






 论文提出LongLoRA,一种有效的方法,通过shiftshortattention(S2-Attn)扩展大语言模型的上下文长度,降低计算负担,同时保持模型在长文本处理上的性能。S2-Attn在训练时引入转移稀疏注意力,而在推理时保持标准注意力,兼容现有加速机制。
论文提出LongLoRA,一种有效的方法,通过shiftshortattention(S2-Attn)扩展大语言模型的上下文长度,降低计算负担,同时保持模型在长文本处理上的性能。S2-Attn在训练时引入转移稀疏注意力,而在推理时保持标准注意力,兼容现有加速机制。
后台留言『交流』,加入 NewBee讨论组
https://github.com/dvlab-research/LongLoRA/tree/main
1. 基本信息和摘要
论文题目:LongLoRA: Efficient Fine-Tuning of Long-Context Large Language Models
作者:ICLR author
摘要:本文提出了一种高效的微调方法,可以扩展预训练的大型语言模型(LLMs)的上下文长度,而不需要太多的计算成本。
LLM在训练时通常使用预先定义好的上下文长度,例如Llama是2048,Llama2是4096。类似summarizing long documents或者回答很长的问题时,LLM不能直接处理。有一些最近的工作尝试解决这种限制。但这些工作都需要finetune会引入较大的计算负担。
一个直接的做法是使用LoRA取代全参数finetune,但是我们研究发现这样在效率和有效性上都不好。LoRA在扩展文本长度时会导致perplexity升高(Table 3),即使把LoRA的rank提高的256也不能解决这个问题。在计算复杂度上,LoRA本身并不能减少计算复杂度,并不能解决长文本下attention layer层的计算量成平方增长的问题。
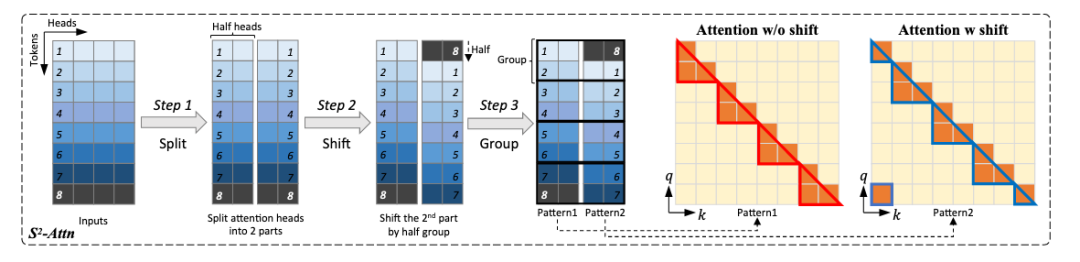
因此作者提出了LongLoRA,能够高效的扩展预训练LLM的文本长度。作者认为short attention可以用来近似训练长文本,并提出了shift short attention(S2-Attn)用于替代标准的attention。
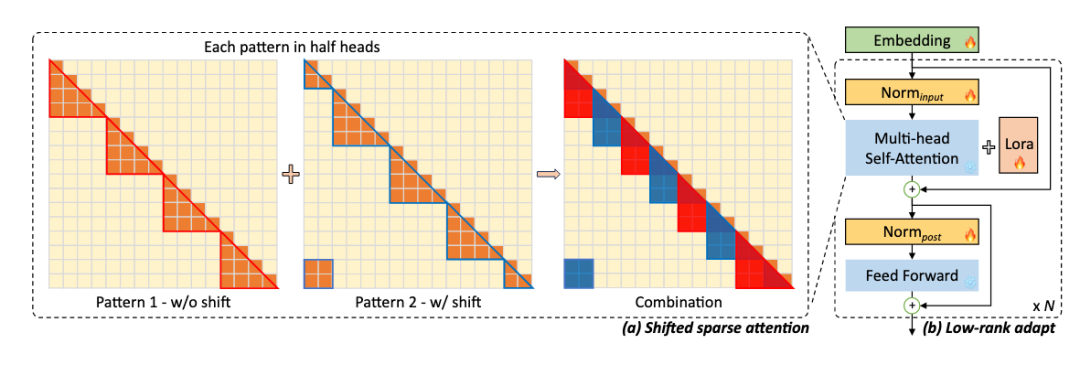
如Fig.2所示,S2-Attn将输入tokens分为多个组,并在各个组内单独计算attention。和Swin-Transformer有些类似。使用S2-Attn微调的模型在inference阶段仍然使用标准的attention,这样可以直接兼容现有的各种推理加速机制,例如FlashAttn-2。

一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









