






一文搞懂并实战:HDFS分布式文件系统搭建全过程详解(含图文+踩坑记录)
前言
在大数据技术体系中,Hadoop Distributed File System(HDFS) 是最核心的分布式文件存储系统,它为后续的数据处理与分析奠定了坚实的基础。很多学习大数据的同学在初学阶段,往往会被环境配置、集群部署等问题困扰。本篇文章将通过从零开始的方式,带你完成一次完整的HDFS搭建实践,结合笔者的真实踩坑经历,提供配置说明、问题排查思路、性能调优建议等,力求让每一位读者都能顺利搭建起自己的HDFS环境。
一、HDFS简介
1.1 什么是HDFS?
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目中的核心组件之一,专为处理大数据场景下的文件存储而设计,具备以下特点:
- 高容错性:节点失效不会导致数据丢失;
- 高吞吐量:支持大规模数据的批量读写;
- 数据冗余存储:默认每份数据保留三个副本;
- 适合大文件:不适合小文件频繁读写场景。
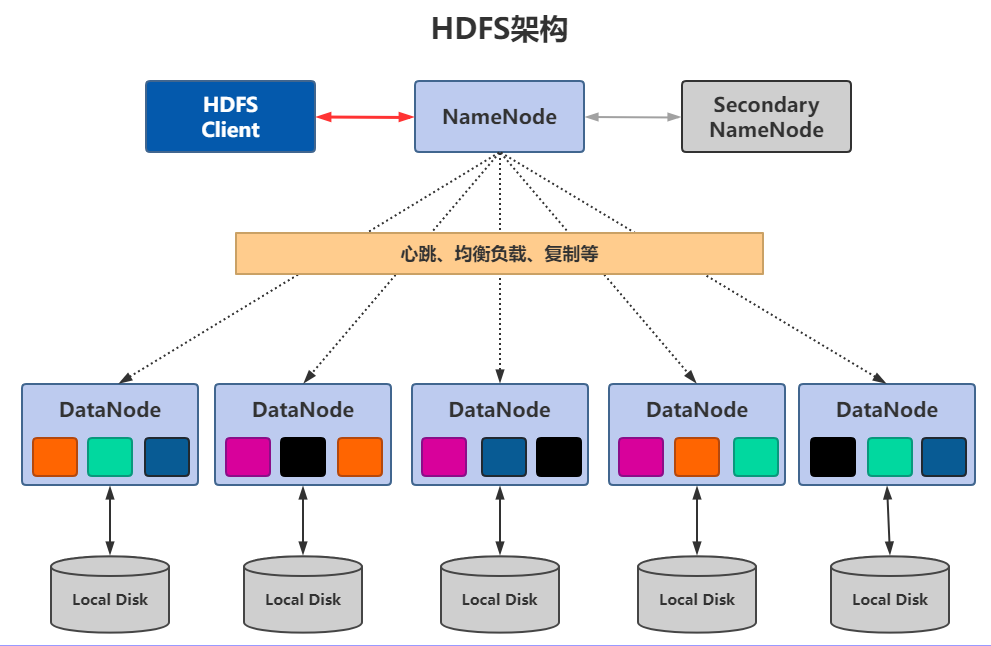
1.2 HDFS架构图解
HDFS主要由两个核心角色构成:
- NameNode(主节点):负责管理元数据,如文件路径、块位置、权限等;
- DataNode(数据节点):负责真正存储数据块。
此外,还有一个辅助节点:
- Secondary NameNode:用于协助 NameNode 进行元数据快照合并。
二、部署前准备
2.1 环境规划
| 主机名 | IP地址 | 角色 |
|---|---|---|
| bigdata01 | 192.168.175.132 | NameNode、Secondary,ResourceManager、NodeManager、DataNode |
| bigdata02 | 192.168.175.133 | DataNode、SecondaryNameNode、NodeManager |
| bigdata03 | 192.168.175.134 | DataNode、NodeManager |
2.2 软件准备
Hadoop版本:3.3.1
JDK版本:1.8+
操作系统:CentOS 7(或Ubuntu 20.04)
2.3 前置条件
- 所有节点已安装 Java 并配置环境变量;
- 所有节点已配置 SSH 无密码登录;
- 所有节点之间可以互通;
- 关闭防火墙(或放行端口);
- 所有节点时间同步(建议使用
ntpd)。
三、Hadoop安装与配置
3.1 解压与环境变量配置
将 hadoop-3.3.6.tar.gz 上传至各节点,并解压:
tar -zxvf hadoop-3.3.1.tar.gz -C /opt/
mv /opt/hadoop-3.3.6 /opt/hadoop

添加环境变量 /etc/profile:
export JAVA_HOME=/opt/installation/jdk
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/installation/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行 source /etc/profile 生效。
3.2 配置核心文件
(1)core-site.xml
配置 HDFS 的默认文件系统地址:
<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端⼝9000 hadoop2.x时代默认端⼝8020 hadoop3.x时 代默认端⼝ 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的⼀个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/installation/hadoop/tmp</value>
</property>
</configuration>
(2)hdfs-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondarynamenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata02:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata01:9870</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
(3)mapred-site.xml(可选)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(4)hadoop-env.sh
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export JAVA_HOME=/opt/installs/jdk
(5)修改workers 文件:
bigdata02
bigdata03
3.3 SSH免密配置
ssh-keygen -t rsa
ssh-copy-id bigdata01
ssh-copy-id bigdata02
ssh-copy-id bigdata03
四、格式化并启动HDFS
hdfs namenode -format
4.2 启动HDFS集群
start-dfs.sh
验证是否启动成功:
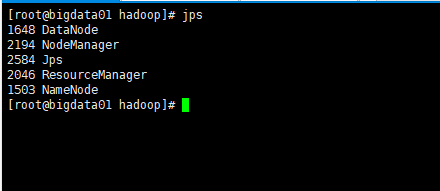
你应能在 bigdata01上看到 NameNode 和 SecondaryNameNode,在各 从节点上看到 DataNode。
五、Web界面访问与操作
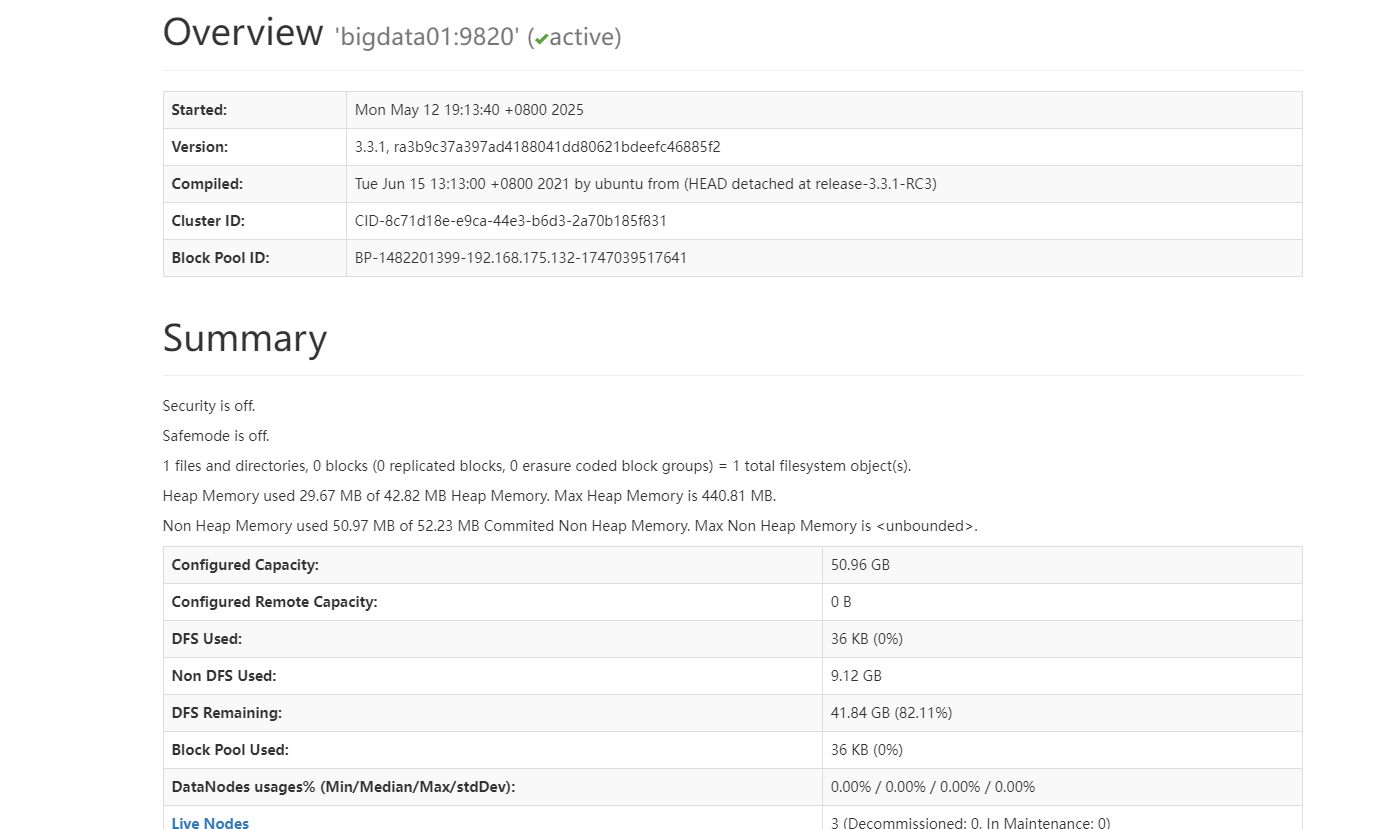
5.1 Web UI地址
你可以在浏览器中查看当前 HDFS 的文件树、DataNode 状态、副本情况等。
六、HDFS基本操作命令
6.1 文件上传
hdfs dfs -mkdir /input
hdfs dfs -put ./test.txt /input
6.2 文件查看
hdfs dfs -ls /input
hdfs dfs -cat /input/test.txt
6.3 文件下载
hdfs dfs -get /input/test.txt ./local/
七、常见错误与排查
| 问题 | 原因 | 解决方案 |
|---|---|---|
| NameNode无法启动 | 文件系统未格式化 | 执行 hdfs namenode -format |
| slaves 无法识别 | workers 文件未正确配置或未分发 | 确保 slaves 文件存在于 $HADOOP_HOME/etc/hadoop |
| - | ||
| NameNode无法启动 | 文件系统未格式化 | 执行 hdfs namenode -format |
| slaves 无法识别 | workers 文件未正确配置或未分发 | 确保 slaves 文件存在于 $HADOOP_HOME/etc/hadoop |
| 浏览器访问失败 | 未开启 9870 端口 | 检查防火墙,或使用 firewalld 放行 |

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









