






TLDR: 针对传统跨域推荐中存在的语义缺失问题,本文提出一种新颖的双图大模型跨域推荐方法来捕捉多样化的信息,并采用对齐和对比学习方法促进领域知识转移。

论文:https://arxiv.org/pdf/2406.03085
代码:https://github.com/TingJShen/URLLM
跨域序列推荐旨在挖掘和迁移用户在不同域之间的序列偏好,以缓解长期存在的冷启动问题。传统的跨域序列推荐模型通过用户和物品建模来获取协同信息,忽略了有价值的语义信息。最近,大语言模型显示出强大的语义推理能力,促使我们引入它们来更好地捕捉语义信息。然而,将大模型引入跨域序列推荐并非易事,因为有两个关键问题:无缝信息集成和特定领域的生成。
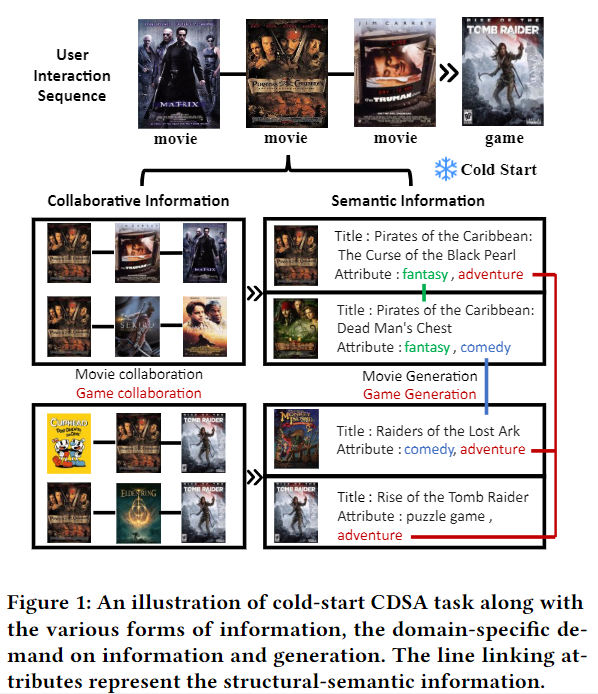
针对这一问题,该文提出了URLLM框架,通过同时探索基于大模型的用户检索方法和领域基础来提高跨域序列推荐的性能。首先提出一种新的双图序列模型来捕获多样化的信息,以及一种对齐和对比学习方法来促进领域知识迁移。然后,采用用户检索生成模型将结构信息无缝地集成到大模型中,充分利用大模型的推理能力。此外,提出了一种特定于域的策略和一个精化模块来防止域外生成。
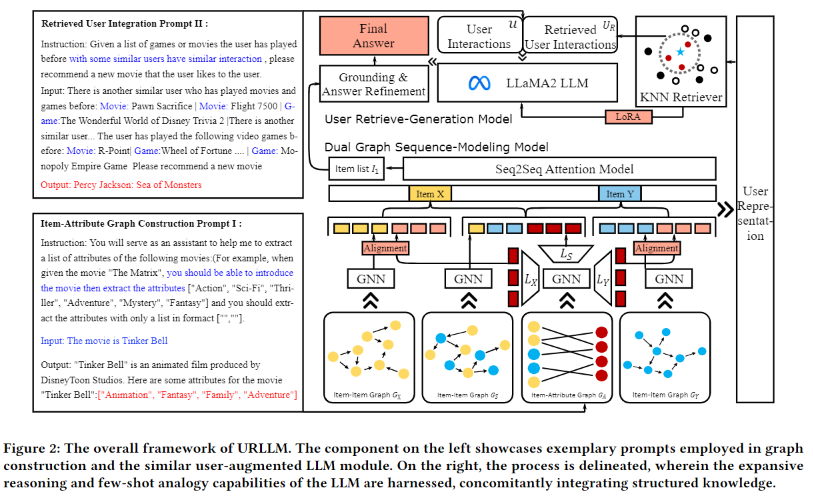
在Amazon上的广泛实验表明,与最先进的基线相比,URLLM具有信息集成和特定领域生成能力。
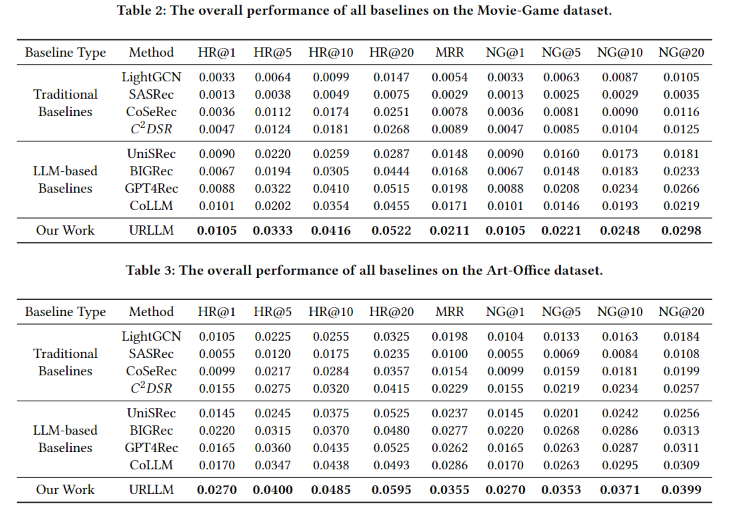
更多技术细节请阅读原始论文。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









