






最近在读《Introduction to Data Mining 》这本书,发现课后答案只有英文版,于是打算结合自己的理解将答案翻译一下,其中难免有错误,欢迎大家指正和讨论。侵删。
第八章(下)


(a)会有问题。比如有1000个点分为两个簇,一个簇900个点,另一个簇100个点,抽5%的样本,那么第一个簇抽取45个点,另一个簇抽5个点,那么这五个点相比较于50个点很可能被当作噪声。
(b)有问题。高维数据是典型的稀疏数据,因此需要很多点来确定结构。
(c)由定义,离群点是比较少的,在抽样的时候大部分离群点会被遗漏,因此抽样有助于这样的数据聚类。
(d)有问题。抽样后不规则区域的形状会丢失。
(e)没问题
(f)有问题。这样数据大部分来自密度高的区域。
(g)没问题。
(h)没问题。
(i)没问题。
(j)没问题。

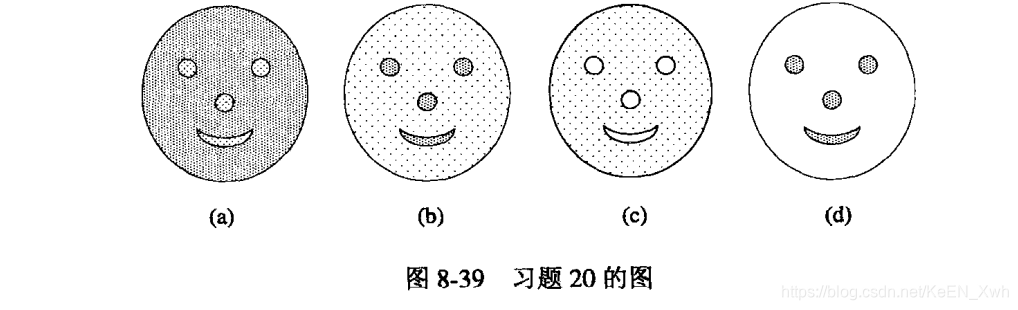
(a)只有b和d图可以。鼻子、眼睛和嘴区域里的点比其他区域距离更近。
(b)只有b和d图可以。b图中可能会把低密度的点包括进去,d图可以完美找到。
(c)聚类不能找到空白区域。



(a)有。由均匀分布产生的是随机的数据,会有密度高一点或低一点的区域,而均匀数据集没有。
(b)均匀数据集的SSE更小。
(c)会把所有数据划成一个簇或者全部当成噪声,取决于阈值。在随即数据集上,由于密度有些许变化,可以正常工作。
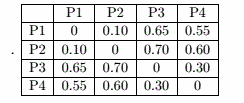

P1:SC = 1 - a/b = 1 - 0.1 / ((0.65+0.55)/2) = 0.8333
P2:SC = 1 - a/b = 1 - 0.1 / ((0.7+0.6)/2) = 0.846
P3:SC = 1 - a/b = 1 - 0.3 / ((0.65+0.7)/2) = 0.556
P4:SC = 1 - a/b = 1 - 0.3 / ((0.55+0.6)/2) = 0.478
簇1平均SC = ( 0.833 + 0.846 ) / 2 = 0.84
簇2平均SC = ( 0.556 + 0.478 ) / 2 = 0.52
总平均SC = ( 0.84 + 0.517 ) / 2 = 0.68

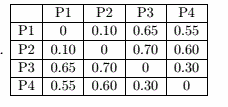
理想的相似度矩阵转化成向量x=<1,0,0,0,0,1>,该相似度矩阵转化成向量y=<0.8,0.65,0.55,0.7,0.6,0.3>
方差σx = 0.5164
方差σy = 0.1703
cov(x,y) = -0.2
corr(x,y) = cov(x,y) / σxσy = -0.227
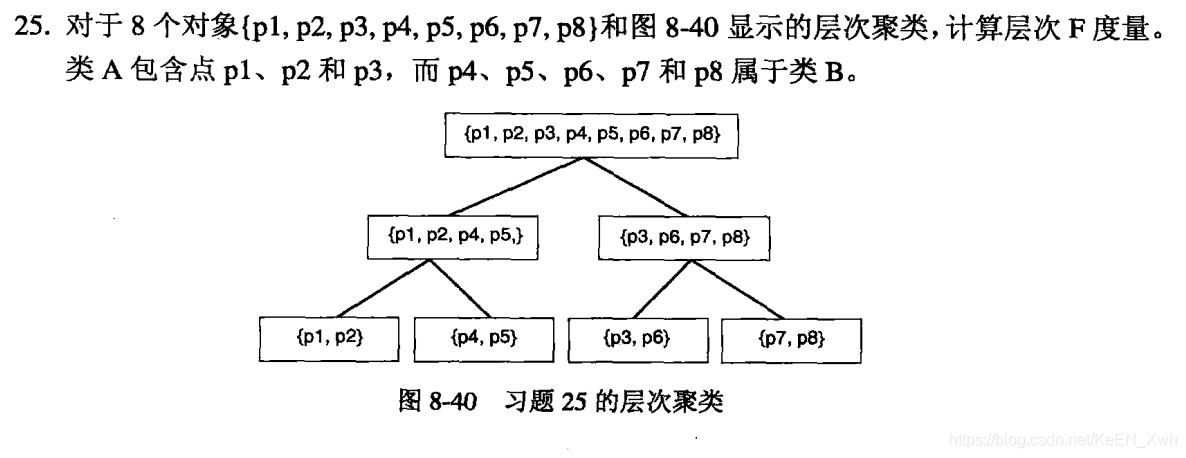
簇1{p1,p2,p3,p4,p5,p6,p7,p8}:
class = A:
R(A,1) = 3/3 = 1,P(A,1) = 3/8 = 0.375,F(A,1) = 2 × 1 × 0.375 / ( 1 + 0.375 ) = 0.55
class = B:
R(B,1) = 5/5 = 1,P(B,1) = 5/8 = 0.625,F(B,1) = 2 × 1 × 0.625 / ( 1 + 0.625 ) = 0.77
簇2{p1,p2,p4,p5}:
class = A:
R(A,2) = 2/3 ,P(A,2) = 2/4,F(A,2) =0.57
class = B:
R(B,2) = 2/5 ,P(B,2) = 2/4 ,F(B,2) =0.44
簇3{p3,p6,p7,p8}:
class = A:
R(A,3) = 1/3 ,P(A,3) = 1/4,F(A,3) =0.29
class = B:
R(B,3) = 3/5 ,P(B,3) = 3/4 ,F(B,3) =0.67
簇4{p1,p2}:
class = A:
R(A,4) = 2/3 ,P(A,4) = 2/2,F(A,4) =0.8
class = B:
R(B,4) = 0/5 ,P(B,4) = 0/2 ,F(B,4) =0
簇5{p4,p5}:
class = A:
R(A,5) = 0 ,P(A,5) = 0,F(A,5) =0
class = B:
R(B,5) = 2/5 ,P(B,5) = 2/2 ,F(B,5) =0.57
簇6{p3,p6}:
class = A:
R(A,6) = 1/3 ,P(A,6) = 1/2,F(A,6) =0.4
class = B:
R(B,6) = 1/5 ,P(B,6) = 1/2 ,F(B,6) =0.29
簇7{p7,p8}:
class = A:
R(A,7) = 0,P(A,7) = 1,F(A,7) =0
class = B:
R(B,7) = 2/5 ,P(B,7) = 2/2 ,F(B,7) =0.57
classA:F(A) = max{F(A,j)} = 0.8
classB:F(B) = max{F(B,j)} = 0.77
F = 3/8 × 0.8 + 5/8 ×0.77 = 0.78

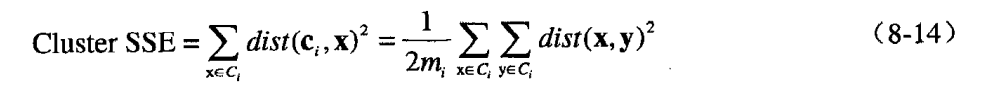
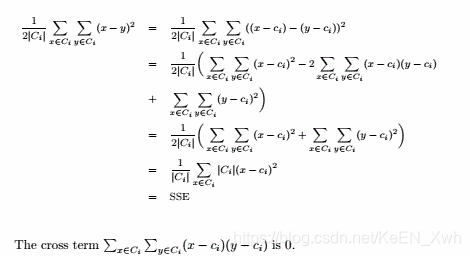
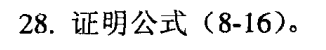
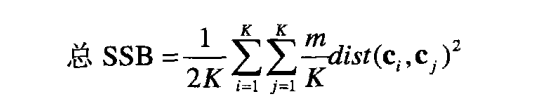


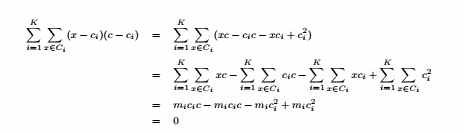

(a)最高项定义的簇可能有重复,并且只会出现少部分项,但K均值会覆盖所有的项且不会重复。
(b)用文档簇中的最高文档来定义。

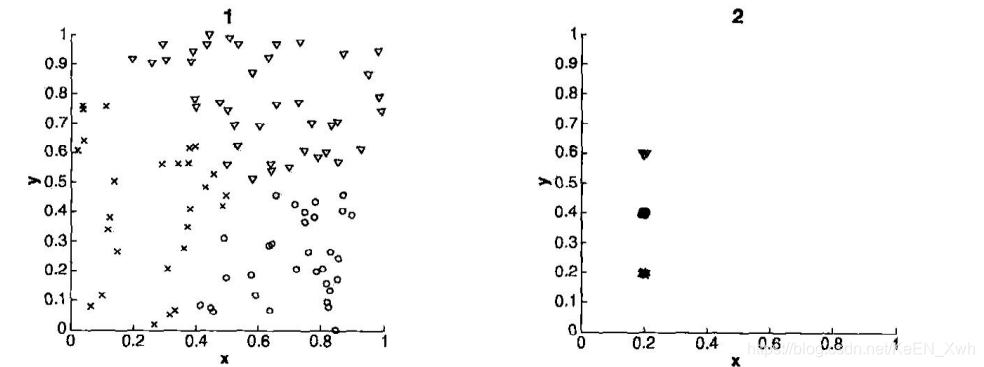
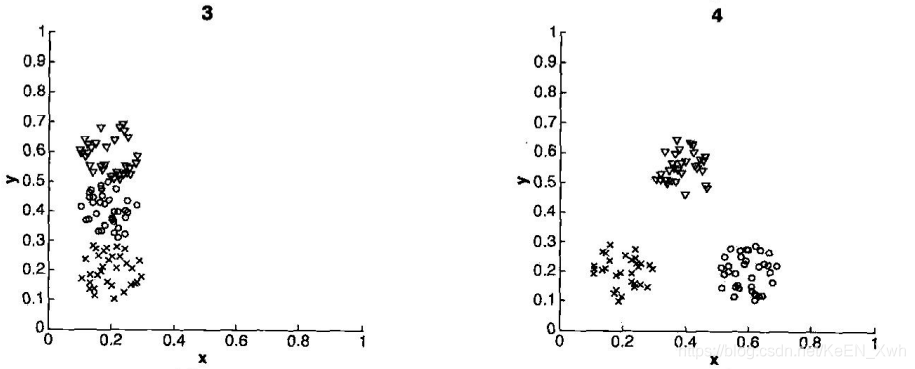
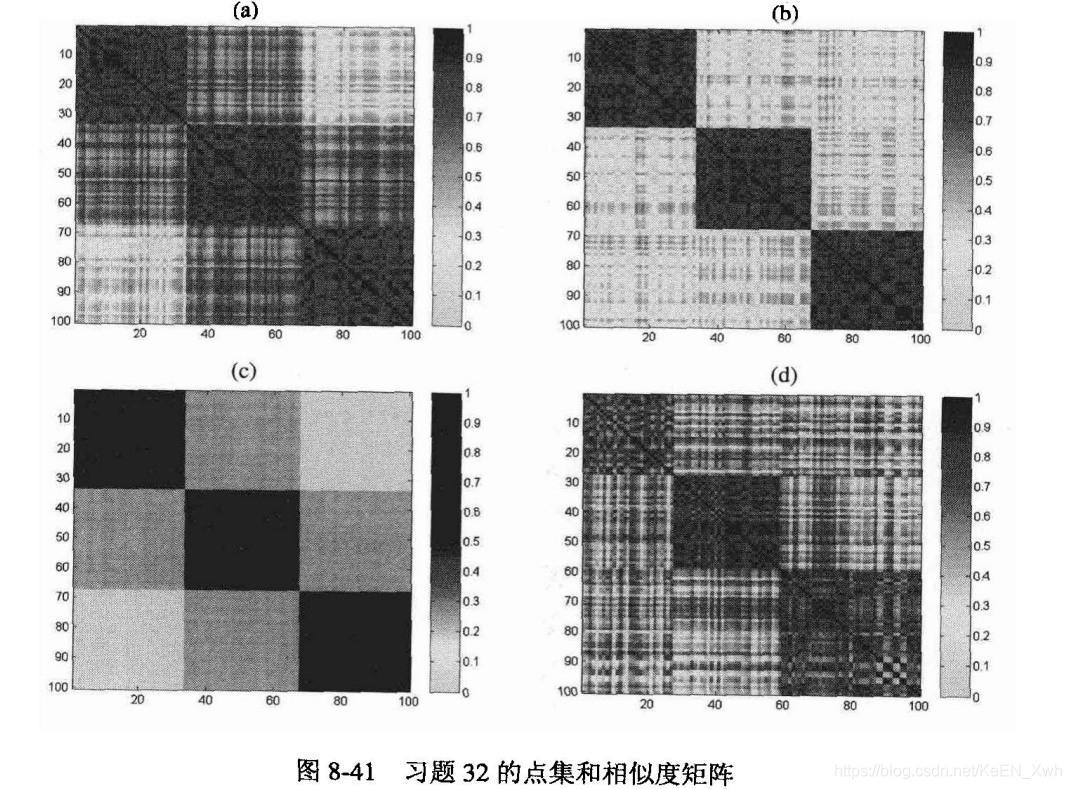
答:1-D 2-C 3-A 4-B














 4183
4183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









