






双塔各种改造方法概览:
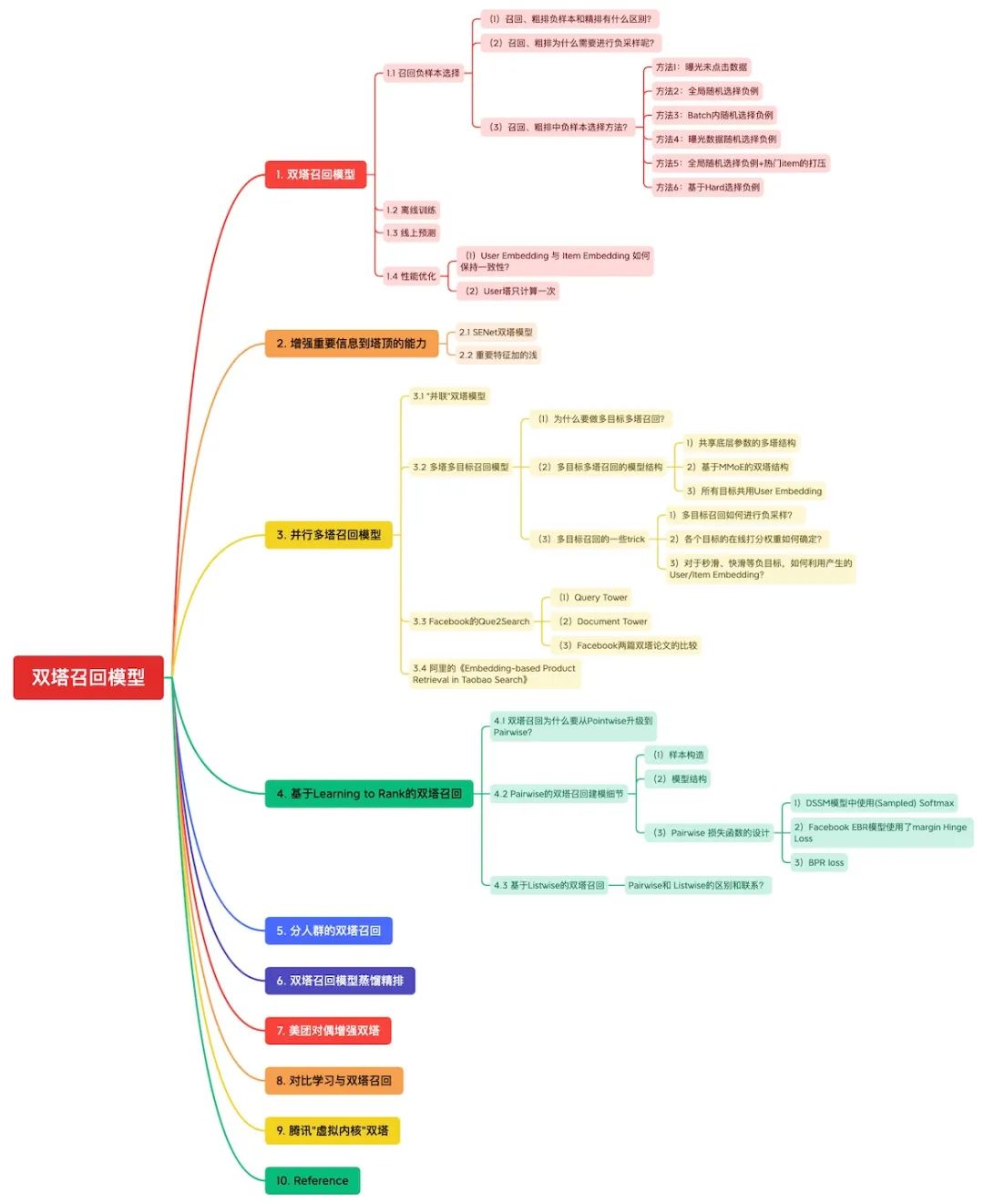
大型推荐系统通常会将整个推荐链路拆分成召回、粗排、精排和重排等多个模块,以达到推荐效果和计算性能之间的平衡。
由于召回模型的候选item通常是海量的全库物品、粗排模型的候选item是上百路召回合并后的物品集,在面临海量候选物品进行粗筛的场景下,双塔结构不仅排序速度快、模型线上效果也不差,且在工业界实战价值很高,因此双塔结构在召回和粗排环节的模型选型中被广泛采用。
Microstrong从事推广搜行业也有数年,对双塔结构在工业界的落地及改造升级,并在线上拿到较高的业务增长,有些许的心得体会。本文是Microstrong对双塔模型在推荐系统召回阶段所看、所思、所做、所想的一些总结。
1. 双塔召回模型
我把双塔召回模型样本处理、离线训练、线上部署、性能优化总结如下:
1.1 召回负样本选择
如果说排序是特征的艺术,那么召回、粗排就是样本的艺术,特别是负样本的艺术。我这里提三个不做召回、粗排方向的同学经常会问的问题:
(1)召回、粗排负样本和精排有什么区别?
我们训练精排模型的时候(假设是优化点击目标),一般会用“用户点击”实例做为正例,“曝光未点击”实例做为负例,来训练模型,基本大家都是这么干的。现在,召回以及粗排,也需要训练模型,意思是说,也需要定义正例和负例。一般正例,也都是用“用户点击”实例做为正例,但是怎么选择负例,这里面有不少学问。
精排:正样本为真实点击,负样本为真实曝光未点击。
粗排:一般情况下和精排样本一致,但这会造成一个问题:粗排训练样本和实际线上打分样本分布不一致,训练样本仅是线上打分样本一个比较小的子集。面对这个问题大家通常的解法是,从精排未下发的样本里采一部分,添加至粗排模型的训练负样本中,会带来一定的提升。即粗排也需要进行负采样。
召回:正样本为真实点击,负样本为真实曝光未点击+「负采样」。
(2)召回、粗排为什么需要进行负采样呢?
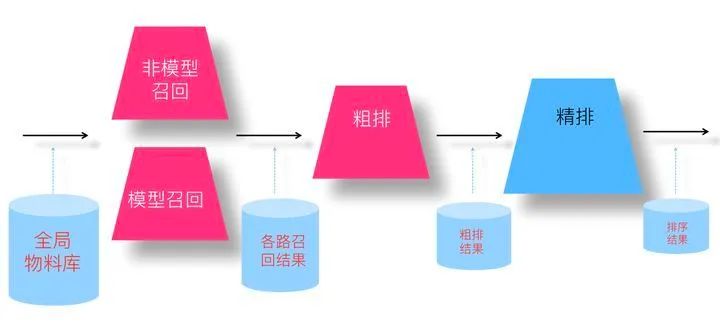
图来源:SENet双塔模型:在推荐领域召回粗排的应用及其它 - 张俊林的文章 - 知乎https://zhuanlan.zhihu.com/p/358779957
我们先来看下不同阶段模型面对的输入数据情况,对于召回模型来说,它面临的输入数据,是所有物料库里的物品;对于粗排模型来说,它面对的输入数据,是各路召回的结果;对于精排模型来说,它面临的输入是粗排模型的输出结果。如果我们仍然用“曝光未点击”实例做为召回和粗排的负例训练数据,你会发现这个训练集合,只是全局物料库的一小部分,它的分布和全局物料库以及各路召回结果数据分布都不一致。召回和粗排模型面临的实际输入数据与“曝光未点击”作为负例的训练数据有较大的分布差异,所以只用“曝光未点击”这种负例训练召回和粗排模型,效果如何就带有疑问,我们一般把这个现象称为“Sample Selection Bias”问题。
可以看到召回、粗排是要做采样,其原因是:离线训练数据要和线上分布尽可能一致,虽然曝光未点击肯定是负样本,但是还有很多物品未曝光,同时因为推荐系统bias的存在可能某些样本你永远学不到,负采样的目的就是尽量符合线上真实分布,要让模型“见见世面“。
(3)召回、粗排中负样本选择方法?
「方法1:曝光未点击数据。」
常用的方式,但是会导致Sample Selection Bias。我们的经验是,这个数据还是需要的,只是要和其它类型的负样本选择方法,按照一定比例进行混合,来缓解Sample Selection Bias问题。当然,有些结论貌似是不用这个数据,所以用还是不用,可能跟应用场景有关。
「方法2:全局随机选择负例。」
从全局候选物料里面随机抽取item做为召回或者粗排的负例。例如经典论文《Deep Neural Networks for YouTube Recommendations》中的Youtube DNN模型。虽然保证了输入数据的分布一致性,但这么选择的负例和正例差异太大,导致模型太好区分,可能学到的知识不够充分。
「方法3:Batch内随机选择负例。」
输入数据只有用户点击物品的正样本。训练的时候,在Batch内随机采样一定比例除本item外的其它item作为当前用户的负样本。这个本质上是:给定用户,在所有其它用户的正例里进行随机选择,构造负例。它在一定程度上,也可以解决Sample Selection Bias问题。比如经典论文《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》中的Google双塔召回模型,就是用的这种负例方法。
《Mixed Negative Sampling for Learning Two-tower Neural Networks in Recommendations》提出了一种混合采样的策略。负样本既包括batch内采样,即相当于做unigram分布采样,另外也会对全部物料做均匀分布的随机采样,同时混合两种样本。负样本同时拼接batch内负样本和随机负样本。通过这种方式来对负样本的分布进行调整。训练的时候,每个batch只采样一次并共享同一批负样本。详细细节请参考:Google Play双塔召回算法 - 张备的文章 - 知乎 https://zhuanlan.zhihu.com/p/533449018
「方法4:曝光数据随机选择负例。」
就是说,在给所有用户曝光的数据里,随机选择做为负例。这个我们测试过,在某些场景下是有效的。
「方法5:全局随机选择负例+热门item的打压。」
全局随机选择负例是:拿点击样本做正样本,拿从全局候选物料里面随机抽取item做为召回或粗排的负样本。这种负采样方法是有效的,因为线上召回时,候选库里大多数的物料是与用户八杆子打不着的,随机抽样能够很好地模拟这一分布。
但是这里要特别注意 "随机抽样的概率",千万不要以为是在整个候选库里等概率抽样。在任何一个推荐系统中,都难逃“2-8”定律的影响,即20%的热门item占据了80%的曝光量或点击量,也就是少数热门物料占据了绝大多数的曝光与点击。
这样一来,正样本被少数热门物料所绑架,导致所有人的召回结果都集中于少数热门物料,完全失去了个性化。因此,当热门物料做正样本时,要降采样,减少对正样本集的绑架。比如,某物料成为正样本的概率,其中点击过的用户数同时段所有发生过点击行为的用户总数,是一个超参一般在1e-3~1e-5之间。
当热门物料做负样本时,就要提升热门item成为负样本的概率。可以从两个角度来理解:
1)既然热门item已经“绑架”了正样本集,我们也需要提高热门item在负样本集中的比例,以抵销热门item对loss的影响;
2)如果在采样生成负样本时采取uniform sampling,因为有海量的候选item,而采样量有限,因此极有可能采样得到的item与user“八杆子打不着”,即所谓的easy negative。而如果多采集一些热门item当负样本,因为绝大多数用户都喜欢热门item,这样采集到的负样本是所谓的hard negative,会极大地提升模型的分辨能力。
要适当过采样,抵销热门物料对正样本集的绑架。同时,也要保证冷门物料在负样本集中有出现的机会。比如,某物料成为负样本的概率。其中是点击过第个物料的用户总数,而一般取。
有NLP背景的同学会发现,以上采集正负item时所使用概率公式,与word2vec中所使用公式一模一样。没错,Language Model中根据“上下文”预测“缺失词”的问题,其实就可以看成一个召回问题。因此,word2vec中处理高频词的方式,也可以拿来为我们所用,在召回中打压高热item。
「方法6:基于Hard选择负例。」
Hard Negative能够增加模型在训练时的难度,让模型关注细节。Airbnb根据业务逻辑来选取Hard Negative:
1)增加与正样本同城的房间作为负样本,增强了正负样本在地域上的相似性,加大了模型的学习难度。
2)增加“被房主拒绝”作为负样本,增强了正负样本在“匹配用户兴趣爱好”上的相似性,加大了模型的学习难度。
2020年Facebook的论文《Embedding-based Retrieval in Facebook Search》提出拿召回位置在101~500上的物料作为Hard Negative Sample,排名太靠前那是正样本,不能用;太靠后,与随机无异,也不能用;只能取中段。也可以将排序模型打分靠后的作为Hard Negtive,但是选择100-200还是300-500就只能去尝试了。
「【推荐阅读】」
负样本为王:评Facebook的向量化召回算法 - 石塔西的文章 - 知乎 https://zhuanlan.zhihu.com/p/165064102
SENet双塔模型:在推荐领域召回粗排的应用及其它 - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/358779957
模型利器 - 召回/排序中的负样本优化方法 - 十三的文章 - 知乎 https://zhuanlan.zhihu.com/p/453776850
召回和粗排负样本构造问题 - Louis的文章 - 知乎 https://zhuanlan.zhihu.com/p/352961688
召回模型中的负样本构造 - iwtbs的文章 - 知乎 https://zhuanlan.zhihu.com/p/358450850
推荐系统传统召回是怎么实现热门item的打压? - 石塔西的回答 - 知乎 https://www.zhihu.com/question/426543628/answer/1631702878
Google Play双塔召回算法 - 张备的文章 - 知乎 https://zhuanlan.zhihu.com/p/533449018
1.2 离线训练
召回阶段一般用到的特征有三种:
user特征:主要包含user ID、用户基础属性信息(性别、年龄、地域等)、用户画像信息、用户的各种session信息等等。
item特征:主要包含item ID、item基础属性信息(发布日期、作者ID、类别等)、item的画像、item创作者画像等等。
上下文特征:当前时间戳、手机类型、网络类型、星期几等等。
离线训练双塔召回模型时,将user特征和上下文特征concat起来,作为user塔的输入。将item特征concat起来,作为item塔的输入。
双塔召回模型的离线训练步骤为:
将用户侧的特征concat起来,输入一个DNN网络中,最终得到一个user embedding;
将物品侧的特征concat起来,输入一个DNN网络中,最终得到一个item embedding;
拿user embedding与item embedding,做点积或cosine,得到logit,代表user和item之间的匹配程度;
设计loss训练模型,一般loss都选择weighted cross entropy loss或Focal loss,这些loss都是point wise方法。
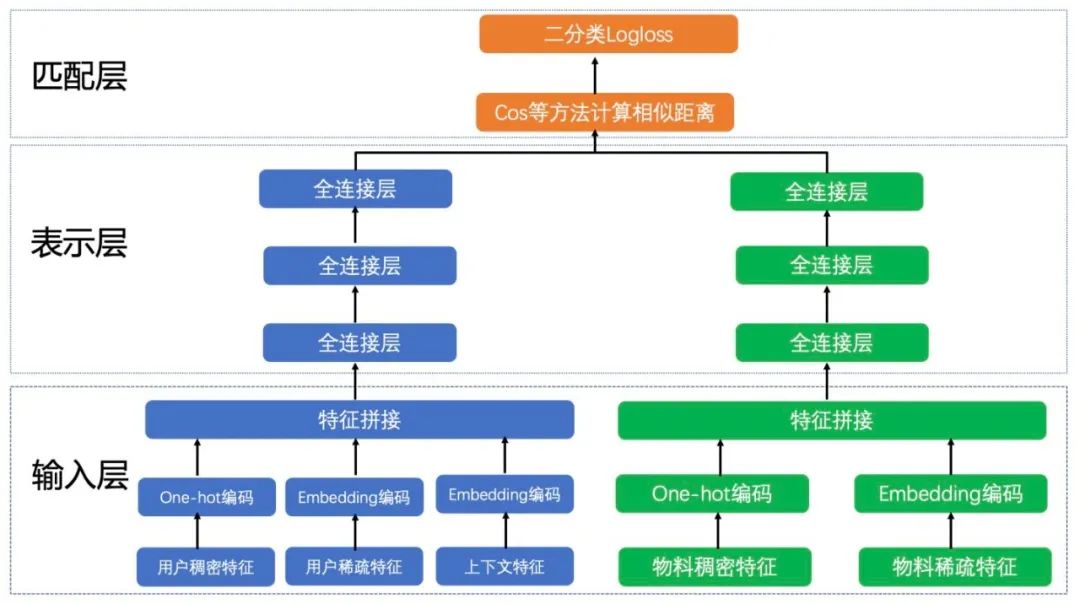
图:双塔召回模型结构
1.3 线上预测
双塔召回模型的线上预测步骤为:
离线刷可推荐item库得到item embedding,具体做法为:离线的、周期性的、批量的将item特征输入item塔,得到item embedding。把得到的item embedding导入Faiss中,建立索引。
线上实时得到用户的user embedding,具体做法为:当用户线上请求后,将user特征和上下文特征输入user塔,得到user embedding。
拿到的实时user embedding到Faiss中做近邻搜索(ANN),得到与user embedding相邻的Top N个item集合,作为召回内容返回。
1.4 性能优化
(1)User Embedding 与 Item Embedding 如何保持一致性?
由于双塔召回模型在Serving环节,主要包括异步Item刷库Serving和User Serving两部分,具体功能如下:
异步Item刷库Serving,主要通过刷库Item Serving捕获所有的item embedding,以异步的方式反复刷库,把得到的item embedding导入Faiss中,建立索引。大家经常会问的一个问题:如果模型更新了,item embedding有的是新的,有的是旧的,版本不一致怎么办?如果更新周期比较短,item embedding的分布不会发生较明显的偏移,即相邻版本比较接近,这间接保障了一致性,不需要版本是强一致性的,只要更新周期比较短就可以。
User Serving,当用户请求推荐引擎后,获取该用户的user features,然后请求User Serving产出user embedding;同时,基于全库Item刷库的Embedding结果产出的Faiss索引服务做近邻搜索(ANN),召回Top N个item集合。
User Embedding是实时从线上服务的模型中产生的,线上服务的模型一定是最新版本的模型。而Item Embedding是周期性拿全量Item库刷线上服务模型得到,会出现有的Item Embedding是新的,有的是旧版的,版本不一致。那在做近邻搜索(ANN)时,User Embedding会和部分Item Embedding版本一致,都是从一个模型中产生的,而其余部分Item Embedding版本是上一版模型导出的。这种版本的不一致就会导致召回结果的准确性降低!算法工程师为了追逐线上千分之一的增长,也为了追逐更高的OKR,对这种不一致性的缺点容忍度就没那么高了,围绕着这个问题,勤劳的互联网打工人设计出了一套改进方案。
线上实时得到User Embedding时,也会拿到当前服务模型的版本号,如果用Tensorflow导出模型的话,模型的版本号就是导出模型时刻的时间戳。Item Embedding导入到Faiss中建立索引时,也会对这个建立的Faiss索引库标上模型的版本号。然后拿着带有模型版本号的User Embedding,到对应版本号的Faiss索引库中做近邻搜索(ANN),召回Top N个item集合。这个优化主要集中在工程上,优化难度也不大,主要就是能提升模型的在线收益。
「【推荐阅读】」
腾讯音乐:全民K歌推荐系统架构及粗排设计,地址:https://mp.weixin.qq.com/s/Jfuc6x-Qt0rya5dbCR2uCA,2021-03-08。
(2)User塔只计算一次
在线Serving打分阶段,一个Batch请求中包含一个用户的特征和多个item的特征。一般是将用户的特征复制Batch Size大小的次数,然后与每一个item的特征进行拼接,最后输入到双塔网络中计算user对每个item的打分。这里有一个问题是:如果user塔的网络比较复杂或者用户特征非常多时,这种Serving打分的方式容易导致user塔的大量、重复计算。通常推荐系统中用户特征占比非常大,主要是用户的各种session特征及各种画像特征,而item的特征通常是一些属性特征和统计特征,占一个Batch请求包的很小比例。User塔的优化就是,对于一个用户的一次Batch打分请求,User塔只计算一次,在得到最终User Embedding后,复制batch size份。在Tensorflow中,整个优化流程如下:
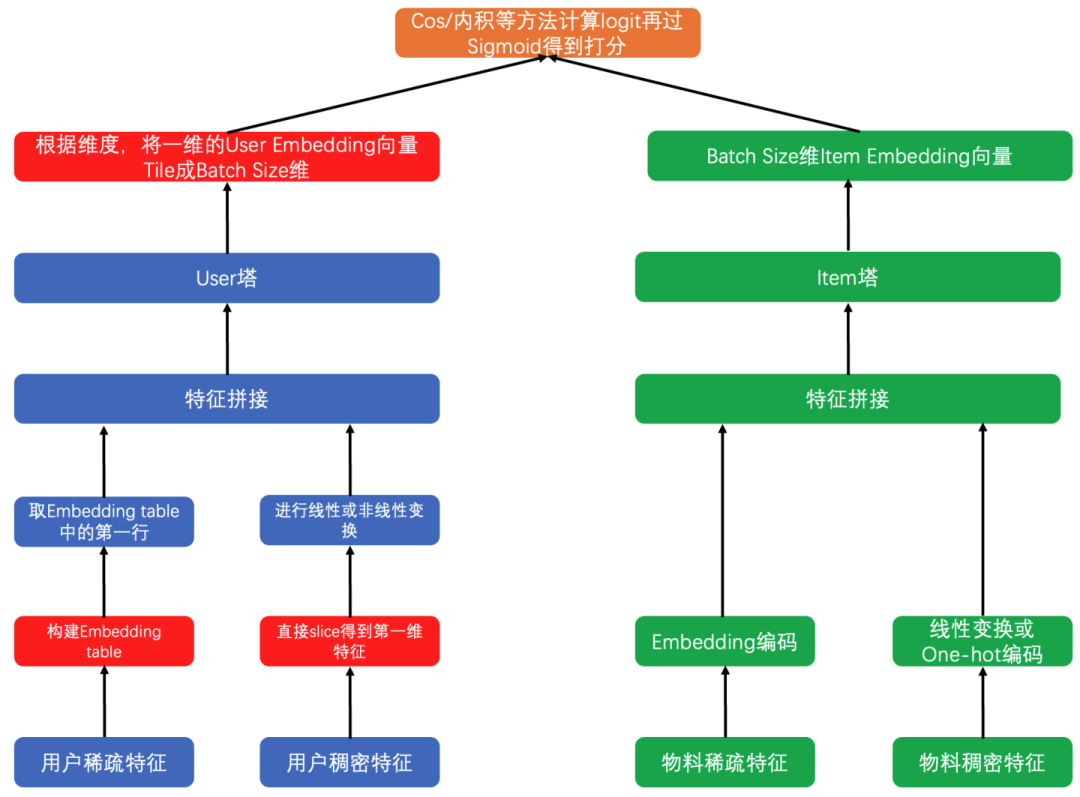
在线Serving时,每个Batch只有一个用户的所有特征且拿一次,这里不是拿一个用户的特征拿Batch Size次哦,所以在生成稀疏特征的Embedding和稠密特征时,我们只需要取第一行的Embedding数据和稠密特征数据就可以了,也就是用户的特征只过一次User塔,User Embedding只需要生成一遍,这样矩阵运算就可以优化为向量运算。在得到最终的User Embedding后,把User Embedding再复制为batch size的维度。经过这一步的优化,双塔模型在线Serving时的打分耗时及线上服务需要的机器资源都减少了许多。
2. 增强重要信息到塔顶的能力
双塔结构最大的缺点就是,User侧与Item侧信息交叉得太晚,等到最终能够通过内积或Cosine交叉的时候,User Embedding和Item Embedding已经是高度浓缩的了,一些细粒度的信息已经在塔中被损耗掉,永远失去了与对侧信息交叉的机会。所以,双塔改建最重要的两条主线就是:
经典双塔是将User侧所有信息输入到一个塔中,将Item侧所有信息输入到另一个塔中,这会造成向塔顶流动的信息通道拥挤不堪,各路信息相互干扰。如何保证重要信息无损地从塔中通过?如何保证重要的信息在塔的最终的Embedding中,从而有机会和对侧塔得到的Embedding交叉?这条主线强调的是保证重要信息无损通过。
如何保留更多的信息在塔的最终的Embedding中,从而有机会和对侧塔得到的Embedding交叉?这个主线强调的是保留更多的、更丰富的信息在塔中。
这一小节我们就围绕着第一条主线:如何保证重要信息无损通过双塔到达塔顶的Embedding中,即增强重要信息到塔顶的能力。
2.1 SENet双塔模型
张俊林老师在知乎文章《SENet双塔模型:在推荐领域召回粗排的应用及其它》中提出,将SENet引入双塔结构中。就是在用户侧塔和Item侧塔的特征Embedding层上,各自加入一个SENet模块就行了,两个SENet各自对User侧和Item侧的特征,进行动态权重调整,强化那些重要特征,弱化甚至清除掉(如果权重为0的话)不重要甚至是噪音的特征。其余部分和标准双塔模型是一样的。
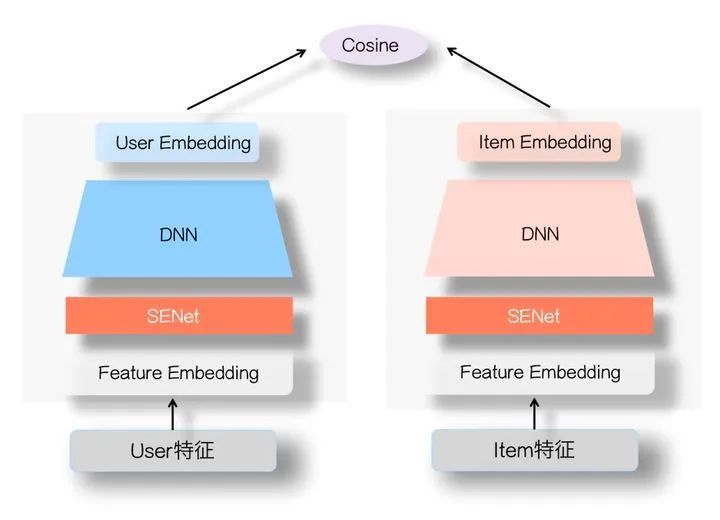
图来源:SENet双塔模型:在推荐领域召回粗排的应用及其它 - 张俊林的文章 - 知乎https://zhuanlan.zhihu.com/p/358779957
至于在双塔结构中加入SENet模块为什么有效?是因为SENet通过参数学习,动态抑制User或者Item内的部分低频无效特征,很多特征甚至被清零,这样的好处是,它可以凸显那些对高层User Embedding和Item Embedding的特征交叉起重要作用的特征,更有利于表达两侧的特征交互,避免单侧无效特征经过DNN双塔非线性融合时带来的噪声,同时,它又带有非线性的作用。
2020年底,在他们的业务数据测试,加入SENet的双塔模型,与标准双塔模型比,在多个业务指标都有提升,在个别指标有较大的效果提升。而且,如果引入ID类特征,这种优势会更明显。
2.2 重要特征加的浅
重要特征加的浅的改进方案主要参考石塔西老师的文章:久别重逢话双塔 - 石塔西的文章 - 知乎 https://zhuanlan.zhihu.com/p/428396126
信息在塔中向上流动的过程,也是一个信息压缩的过程,不可避免地带来信息损耗。所以,很自然地想到何不让那些重要信息抄近路、走捷径,把它们直接送到离最终的点积更近的地方。
提到抄近路,大家自然而然地想到ResNet,如下图所示。
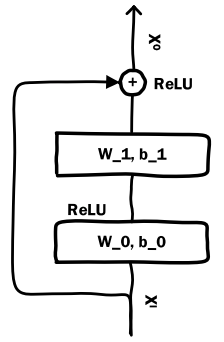
图来源:《Deep Crossing: Web-Scale Modeling withoutManually Crafted Combinatorial Features》
是喂入塔的原始信息,经过塔中的信息流动,到最后一层时已经损失了很多重要的、细粒度信息。
这时,我们将抄近路,送到最后一层与塔的Embedding输出融合(图中是element-wise add,但是显然那并不是唯一的融合方式),得到最终融合的Embedding 。
这时的既包含了经过User塔/Item塔高度浓缩后的信息,又包含原始输入中的一些细粒度信息。特别是这些细粒度的重要信息,终于有了和对侧信息交互的机会。
抄近路的思路确定了,那么抄近路的方式,就五花八门,多种多样了。比如除了原始输入能够抄近路,塔中间的一些信息是不是也能抄一把?既然信息在塔中流动过程中就已经损失了,重要信息没必要等到最后一刻再补充,补充到中间层也会大有帮助,就像马拉松选手的中途补水。
但是,这种抄近路的方式,也有其固有的缺点,就是会导致输入层的肿胀。比如原来User塔或Item塔的Embedding是64维,现在要将一些重要的、细粒度的信息也抄近路到最后一层。既然称这些信息是细粒度的,自然是未经过压缩提炼的,维度一般都很大,比如1024维。如果将原来塔输出的Embedding与抄近路信息简单拼接,那么最终的Embedding就会膨胀好几倍,会给线上存储、内存都带来巨大的压力。当然也可以将抄近路的信息,经过一层简单的线性映射,压缩到一个比较小的维度,但这会引入额外的映射权重,严重时会导致训练时OOM。
所以,将所有原始信息无脑地抄近路,显然是行不通的。这就牵扯到另外一个问题:哪些信息值得抄近路?要回答这个问题,可以跑一个SE block或其它什么算法,获得各特征的重要性,对这些重要的特征抄近路。而从我的个人经验来看,我们要特别注意那些“极其个性化”的特征(如:user_id、 item_id)和对划分人群、物群有显著区分性的特征(如:用户是新用户还是老用户、用户是否登陆、文章所使用的语言等)。
「【推荐阅读】」
久别重逢话双塔 - 石塔西的文章 - 知乎 https://zhuanlan.zhihu.com/p/428396126
SENet双塔模型:在推荐领域召回粗排的应用及其它 - 张俊林的文章 - 知乎 https://zhuanlan.zhihu.com/p/358779957
初来乍到:帮助新用户冷启的算法技巧 - 石塔西的文章 - 知乎 https://zhuanlan.zhihu.com/p/458843906
3. 并行多塔召回模型
这一小节我们就围绕着第二条主线:如何保留更多、更丰富的信息在塔的最终的Embedding中,从而有机会和对侧塔得到的Embedding交叉?做这条主线的启发主要有两点:
原始双塔是将User侧所有信息输入到一个塔中,将Item侧所有信息输入到另一个塔中,造成向上流动的信息通道拥挤不堪,各路信息相互干扰。SENet的解决方法是“堵”,在输入塔之前,就将噪声弱化甚至屏蔽掉,使塔内的信道变得宽敞,保证重要信息无损通过。而另外一种思路是“疏”,大家没必要都挤一个塔向上流动,不同的信息(甚至是相同的信息)可以沿适合自己的塔向上流动浓缩,避免相互干扰。最后由每个小塔的Embedding聚合成最终的Embedding,与对侧的最终的Embedding做内积或cosine。
相同的信息,也可以沿多种信息通道向塔顶流动,每种通道各有所长,大家相互取长补短。最终将各通道得到的Embedding聚合成最终的Embedding,与对侧交互。
3.1 “并联”双塔模型
模型架构总的来说可以分成三层,分别是输入层、表示层和匹配层。结构如下图所示:
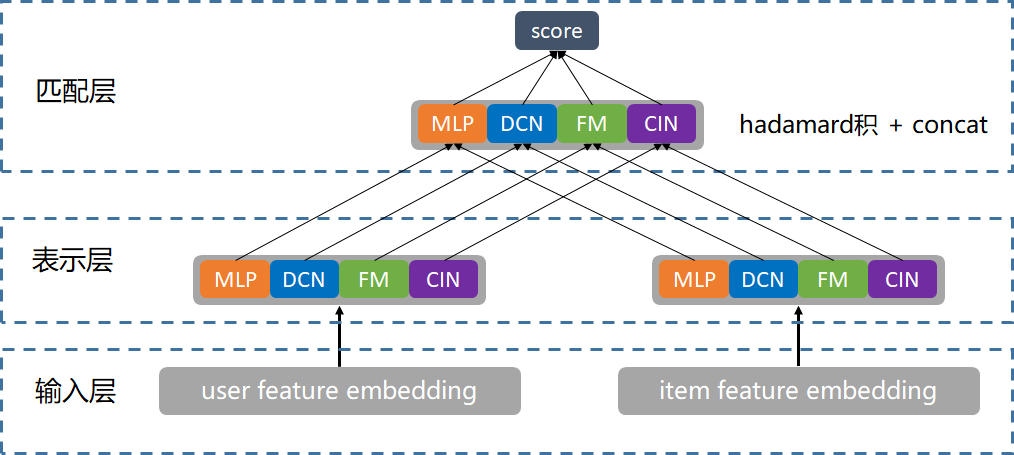
图来源:https://mp.weixin.qq.com/s/karPWLyHITu-qZceEhpn-w
输入层:将user和item特征映射成feature embedding,方便在表示层进行网络构建,小说场景下的user特征包括用户id、用户画像(年龄、性别、城市)、行为序列(点击、阅读、收藏)、外部行为(浏览器资讯、腾讯视频等)。item特征包括小说内容特征(小说id、分类、标签等)、统计类特征等。所有特征都经过离散化后再映射成embedding。
表示层:并联各种深度神经网络模块(MLP、DCN、FM、CIN 等)从多个角度学习输入层feature的融合和交互,生成并联的user、item向量用于匹配层计算。这里user-user和item-item的特征交互直接在塔内的网络结构可以做到,而user-item的特征交互只能通过顶层的内积操作实现,所以这里网络结构的设计重点是提升双塔结构的user-item的特征交互能力。
匹配层:将表示层得到的并联user和item向量进行 hadamard积(相当于多个双塔拼接),再经过一个LR 进行结果融合,在线serving阶段LR的每一维的权重可预先融合到user embedding里,从而保持在线打分仍然是内积操作。
腾讯的并联双塔,通过并联多个双塔结构增加双塔模型的宽度,来缓解双塔内积的瓶颈从而提升效果,主要优点如下:
信息沿着MLP、DCN、FM、CIN这4种通道向塔顶流动。每种通道各有所长,比如MLP是隐式特征交叉,FM和DCN都属于显式、有限阶特征交叉,大家相互取长补短。
最终各通道的融合,这里是直接拼接,并且在各通道的Embedding乘上一个可学习的权重系数,以形成一个logistic regression的效果。对"并联"的多个双塔引入LR进行带权融合,LR权重最终融入到user embedding中,使得最终的模型仍然保持的内积形式。比如我们只有MLP和DCN两个通道:
则两侧点积时,
「【推荐阅读】」
“并联”双塔模型 | 你还不知道怎么玩吗!,地址:https://mp.weixin.qq.com/s/karPWLyHITu-qZceEhpn-w ,2021-09-13。
3.2 多塔多目标召回模型
(1)为什么要做多目标多塔召回?
推荐系统一般由召回、粗排、精排、重排几个阶段构成。最近几年,粗排、精排、重排等阶段已经在多目标学习上取得了显著的收益,如何把多目标学习的能力下沉到召回阶段,提升单路召回撬动推荐系统多个终极目标的能力。此外,面对越来越复杂的业务场景,单一的用户向量召回往往无法兼顾每一个优化的子目标,针对多个子目标建模进行召回就显得尤为重要。如何在一个模型里做多目标的召回,且充分利用多目标排序中各个目标之间可以进行信息共享,防止某些目标因为训练样本过于稀疏而不能得到充分训练的优势,同时也不至于出现多个模型维护困难的问题。
当然做多目标召回的灵感,不仅是来源于上述所说的多目标下沉到召回阶段的必要性,而且还受到学术届两篇论文的启发。
1)《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》,这篇论文用多个Embedding向量来表示用户的多个兴趣表征,然后通过Label-aware Attention 结构对多个兴趣向量加权,最后使用用户兴趣向量和待推荐Item Embedding,计算用户和商品交互的概率,计算方法和YouTube DNN一样。线上Serving的时候,实时计算用户的多个兴趣向量后,每个兴趣向量Embedding通过KNN检索得到最相似的Top-N候选商品集合。我当时就在思考,是否可以将多个兴趣向量通过权重做加权平均变成一个用户兴趣向量,或者是对每一个兴趣向量乘以对应的权重然后拼接起来变成只有一个用户Embedding的表征,然后去线上检索这一个Embedding的Top-N相似。
2)在Facebook的论文《Embedding-based Retrieval in Facebook Search》中提出:用不同难度的负样本训练不同难度的模型,再做多模型的融合。其中,有一种模型融合方式就是-并行融合。不同难度的模型独立打分,最终取Top K的分数依据是多模型打分的加权和(各模型的权重是超参,需要手工调整):
但是线上召回时,为了能够使用Faiss,必须将多个模型产出的Embedding融合成一个向量。做法也非常简单,将权重乘在User Embedding或Item Embedding一侧,然后将各个模型产出的Embedding拼接起来,再喂入Faiss。这样做,能够保证拼接向量之间的cosine,与各单独向量cosine之后的加权和,成正比。
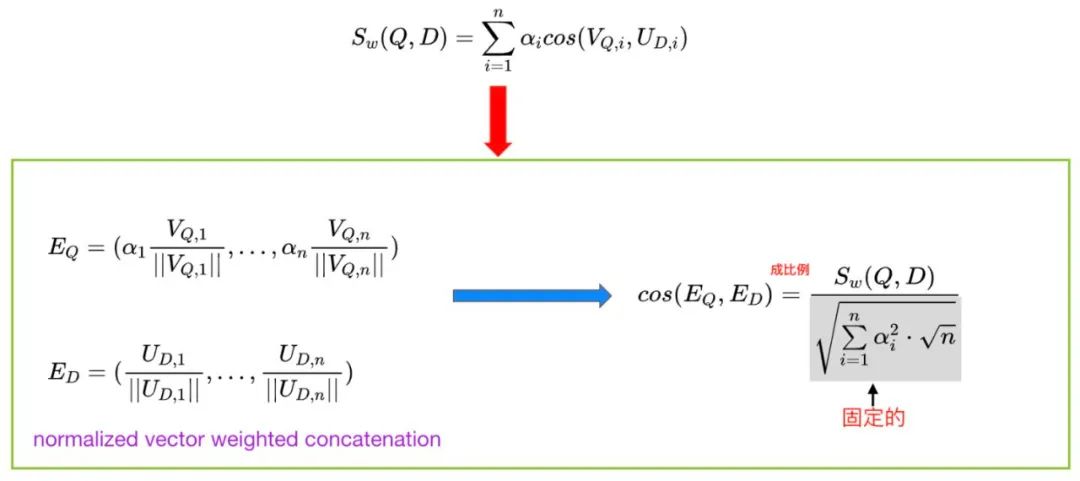
Easy model肯定是拿随机采样训练出来的模型,这个没有异议。问题是Hard model是哪一个?
论文中指出,使用“曝光未点击”作为Hard negative训练出来的Hard model,离线指标好,但是线上没有效果;
反而,使用挖掘出来的Hard negative训练出来的Hard model,与Easy model融合的效果最好;
从上面两篇论文中受到启发,我们来看一下多塔多目标召回模型的具体应用细节。
(2)多目标多塔召回的模型结构
由于经典的双塔模型结构是User和Item分开构建,最后只通过一次内积来交互,不利于User-Item交互的学习。这时很自然的就想到,需要用多塔来进行user和item的表征,尽量保留更多、更丰富的信息在塔的最终的Embedding中。
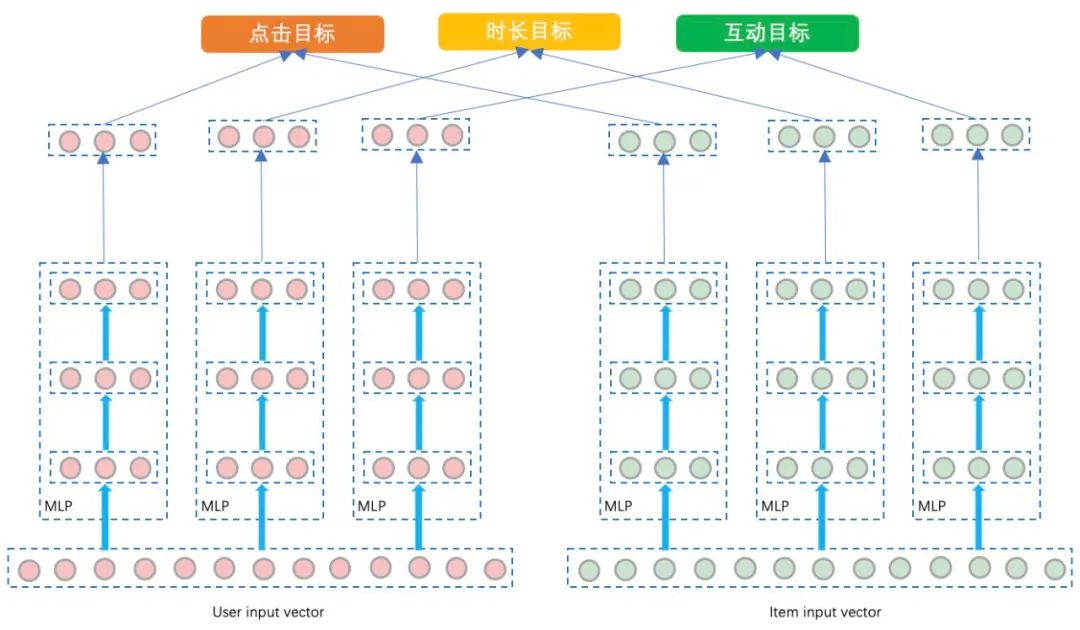
「1)共享底层参数的多塔结构」
这里是只共享底层embedding look-up table,上层用三个塔分别训练三个label对应的embedding向量。这是继承双塔模型的思路,在双塔单目标建模中,user和item各有一个塔产出最终Embedding计算loss。那么我们可以多建几个塔来学习不同目标的Embedding,然后在最终计算loss的时候聚合,这样可以将多目标的训练在Embedding层面隔离开,只在计算loss的时候融合。这种方法的优点是:建模方式简单,各个目标训练相对独立,相互之间的影响比较小。缺点就是:底层强制共享embedding look-up table难以学得适用于所有目标的表达,且对于互动目标样本稀疏的问题,会导致对应user embedding的过拟合问题。模型结构如下图所示:
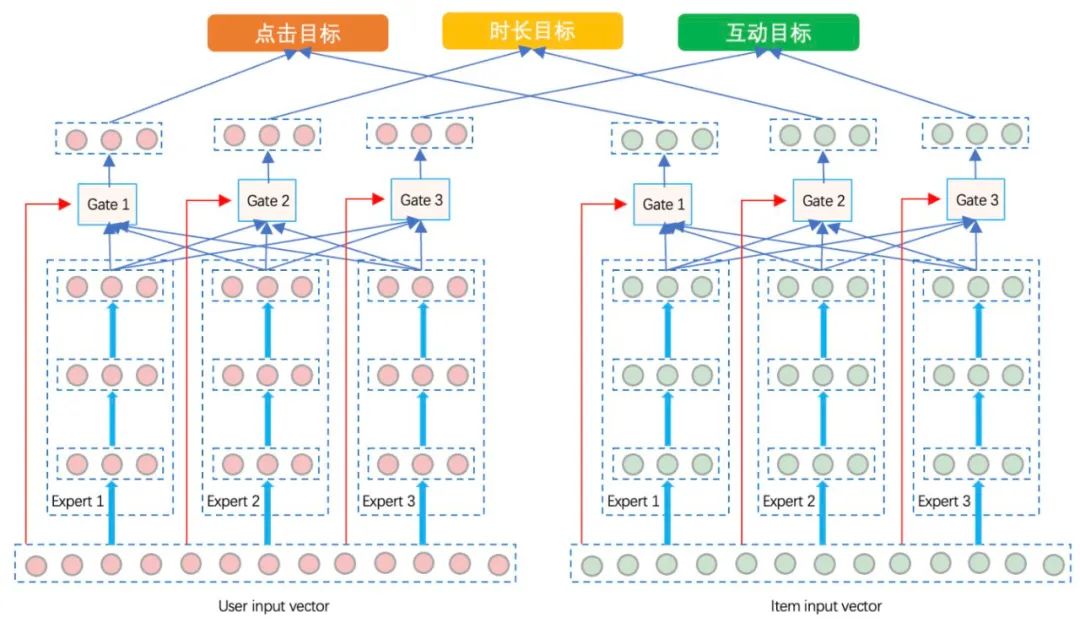
「2)基于MMoE的双塔结构」
这里对双塔网络在网络结构方面做了升级,User侧的网络是一个MMoE结构,Item侧的网络也是一个MMoE的结构。如下图所示:
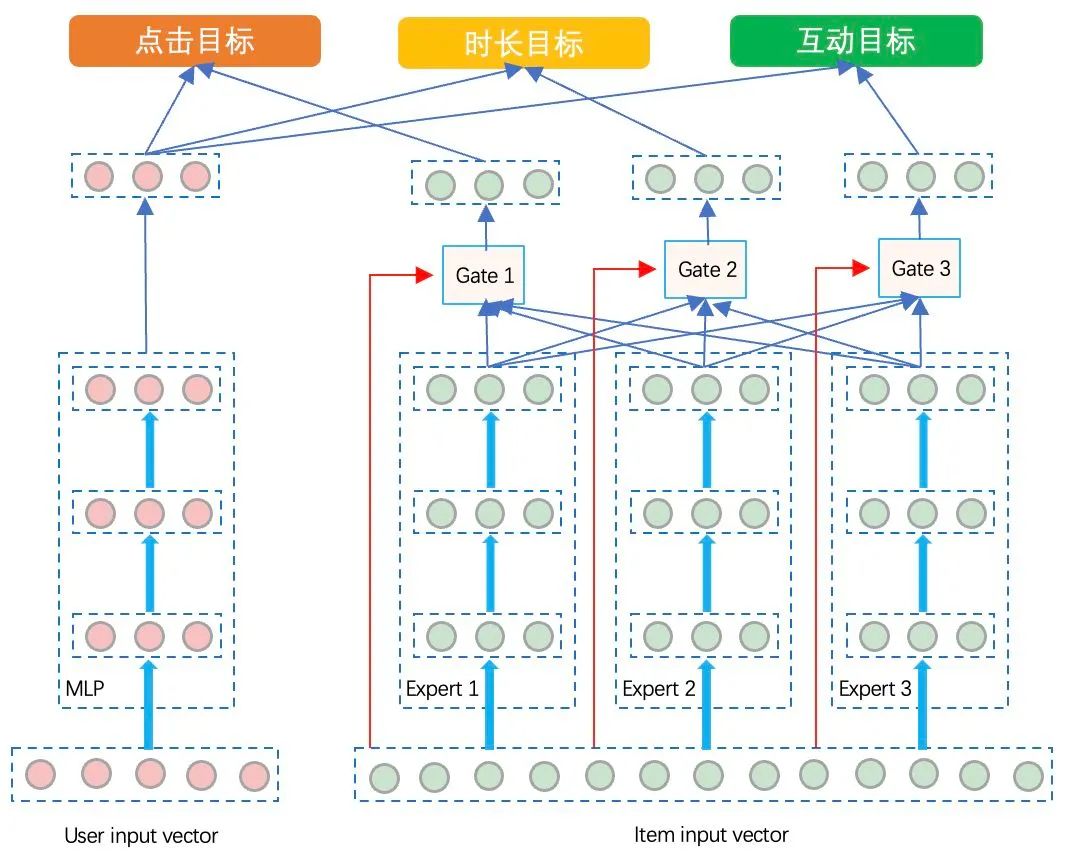
「3)所有目标共用User Embedding」
将user合并为一个塔训练,item用三个塔分别训练三个label对应的Embedding。由于大部分用户在时长、互动目标上的正样本非常稀疏,这就使得user侧的时长、互动目标的Embedding难以得到训练。相对来讲,item侧的时长、互动目标的稀疏性并不明显,所以可以保留item侧的三塔三目标结构。此外,由于item embedding仍是每个目标各自生成的,可以在item侧学习各个目标的差异,使得各个item在不同目标的embedding含有差异化。
这一步的优化,在推荐各个指标没有明显下跌的情况下,线上Serving的机器数量直接节省了。
(3)多目标召回的一些trick
「1)多目标召回如何进行负采样?」
多目标召回的样本直接用的是精排的训练样本。由于召回不能完全利用精排的样本,因此这里要做负采样。首先,我们先确定要使用的正样本,点击、时长、互动三个目标中至少有一个为正目标,那这条样本就可以当作正样本了,正样本可以从精排的样本中过滤出来。接下来确定负样本,我们会从精排样本中把(item_id,item_features)作为一条数据依次放到采样池中,针对每一条正样本,都会从采样池中随机拿出N条item_id不等于正样本中item_id的(item_id,item_features)数据作为负样本,当然作为负样本中的每一个目标都是负目标。
「2)各个目标的在线打分权重如何确定?」
在精排和粗排上,得到每个目标的得分后,还需要制定各个目标的融合公式及各个目标的超参权重。这里召回直接复用精排的目标融合公式及各个目标的超参,使用效果和精排是一致的,公式推导如下:

「3)对于秒滑、快滑、跳出等负目标,如何利用产生的User/Item Embedding?」
在用户侧的特征中还有一种特征我没有提到,就是用户的负向行为序列特征。我的经验是,如果网络的目标中有负目标,在训练的时候加上用户的负向行为序列,能提升负目标的AUC指标;如果网络中没有负目标,加上用户的负向行为序列特征,对于其它目标AUC没有提升甚至有负作用。因此在使用“用户负向行为序列特征”时,要谨慎!
对于秒滑、快滑、跳出等负目标,在精排和粗排阶段得到负目标的得分后,线上设计一种融合公式,就能把这种负目标利用到最终的融合打分上。而召回阶段,由于涉及到Faiss检索,如何把负目标得到的Embedding利用起来,我一直没有找到很好的办法,这一点还需要接着往下探索,有相关经验的同学欢迎和我交流分享哈~
「【推荐阅读】」
谈谈推荐场景中召回模型的演化过程 - 梦想做个翟老师的文章 - 知乎 https://zhuanlan.zhihu.com/p/97821040
负样本为王:评Facebook的向量化召回算法 - 石塔西的文章 - 知乎 https://zhuanlan.zhihu.com/p/165064102
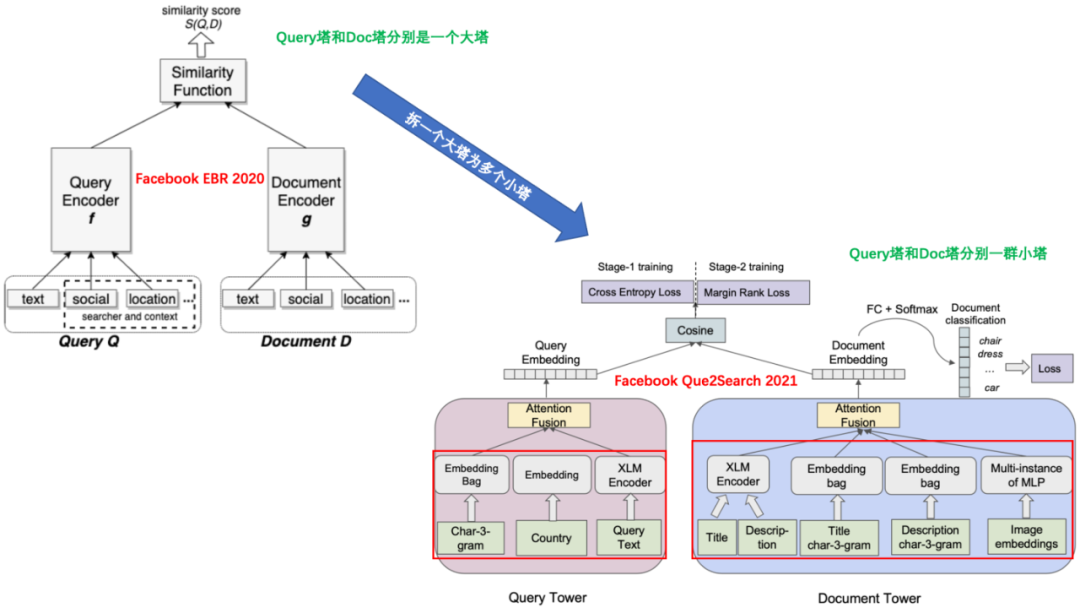
3.3 Facebook的Que2Search
“并行多塔”思路的另一个代表,是来自Facebook的论文《Que2Search: Fast and Accurate Query and Document Understanding for Search at Facebook》。这篇文章可以算是Facebook 2020年经典论文《Embedding-based Retrieval in Facebook Search》的后继,延续了其一贯的风格,文章字字珠玑,是真实问题驱动的研究,写作思路清晰,值得精读。
模型架构如下图所示,是典型的双塔结构。Query侧的输入特征有多个通道,包括Query本身的3-gram、国家和原始文本。Document侧的输入特征包括了title、description、title的3-gram、description的3-gram和图像的向量。Query塔和Document塔分别通过attention做融合后得到Query向量和Doc向量,再进行余弦相似度计算。
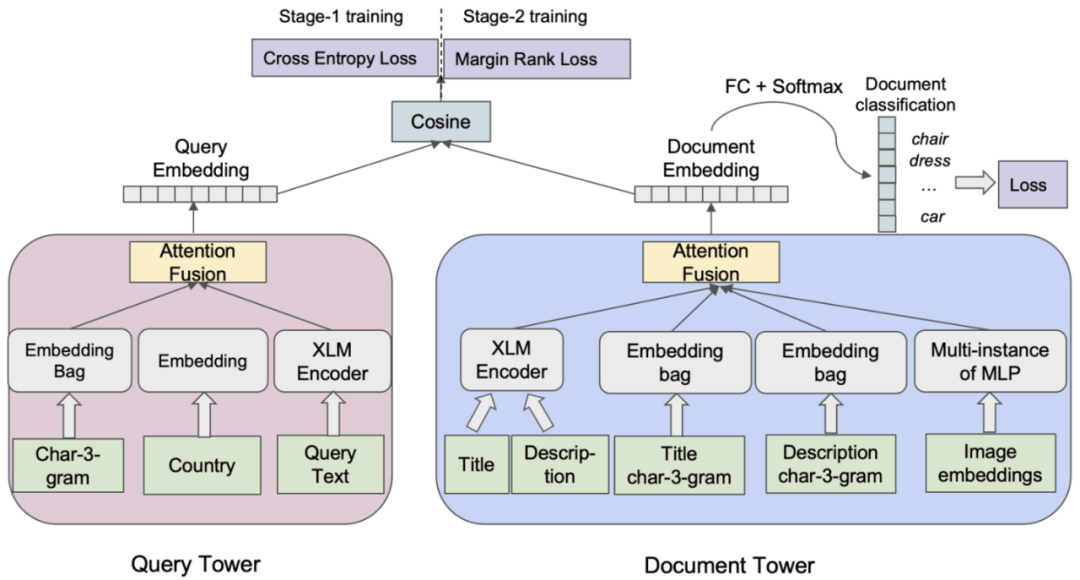
(1)Query Tower
Query Tower的输入特征和表征方式如下,共3路的特征:
Query的3-gram稀疏特征,即在Query上做步长为3的滑窗,然后加hash方法转为ID,如MurmurHash,这样1个Query可以得到多个稀疏ID特征,分别进行嵌入,然后sum-pooling转成1个向量。
搜索用户所在的国家,做嵌入后转成1个向量。
原始Query文本特征,输入到2层的XLM编码器来进行特征提取,[CLS]的向量接一个全连接层得到原始Query文本特征向量。
作者尝试过多种的后期融合方法来融合上述不同路的向量表征,比如拼接+MLP,还比如简单的注意力机制。最后发现,简单的注意力机制融合反而效果是最好的,Attention Fusion公式如下:
其中,代表第路得到的特征向量。是拼接操作,即:各路向量全部拼接再一起,过一个全连接层+softmax,输出每一路向量的权重,即。最后加权求和输出融合后的表征向量。
(2)Document Tower
Document Tower的输入特征和表征方式如下,共4路特征:
商品的标题和描述信息原始文本,使用一个共享的6层 XLM-R编码器对标题和描述信息分别进行编码。
标题的3-gram稀疏特征,方法同Query tower。
描述信息的3-gram稀疏特征。
商品关联的图片。1个商品会关联多个图片,使用GrokNet模型获取图片的预训练向量表征,再接一个共享的MLP层,最后用Deep Sets方法来融合多个图片向量得到融合后的图片表征。
最后,同样是基于attention加权融合上述四种向量,得到最终的document侧向量。
(3)Facebook两篇双塔论文的比较
对比Facebook的两篇双塔论文《Que2Search: Fast and Accurate Query and Document Understanding for Search at Facebook》和《Embedding-based Retrieval in Facebook Search》,可以清晰看到“拆一个大塔为若干小塔”的思路变化。在Que2Search中,不同信息通过不同通道向上传递,比如country这样的categorical特征直接embedding,而文本信息则通过XLM。不同通道得到各自的embedding,再融合(fusion)生成final embedding,与对侧塔得到的final embedding计算cosine similarity。
「【推荐阅读】」
Liu Y, Rangadurai K, He Y, et al. Que2Search: fast and accurate query and document understanding for search at Facebook[C]//Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021: 3376-3384.
目前工业界常用的推荐系统模型有哪些?- iwtbs的回答 - 知乎 https://www.zhihu.com/question/314773668/answer/2259594886
双塔召回模型的前世今生(下篇) - iwtbs的文章 - 知乎 https://zhuanlan.zhihu.com/p/441597009
久别重逢话双塔 - 石塔西的文章 - 知乎 https://zhuanlan.zhihu.com/p/428396126
KDD'21 | 揭秘Facebook升级版语义搜索技术 - 蘑菇先生的文章 - 知乎 https://zhuanlan.zhihu.com/p/415516966
3.4 阿里的《Embedding-based Product Retrieval in Taobao Search》
这种"多塔各自embedding + Attention Fusion"的方案,在淘宝的《Embedding-based Product Retrieval in Taobao Search》也有所体现。
先介绍下整体的网络框架结构:
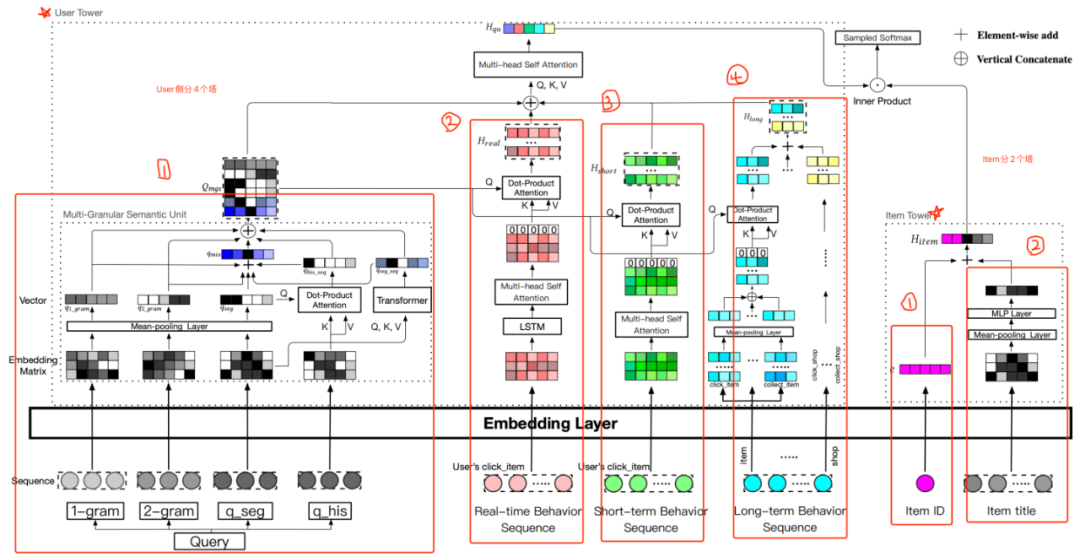
上图是典型的双塔结构,在user tower部分做的比较重,item tower部分做的比较轻量。user tower输出的用户表征向量和item tower输出的物品表征向量做点积得到预测值,再使用sampled softmax损失函数在全局item pool中进行优化。其中:
「user tower包含三个重量的部分:」
query语义表征;
用户实时、短期、长期历史行为序列个性化表征;
以及二者如何融合起来的组件。
分别对应图中user tower的左侧、中间和上半部分。
以user embedding ""为例:
是由用户输入的query生成的embedding;
、 、 分别代表由用户实时、短期、长期活动历史生成的embedding;
最终的embedding实际上是由、、、 这4方面信息Self-Attention得到。(由于self-attention会得到一个embedding sequence,而不是一个embedding,因此文章作者增加一个dummy token CLS,并拿CLS embedding作为代表整个序列的最终输出,也算是transformer的传统trick了)。
「item tower包含三个轻量的部分:」
item ID;
item的辅助信息;
以及二者如何融合起来的组件。
「模型优化方法:」
sampled softmax损失函数。
优化策略:温度参数对训练集进行噪声平滑、在embedding空间生成困难负样本。
「【推荐阅读】」
KDD'21 | 淘宝搜索中语义向量检索技术 - 蘑菇先生的文章 - 知乎 https://zhuanlan.zhihu.com/p/409390150
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









