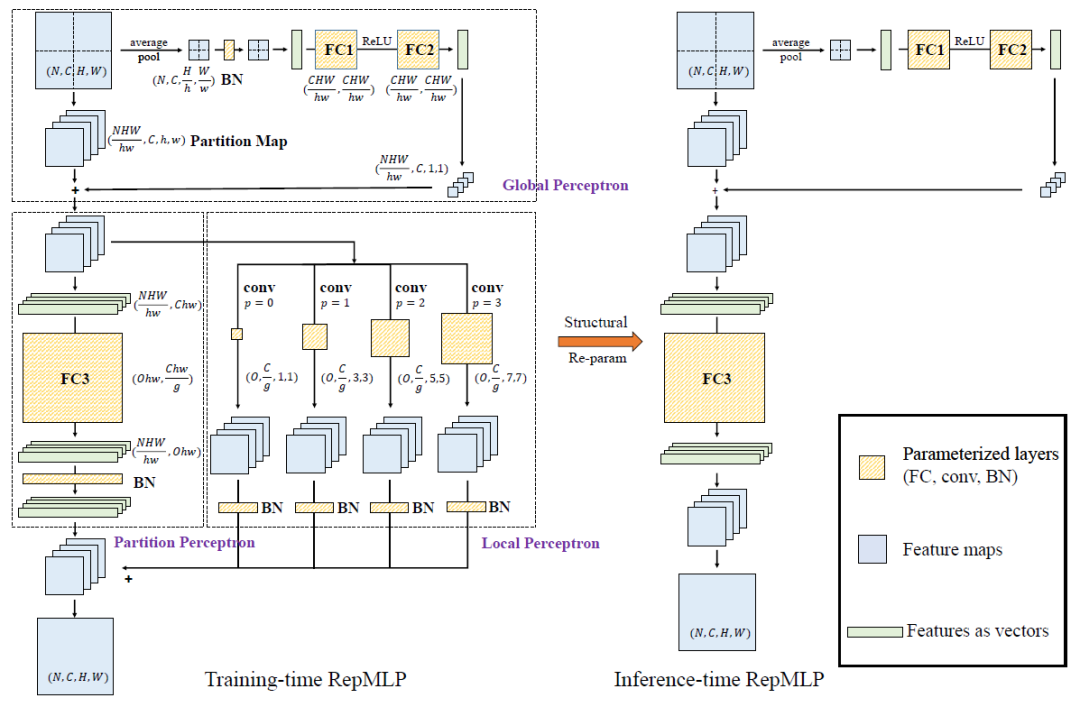
由于使用了结构化重参数技术,模型在训练和推理时是不一样的。
训练时,RepMLP 会同时使用 FC 和 conv。此时 RepMLP 由三部分构成:Global Perceptron、Partition Perceptron、Local Perceptron。输入的 feature map 被分割成一组 partition。首先 Global Perceptron 将 partition 之间的相关性添加到每个 partition 上。然后 Local Perceptron 使用数个 conv 层捕获 Local Perceptron。而 Partition Perceptron 对 long-range dependencies 进行建模。
推理时,通过结构化重参数技术,将 conv 层和 BN 层的等效转换为 FC 层,降低参数量,减少推理时间消耗。
3.3 实验
论文做了两类实验,第一类是证明 RepMLP 各模块的的有效性,第二类是 RepMLP 如何与传统的 ConvNet 组合,提高性能。
论文首先在 CIFAR-10 数据集上通过测试一个 pure MLP 来验证 RepMLP 的有效性。主要结果如下:
(1)相比 Wide ConvNet,pure MLP 的 Accuracy 略低但非常相近,计算量更低,参数量更多
(2)RepMLP 中的 Global Perceptron、Partition Perceptron、Local Perceptron 均是有效的
(3)RepMLP 中的 FC 与 conv 都是有效的,无法相互替代
论文又在图像分类、人脸识别、语义分割任务上进行实验,主要结果如下:
(1)RepMLP 模块替换 ResNet 中的模块(下文称为 RepMLP-ResNet)会导致参数量的增加和轻微的减速
(2)相同参数量的 ResNet 与 RepMLP-ResNet,RepMLP-ResNet 速度更快
(3)在传统 ConvNet 中插入 RepMLP,可以提高精度:论文在 ImageNet 上将 ResNets 提高了 1.8% 的 Top-1 准确率,在人脸识别任务上提高了 2.9% 的准确率,在 Cityscapes with lower FLOPs 上提高了 2.3% 的 mIoU。
3.4 总结
论文将 FC 的 global capacity 和 positional perception 与卷积的 local prior 相结合,可以使神经网络在具有平移不变性(例如,语义分割)、对齐的图像和位置模式(例如,人脸识别)的任务上有更高的性能、更快的速度。
对于 FC 与 conv 的关系,论文认为一个 FC 比一个 conv 具有更强的表示能力,因为后者可以被视为一个具有共享参数的稀疏 FC。从理论角度看,将卷积网络视为 FC 的退化案例,开辟了一个新的视角,可以加深对传统卷积网络的理解。
RepMLP 是为主要关注推断吞吐量和准确性,而不太关心参数数量的应用程序场景设计的。
4. MLP-Mixer: An all-MLP Architecture for Vision
这篇文章来自 Google Brain (许多作者来自 ViT 团队),提出了一个只使用 MLP 的网络结构 MLP-Mixer,该结构可以取得与 CNN、Transformer 相似的性能。
4.1 特征混合方式
这篇论文按照特征混合方式分析各种网络架构。论文指出,用于视觉的神经网络架构由混合特征的神经网络层组成,这些神经网络层混合特征的方式有两种:
(1)在一个给定的空间位置,混合不同 channel 的特征。
(2)在不同的空间位置混合特征。
对于 CNN:
1*1 卷积会混合同一个特征点不同通道的特征。
N*N 卷积(N>1)和 pooling 会混合不同位置的特征,并且随着层数的增加,卷积和 pooling 的感受野越大,混合的特征数量越多。
对于 Vision Transformers 和其他基于 attention 的架构:
在图像的 patches 上做 self-attention,可以混合给定空间位置的特征,也可以混合不同空间位置的特征。MLP-blocks 只能混合给定位置的特征
MLP 的不同使用方法具有不同的特征混合方式。
channel-mixing MLP:将一个空间位置的不同 channel 上的特征 reshape 成一个向量,然后通过一个 FC。这样的 MLP 使用方法可以混合给定空间位置的特征。
token-mixing MLP:将同一 channel 上不同空间位置的特征 reshape 成一个向量,通过一个 FC。这样的 MLP 使用方法可以混合不同空间位置同一 channel 的特征。
本文的理念就是明确地分离 channel-mixing 和 token-mixing 两种 MLP 方法,并且在 MLP-Mixer 中交替使用,使基于 MLP 的 MLP-Mixer 架构既可以混合给定空间位置的特征,也可以混合不同空间位置的特征。
4.2 模型
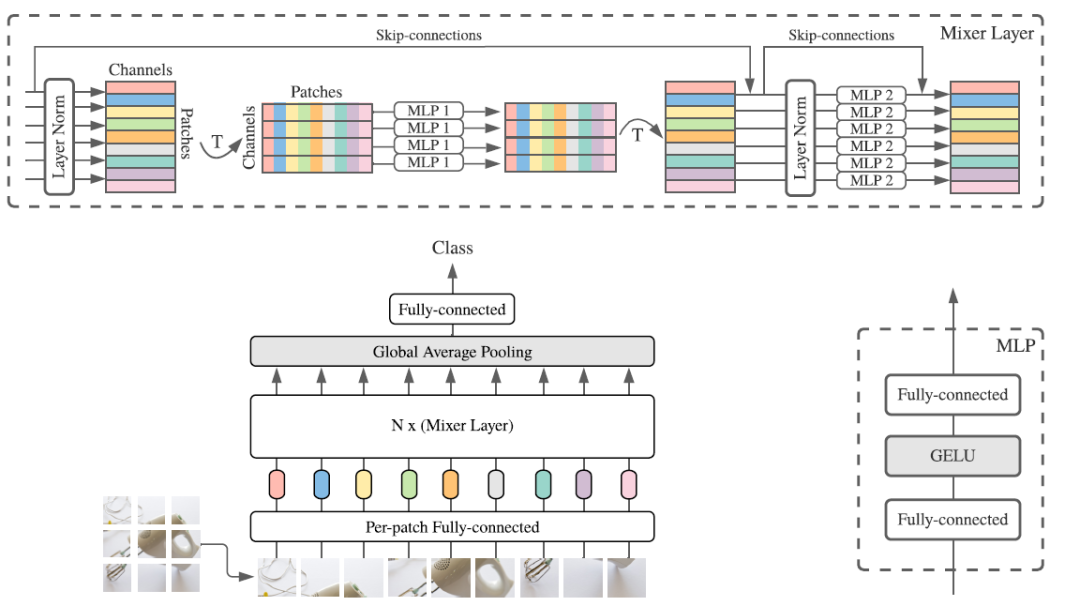
首先将图像分割为 S 个不重叠的 patch,每个 patch 被映射为 C 维的向量,由此我们得到了模型的输入 。 的一行可以看作同一 patch 的不同 channel,一列可以看作不同 patch 的同一 channel。
Mixer 由多层相同尺寸的 layer 组成。每个 layer 由 token-mixing MLP block 和 channel-mixing MLP block 组成。Token-mixing MLP block 作用于 的列,从 映射到 。Channel-mixing MLP block 作用于 的行,从 映射到 。
两种 block 的数学定义如下:
其中 表示 GELU 激活函数。 分别表示 token-mixing 与 channel-mixing MLP 中隐层宽度。需要注意的是, 的选择独立于输入图像 patch 的数量 S。因此,网络的计算量与输入 patch 数量成线性关系,而 ViT 里是二次关系。 的选择独立于图像 patch 尺寸,因此,网络计算量与图像的像素数成线性关系,类似于 CNN。
由于相同的 channel(token)-mixing MLP 单独作用于 的每一行(列)。对 MLP 的参数进行绑定就是一种自然的选择,它可以提供类似卷积特征的 positional invariance。这种参数绑定可以避免架构(的参数量)随隐层维度 C、patch 个数 S 提升而增长过快,进而节省显存消耗。在论文附录 A.1 中说明了这种参数绑定机制并不会影响性能。
注意 Mixer 并没有采用 position embedding,这是因为 token-mixing MLP 对于输入的顺序极为敏感。Mixer 中的每一层采用相同尺寸的输入,这种“各向同性”设计类似于 Transformer 和 RNN;这与 CNN 中金字塔结构(越深的层具有更低的分辨率、更多的通道数)不同。
4.3 实验
论文中的主要实验结果如下:
MLP-Mixer 在 lmageNet 数据集可以取得非常强的性能: 84.15% top1,比其他模型稍弱。
提升上游数据集尺寸后,MLP-Mixer 的性能可以进一步提升。
随预训练数据集变大,MLP-Mixer 的性能稳步提升。
相比 ViT 等模型,MLP-Mixer 可以保持精度下降很少时,大幅提高推理速度。
4.4 总结
论文所提方法在准确率和计算资源消耗的 trade-off 达到了优秀水平
论文作者希望所提模型能够帮助探索不同模型学到特征的不同点
论文作者也希望了解隐藏在这些不同特征中的 Inductive bias,以及最终它们在泛化中的作用
5. ResMLP: Feedforward networks for image classification with data-efficient training
这篇论文也提出了一种完全基于 MLP 的神经网络架构 ResMLP 用于图像分类。同 MLP-Mixer 类似,它是一个交替执行如下两个模块的简单残差网络:(1) 一个作用于图像块的线性层,独立于通道;(2) 一个作用于通道的两层前馈网络,独立于图像块。
5.1 模型

论文提出的 ResMLP 架构以 个非重叠的图像 patch 作为输入,这些块将独立的 patch 经由线性层处理并构成 维嵌入特征;所得嵌入特征将送入后续一系列 Residual Multi-Perceptron Layer 中生成 维输出嵌入特征;将上述输出嵌入特征进行平均得到 维图像表达;最后将上述图像表达送入线性分类层预测图像对应的标签。
论文提出的架构由多个 Residual Multi-Perceptron Layer 组成。一个 Residual Multi-Perceptron Layer 由线性层后接前馈层构成。类似 Transformer Layer,每个子层采用了跳过连接并行,但并未采用 LayerNorm,这是因为采用如下仿射变换训练已经非常稳定:
其中, 表示可学习向量。因为参数可与线性层合并,所以该层在推理时不消耗时间。 独立的作用于 的每一列,尽管与 BatchNorm、LayerNorm 非常类似,但该操作不依赖任何 batch 统计。
Residual Multi-Perceptron Layer 将 维输入特征 reshape 为 矩阵 ,输出 维输出特征,其公式如下:
其中, 表示主要的学习参数。参数矩阵 的维度维 ,用于混合所有位置的信息,而前馈层则作用于每个位置。因此,中间激活矩阵 Z 具有与矩阵 X、Y 相同的维度。参数矩阵 的维度类似 Transformer 层: 。
5.2 实验
论文主要的实验与实验结果如下:
将 ResMLP 与 Transformer、convnet 在监督学习框架下进行了比较,ResMLP 取得了相对不错的 Top-1 准确率
与 DeiT 模型类似,ResMLP 可以从 convnet 蒸馏中显著获益。
论文评估了 ResMLP 在迁移学习方面的性能。
论文探讨了 MLP 的过拟合控制情况
5.3 总结
论文所提架构与 Transformer 的主要区别在于:所提架构受启发于 ViT,但更简单,没有采用任何形式的注意力,仅仅包含线性层与 GELU 非线性激活函数。
论文作者希望空间无先验模型有助于进一步理解哪些网络具有更少的先验学习,并有可能指导未来网络的设计选择,而不采用大多数卷积神经网络所采用的金字塔设计。
6. 结语
过去一段时间,深度神经网络在不断添加 Inductive bias,以求降低对数据、计算设备、优化技术的依赖。但是由于可用数据集的规模不断扩大、计算能力的不算提高,神经网络的设计有了减少 Inductive bias,转而从原始数据中学习的趋势。
在这个趋势中,出现了一些重新考虑 MLP 的论文,有些论文[1, 2]只使用 MLP 构建神经网络,有些论文[3]将 MLP 与旧的神经网络结构结合,有些论文[5]揭示 MLP 与已有技术的关联。
MLP 具有一些缺陷,比如只能接受尺寸固定的输入、缺乏建模 local prior 能力,现有论文也没有用 MLP 颠覆已有的网络架构。但是当前人们对 MLP 的探索,会激发人们对 Inductive bias 的进一步了解,推动神经网络架构的设计的新想法。
参考文献
[1] Hugo Touvron et al. ResMLP: Feedforward networks for image classification with data-efficient training
[2] Ilya Tolstikhin et al. MLP-Mixer: An all-MLP Architecture for Vision
[3] Dosovitskiy et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[4] Xiaohan Ding et al. RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
[5]Meng-hao Guo et al. Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),关注公众号回复『入群』加入吧!
- END -





















 33万+
33万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









