









转载:redis 慢查询日志
一、Redis单线程模型
Redis的事件循环在一个线程中处理,作为一个单线程程序,重要的是要保证事件处理的时延短,这样,事件循环中的后续任务才不会阻塞; 当redis的数据量达到一定级别后(比如20G),阻塞操作对性能的影响尤为严重;
二、Redis高耗时操作
1. keys、sort等命令
keys命令用于查找所有符合给定模式 pattern 的 key,时间复杂度为O(N), N 为数据库中 key 的数量。当数据库中的个数达到千万时,这个命令会造成读写线程阻塞数秒;类似的命令有sunion sort等操作;
如果业务需求中一定要使用keys、sort等操作怎么办?
解决方案:

在架构设计中,有“分流”一招,说的是将处理快的请求和处理慢的请求分离来开,否则,慢的影响到了快的,让快的也快不起来;这在redis的设计中体现的非常明显,redis的纯内存操作,epoll非阻塞IO事件处理,这些快的放在一个线程中搞定,而持久化,AOF重写、Master-slave同步数据这些耗时的操作就单开一个进程来处理,不要慢的影响到快的;
同样,既然需要使用keys这些耗时的操作,那么我们就将它们剥离出去,比如单开一个redis slave结点,专门用于keys、sort等耗时的操作,这些查询一般不会是线上的实时业务,查询慢点就慢点,主要是能完成任务,而对于线上的耗时快的任务没有影响;
2. smembers命令
smembers命令用于获取集合全集,时间复杂度为O(N),N为集合中的数量;如果一个集合中保存了千万量级的数据,一次取回也会造成事件处理线程的长时间阻塞;
解决方案:
和sort,keys等命令不一样,smembers可能是线上实时应用场景中使用频率非常高的一个命令,这里分流一招并不适合,我们更多的需要从设计层面来考虑;
在设计时,我们可以控制集合的数量,将集合数一般保持在500个以内;
比如原来使用一个键来存储一年的记录,数据量大,我们可以使用12个键来分别保存12个月的记录,或者365个键来保存每一天的记录,将集合的规模控制在可接受的范围;
如果不容易将集合划分为多个子集合,而坚持用一个大集合来存储,那么在取集合的时候可以考虑使用
SRANDMEMBER key [count];3. save命令
save命令使用事件处理线程进行数据的持久化;当数据量大的时候,会造成线程长时间阻塞(我们的生产上,reids内存中1个G保存需要12s左右),整个redis被block;
save阻塞了事件处理的线程,我们甚至无法使用redis-cli查看当前的系统状态,造成“何时保存结束,目前保存了多少”这样的信息都无从得知;
解决方案:
我没有想到需要用到save命令的场景,任何时候需要持久化的时候使用bgsave都是合理的选择(当然,这个命令也会带来问题,后面聊到);
4. fork所带来的延时
在redis需要执行耗时的操作时,会新建一个进程来做,比如数据持久化bgsave:
开启RDB持久化后,当达到持久化的阈值,redis会fork一个新的进程来做持久化,采用了操作系统的copy-on-wirte写时复制策略,子进程与父进程共享Page。如果父进程的Page(每页4K)有修改,父进程自己创建那个Page的副本,不会影响到子进程;
fork新进程时,虽然可共享的数据内容不需要复制,但会复制之前进程空间的内存页表,如果内存空间有40G(考虑每个页表条目消耗 8 个字节),那么页表大小就有80M,这个复制是需要时间的,如果使用虚拟机,特别是Xen虚拟服务器,耗时会更长;
在我们有的服务器结点上测试,35G的数据bgsave瞬间会阻塞200ms以上;
类似的,以下这些操作都有进程fork;
1. Master向slave首次同步数据:当master结点收到slave结点来的syn同步请求,会生成一个新的进程,将内存数据dump到文件上,然后再同步到slave结点中;
2. AOF日志重写:使用AOF持久化方式,做AOF文件重写操作会创建新的进程做重写;(重写并不会去读已有的文件,而是直接使用内存中的数据写成归档日志);
解决方案:
为了应对大内存页表复制时带来的影响,有些可用的措施:
1. 控制每个redis实例的最大内存量;
不让fork带来的限制太多,可以从内存量上控制fork的时延; 一般建议不超过20G,可根据自己服务器的性能来确定(内存越大,持久化的时间越长,复制页表的时间越长,对事件循环的阻塞就延长) ,新浪微博给的建议是不超过20G,而我们虚机上的测试,要想保证应用毛刺不明显,可能得在10G以下;
2. 使用大内存页,
默认内存页使用4KB,这样,当使用40G的内存时,页表就有80M;而将每个内存页扩大到4M,页表就只有80K;这样复制页表几乎没有阻塞,同时也会提高快速页表缓冲TLB(translation lookaside buffer)的命中率;但大内存页也有问题,在写时复制时,只要一个页快中任何一个元素被修改,这个页块都需要复制一份(COW机制的粒度是页面),这样在写时复制期间,会耗用更多的内存空间;
3. 使用物理机;
如果有的选,物理机当然是最佳方案,比上面都要省事; 当然,虚拟化实现也有多种,除了Xen系统外,现代的硬件大部分都可以快速的复制页表,但公司的虚拟化一般是成套上线的,不会因为我们个别服务器的原因而变更,如果面对的只有Xen,只能想想如何用好它;
4. 杜绝新进程的产生,不使用持久化,不在主结点上提供查询;实现起来有以下方案:
1) 只用单机,不开持久化,不挂slave结点。这样最简单,不会有新进程的产生;但这样的方案只适合缓存;
如何来做这个方案的高可用?
要做高可用,可以在写redis的前端挂上一个消息队列,在消息队列中使用pub-sub来做分发,保证每个写操作至少落到2个结点上;因为所有结点的数据相同,只需要用一个结点做持久化,这个结点对外不提供查询;
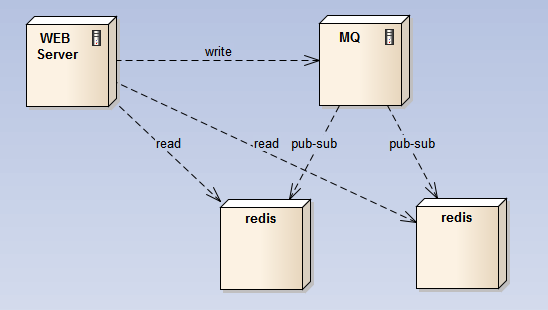
2) master-slave:在主结点上开持久化,主结点不对外提供查询,查询由slave结点提供,从结点不提供持久化;这样,所有的fork耗时的操作都在主结点上,而查询请求由slave结点提供;
这个方案的问题是主结点坏了之后如何处理?
简单的实现方案是主不具有可替代性,坏了之后,redis集群对外就只能提供读,而无法更新;待主结点启动后,再继续更新操作;对于之前的更新操作,可以用MQ缓存起来,等主结点起来之后消化掉故障期间的写请求;

如果使用官方的Sentinel将从升级为主,整体实现就相对复杂了;需要更改可用从的ip配置,将其从可查询结点中剔除,让前端的查询负载不再落在新主上;然后,才能放开sentinel的切换操作,这个前后关系需要保证;
5. 持久化造成的阻塞
执行持久化(AOF / RDB snapshot)对系统性能有较大影响,特别是服务器结点上还有其它读写磁盘的操作时(比如,应用服务和redis服务部署在相同结点上,应用服务实时记录进出报日志);应尽可能避免在IO已经繁重的结点上开Redis持久化;
子进程持久化时,子进程的write和主进程的fsync冲突造成阻塞
在开启了AOF持久化的结点上,当子进程执行AOF重写或者RDB持久化时,出现了Redis查询卡顿甚至长时间阻塞的问题, 此时, Redis无法提供任何读写操作;
原因分析:
Redis 服务设置了 appendfsync everysec, 主进程每秒钟便会调用 fsync(), 要求内核将数据”确实”写到存储硬件里. 但由于服务器正在进行大量IO操作, 导致主进程 fsync()/操作被阻塞, 最终导致 Redis 主进程阻塞.
redis.conf中是这么说的:
When the AOF fsync policy is set to always or everysec, and a background saving process (a background save or AOF log background rewriting) is performing a lot of I/O against the disk, in some Linux configurations Redis may block too long on the fsync() call. Note that there is no fix for this currently, as even performing fsync in a different thread will block our synchronous write(2) call. 当执行AOF重写时会有大量IO,这在某些Linux配置下会造成主进程fsync阻塞;
解决方案:
设置 no-appendfsync-on-rewrite yes, 在子进程执行AOF重写时, 主进程不调用fsync()操作;注意, 即使进程不调用 fsync(), 系统内核也会根据自己的算法在适当的时机将数据写到硬盘(Linux 默认最长不超过 30 秒). 这个设置带来的问题是当出现故障时,最长可能丢失超过30秒的数据,而不再是1秒;
子进程AOF重写时,系统的sync造成主进程的write阻塞
我们来梳理下:
1) 起因:有大量IO操作write(2) 但未主动调用同步操作
2) 造成kernel buffer中有大量脏数据
3) 系统同步时,sync的同步时间过长
4) 造成redis的写aof日志write(2)操作阻塞;
5) 造成单线程的redis的下一个事件无法处理,整个redis阻塞(redis的事件处理是在一个线程中进行,其中写aof日志的write(2)是同步阻塞模式调用,与网络的非阻塞write(2)要区分开来)
产生1)的原因:这是redis2.6.12之前的问题,AOF rewrite时一直埋头的调用write(2),由系统自己去触发sync。
另外的原因:系统IO繁忙,比如有别的应用在写盘;
解决方案:
控制系统sync调用的时间;需要同步的数据多时,耗时就长;缩小这个耗时,控制每次同步的数据量;通过配置按比例(vm.dirty_background_ratio)或按值(vm.dirty_bytes)设置sync的调用阈值;(一般设置为32M同步一次) (2.6.12以后,AOF rewrite 32M时会主动调用fdatasync)。
另外,Redis当发现当前正在写的文件有在执行fdatasync(2)时,就先不调用write(2),只存在cache里,免得被block。但如果已经超过两秒都还是这个样子,则会强行执行write(2),即使redis会被block住。
AOF重写完成后合并数据时造成的阻塞
在bgrewriteaof过程中,所有新来的写入请求依然会被写入旧的AOF文件,同时放到AOF buffer中,当rewrite完成后,会在主线程把这部分内容合并到临时文件中之后才rename成新的AOF文件,所以rewrite过程中会不断打印"Background AOF buffer size: 80 MB, Background AOF buffer size: 180 MB",要监控这部分的日志。这个合并的过程是阻塞的,如果产生了280MB的buffer,在100MB/s的传统硬盘上,Redis就要阻塞2.8秒;
解决方案:
将硬盘设置的足够大,将AOF重写的阈值调高,保证高峰期间不会触发重写操作;在闲时使用crontab 调用AOF重写命令;
三、Slowlog慢查询日志
redis 慢查询日志, 是系统记录那些超过指定查询时间的日志. 执行的时间不包括和客户端的IO操作,和响应时间等, 而只是实际redis执行命令的时间(只是线程执行命令时,阻塞不能在接受处理其他请求花费的时间)
慢查询日志有两个参数:
slowlog-log-slower-than: 单位微妙,指定redis执行命令的最大时间,超过将记录到慢查询日志中,
不接受负值,如果设置为0,每条命令都要记录到慢查询日志中.
slowlog-max-len: 设置慢查询日志长度,如果慢查询日志已经到最大值,如果有新命令需要记录,就将最老那条记录删除.
读取慢查询日志
慢查询日志是会存储在内存中, 没有文件存储慢查询日志内容. 所以在获取慢查询日志时候,会响应非常快. 对性能影响很小.
获取慢查询日志可以使用 slowlog get 命令, 将会所有的慢查询记录. 获取指定数量的慢查询使用:
redis 127.0.0.1:6379> slowlog get 2
1) 1) (integer) 14
2) (integer) 1309448221
3) (integer) 15
4) 1) "ping"
2) 1) (integer) 13
2) (integer) 1309448128
3) (integer) 30
4) 1) "slowlog"
2) "get"
3) "100"返回的每个慢查询实体,都由四个字段组成
1. 第一个字段是每个慢查询 唯一标识。
2. 处理完命令后的, Unix 时间戳
3. 执行该命令所需要的 时间,单位微妙
4. 命令的参数列表,是个 数组类型
每个慢查询实体的ID都是唯一的,而且不会被重新设置,只会在redis重启后才会重置它。
查看当前慢查询日志长度
Slowlog len
清空慢查询日志内容
SLOWLOG RESET















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









