






转载自http://blog.csdn.net/v_july_v/article/details/6531399
B+-tree:是应文件系统所需而产生的一种B-tree的变形树。
一棵m阶的B+树和m阶的B树的差异在于:
1.有n棵子树的结点中含有n个关键字; (而B 树是n棵子树有n-1个关键字)
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而B 树的叶子节点并没有包括全部需要查找的信息)
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
a) 为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1) B+-tree的磁盘读写代价更低
B+-tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2) B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
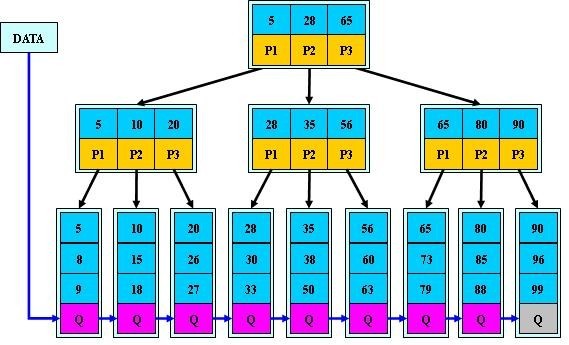
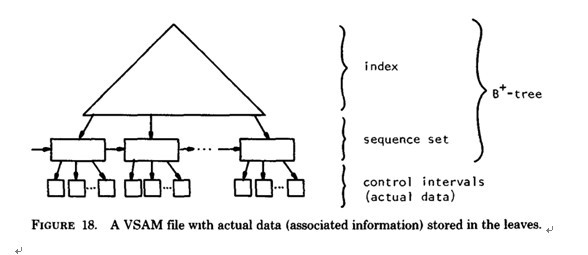
b) B+-tree的应用: VSAM(虚拟存储存取法)文件(来源论文 the ubiquitous Btree 作者:D COMER - 1979 )
5.B*-tree
B*-tree是B+-tree的变体,在B+树非根和非叶子结点再增加指向兄弟的指针;B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2)。给出了一个简单实例,如下图所示:
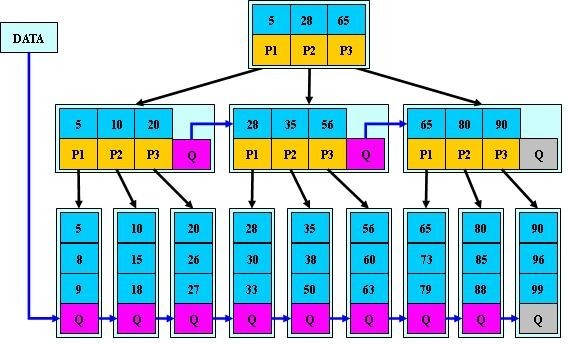
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针。
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
2-3-4树
2-3-4 树在计算机科学中是阶为 4 的B树。根据维基百科上的介绍:大体上同B树一样,2-3-4 树是可以用做字典的一种自平衡数据结构。它可以在O(log n)时间内查找、插入和删除,这里的 n 是树中元素的数目。2-3-4 树在多数编程语言中实现起来相对困难,因为在树上的操作涉及大量的特殊情况。红黑树实现起来更简单一些,所以可以用它来替代(红黑树稍后介绍)。以下就是一棵2-3-4树:
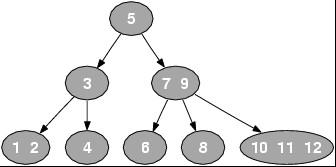
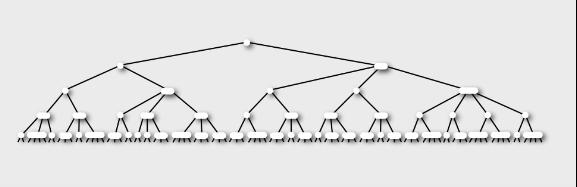
2-3-4 树把数据存储在叫做元素的单独单元中。那么请问,到底什么是2-3-4树呢?顾名思义,就是有2个子女,3个子女,或4个子女的结点,这些含有2、3、或4个子女的结点就构成了我们的2-3-4树。所以,它们组合成结点,每个结点都是下列之一:
2-节点,就是说,它包含 1 个元素和 2 个儿子,
3-节点,就是说,它包含 2 个元素和 3 个儿子,
4-节点,就是说,它包含 3 个元素和 4 个儿子 。
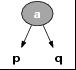
2-结点
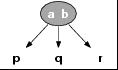
3-结点
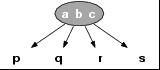
4-结点
每个儿子都是(可能为空)一个子 2-3-4 树。根节点是其中没有父亲的那个节点;它在遍历树的时候充当起点,因为从它可以到达所有的其他节点。叶子节点是有至少一个空儿子的节点。同B树一样,2-3-4 树是有序的:每个元素必须大于或等于它左边的和它的左子树中的任何其他元素。每个儿子因此成为了由它的左和右元素界定的一个区间。如下图所示(你可以看到,图中这棵2-3-4树是由2-结点,3-结点,4-结点元素组成的):
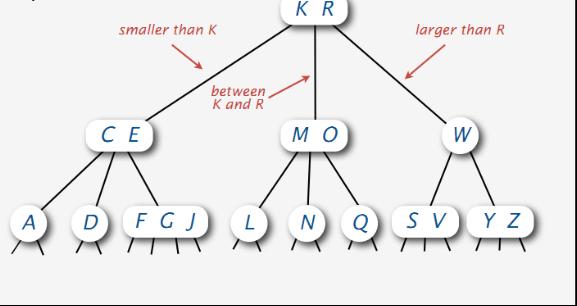
2-3-4 树是紅黑树结构的一种等同,这意味着它们是等价的数据结构。换句话说,对于每个 2-3-4 树,都存在着至少一个数据元素是相同次序的红黑树。在 2-3-4 树上的插入和删除操作也等价于在红黑树中的颜色翻转和旋转。这使得它成为理解红黑树背后的逻辑的重要工具(还是如此,红黑树稍后介绍,路得一步一步来)。
1.1、2-3-4树的查找
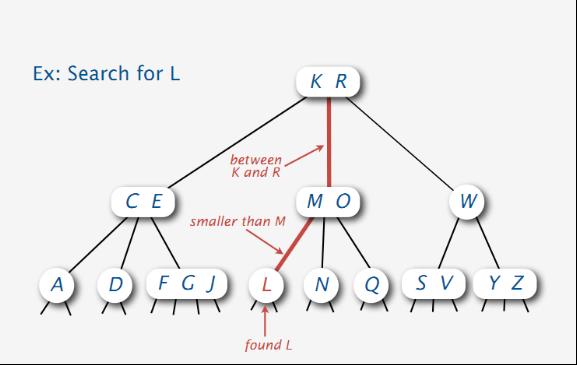
2-3-4树中查找结点,怎么查找呢?分为以下几个步骤:
1、把要查找的结点与根结点相比较
2、根据左小右大的原则,寻找含有要查找结点的区间
3、若找到了,则直接返回该结点,否则,在其子女中继续递归寻找。
如下图所示,在下面这棵2-3-4树中寻找L结点:
1.2、2-3-4树的插入
插入某个结点之前,一般我们先在2-3-4树中寻找是否存在该插入结点(若存在,当然也就没有必要再插入了),如果树中不存在该结点,则执行插入操作。
1.2.1、插入形式一:3-结点元素中插入结点
如下图所示,插入X结点,首先在树中查找是否存在X结点,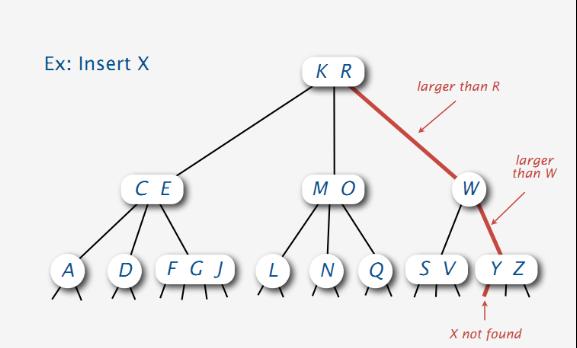
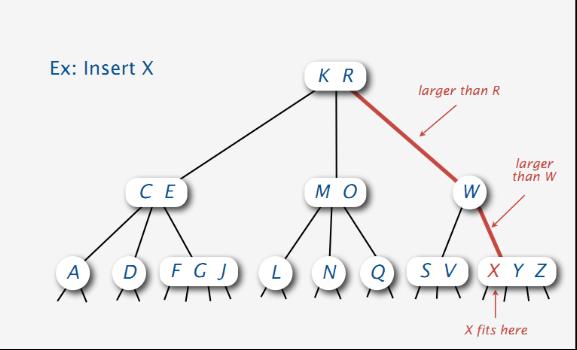
没有找到,则在含有Y Z的结点元素插入X:
1.2.2、插入形式二:
以下插入H结点,在F G J区间上发现H没有找到后,
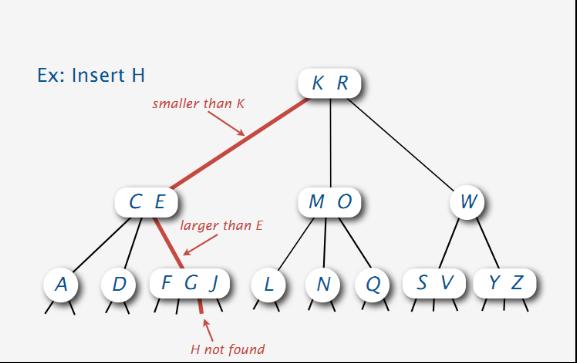
且F G J区间上已经没有空间来插入H结点了,这个时候怎么办呢?: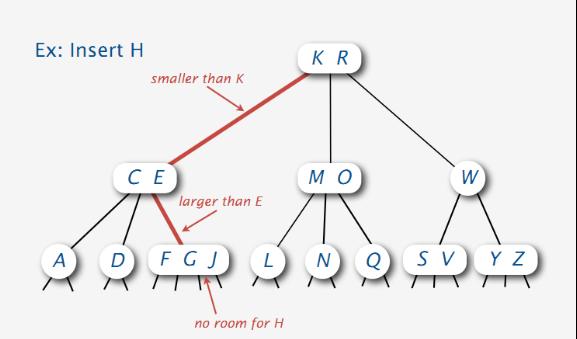
当没有空间执行插入操作的时候,咱们当然得寻找空间来执行插入。怎么寻找呢?看下图: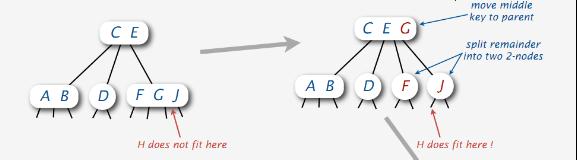
由上图,我们发现,H在区间F G J 上没有空间执行插入的时候,我们首先参试着让G元素上移至C E区间,组成C E G根结点,然后分裂F G区间,F和G各自成为独立的元素。当我们发现,H依然不能作为J的子女进行插入时,我们想到了一种折中的办法,这种办法就是,如下图所示,H插入到J元素旁,成为H J区间,F元素不作变动:
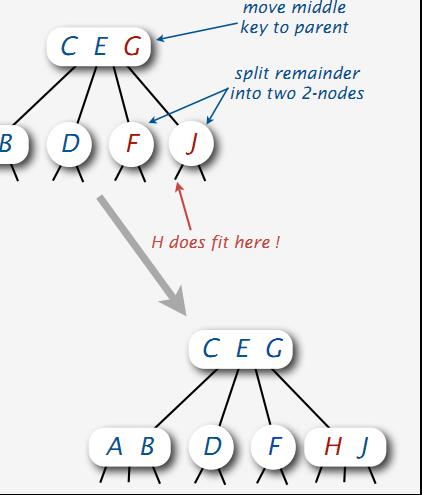
所以,当发现没有空间可执行插入结点的情况时,我们作如下对策:
1、分裂父母结点
2、然后再插入结点
上述的第1点具体怎么分裂呢?分裂的两种情况如下图所示:
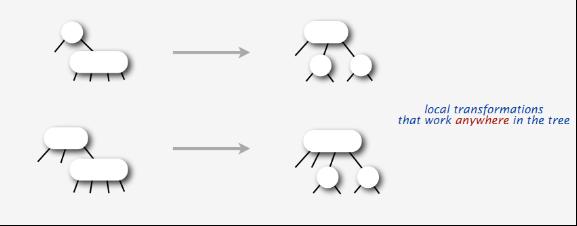
下面再具体分析下上述两种分裂情况:
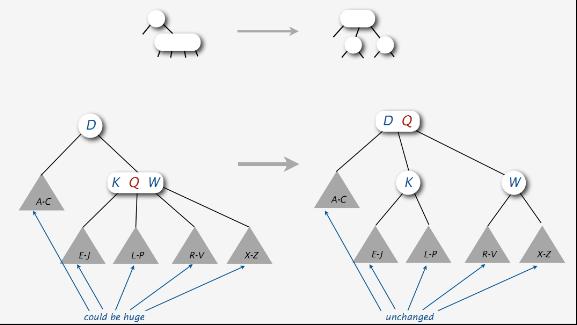
分裂情况1、如下图所示D-K Q W,区间K Q W分裂,Q上移与原根结点D组成新的根结点区间D Q,K和W各自分裂成独自区间,D-K Q W最终分裂成D Q-K-W:
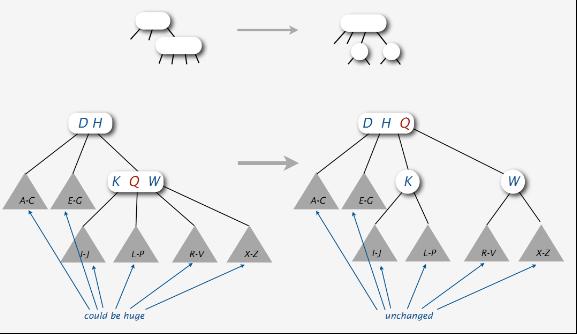
分裂情况2、如下图所示D H-K Q W分裂,K Q W区间中的Q元素上移与D H组成根元素区间D H Q,K和W 分裂,最终D H-K Q W分裂成D H Q-K-W:
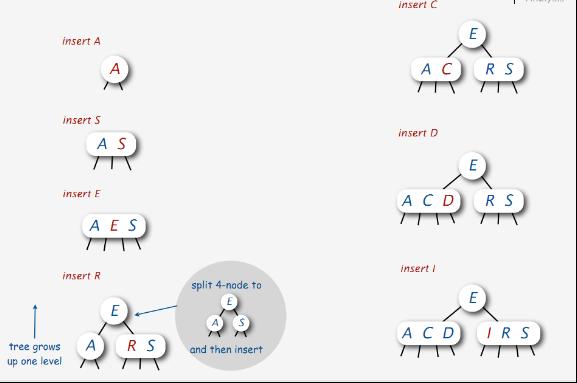
下图是逐步在2-3-4树中依次插入元素A、S、E、R、C、D、I。从中你可以看到
1、当插入元素R时,A E S区间分裂,E成为新的根元素,而要插入的R与S移至一起成为E的右儿子。
2、当插入C、D、I时,都是直接找到相对应的区间,各自插入。不必啰嗦,下图已经很形象了。
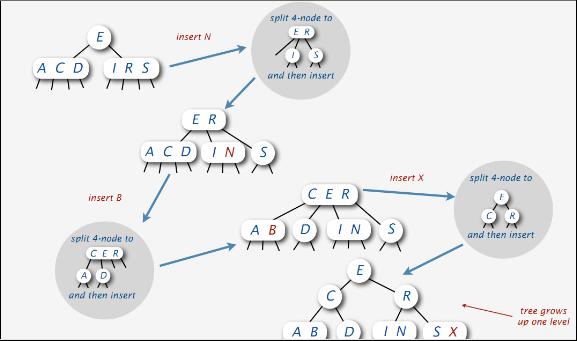
但下面,继续在上述的A、S、E、R、C、D、I插入操作的基础上之后,再依次插入N、B、X各元素时,情况,就比较复杂了,但下图还是很清晰的表明了各种插入操作及相关元素的调整情况,在此不赘述:
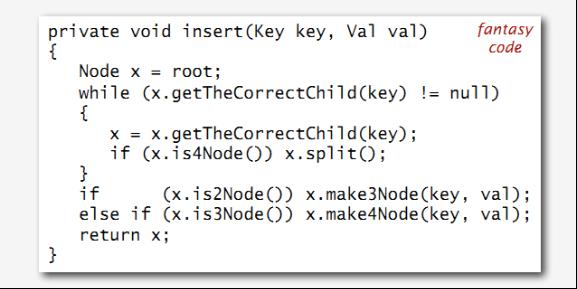
下图所示的是在2-3-4树中插入结点的insert代码:
到此,插入情况已经阐述完,删除情况略过。接下来,咱们来分析下2-3-4树的平衡情况。
1.3、2-3-4树的平衡
2-3-4树的高度为:
1、最坏情况,logn,树中全部都是2结点元素(即如第一节所述的全都是包含一个元素和2个儿子的结点。如此图所示,树中全部都是这样的结点:
2、最好情况,log4N=1/2logN,树中全部都是4结点元素(即如第一节所述的全都是包含 3 个元素和 4 个儿子 的结点,如此图所示,树中全部都是这样的结点:
3、3结点情况是中间情况,即包含 2 个元素和 3 个儿子,
。















 1204
1204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









