







假设有这样一个需求:在20亿个随机整数中找出某个数m是否存在其中,并假设32位操作系统,4G内存
按照惯例,用int存储数据的话,在Java中,int占4字节,1字节=8位(1 byte = 8 bit),一共20亿个int,因而占用的空间约(2000000000*4/1024/1024/1024)≈7.45G
很可怕对吧,那如果用Bitmap存呢?只需要0.233G。
嘶,这也太强了,为什么这么强呢?到底怎么算的呢?
一、基本实现
Bit-map的基本思想就是用一个bit位来标记某个元素对应的Value,而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。
1字节=8位(1 byte = 8 bit),20亿个数就是20亿位,占用空间就约为(2000000000/8/1024/1024/1024)≈0.233G。
那么,问题来了,按位存储如何表示一个数呢?
其实很简单,每一位表示一个数,0表示不存在,1表示存在,这正符合二进制
比如,这样我们可以很容易表示{1,2,4,6}这几个数:

那么有人又要问了,计算机内存分配的最小单位是字节,也就是8位,那如果要表示{12,13,15}怎么办呢?当然是在另一个8位上表示了:

像不像一个二维数组呢?我们继续思考:
1个int占32位(每个int底层可以看作是一个32bit的数组),也就是可以表示32个数,如果我们需要存储的数据中的最大值是N,我们只需要申请一个int数组长度为 int tmp[1+N/32] 即可,于是乎:
tmp[0]:可以表示 0~31 是否存在
tmp[1]:可以表示 32~63 是否存在
tmp[2]:可以表示 64~95 是否存在
……
如此一来,给定任意整数M,M/32就得到下标,M%32就知道它在此下标的哪个位置
1.添加
先补充一个知识点:位运算
在数字没有溢出的前提下,对于正数和负数,左移一位都相当于乘以2的1次方,左移n位就相当于乘以2的n次方,右移一位相当于除2,右移n位相当于除以2的n次方。
<< 左移,相当于乘以2的n次方,例如:1<<6 相当于1×64=64,3<<4 相当于3×16=48
>> 右移,相当于除以2的n次方,例如:64>>3 相当于64÷8=8
^ 异或,相当于求余数,例如:48^32 相当于 48%32=16
继续思考,我们知道了一个数的位置,又怎么把这个数添加到该位置上呢?
例如,想把5这个数字放进去,怎么做呢?
首先,5/32=0,5%32=5,也是说它应该在tmp[0]的第5个位置,那我们把1向左移动5位,然后按位或。如图:

换成二进制就是

再换成10进制就相当于 86 | 32 = 118,即:86 | (1<<5) = 118
所以:b[0] = b[0] | (1<<5)
也就是说,要想插入一个数,将1左移带代表该数字的那一位,然后与原数进行按位或操作
化简一下,就是 b[5/32] = b[5/32] | (1<<(5%32))
因此,公式可以概括为:b[i/32] = b[(i/32)] | (1<<(i%32)) 其中,i表示待插入的数
2.清除
以上是添加,那如果要清除该怎么做呢?
还是上面的例子,假设我们要6移除,该怎么做呢?
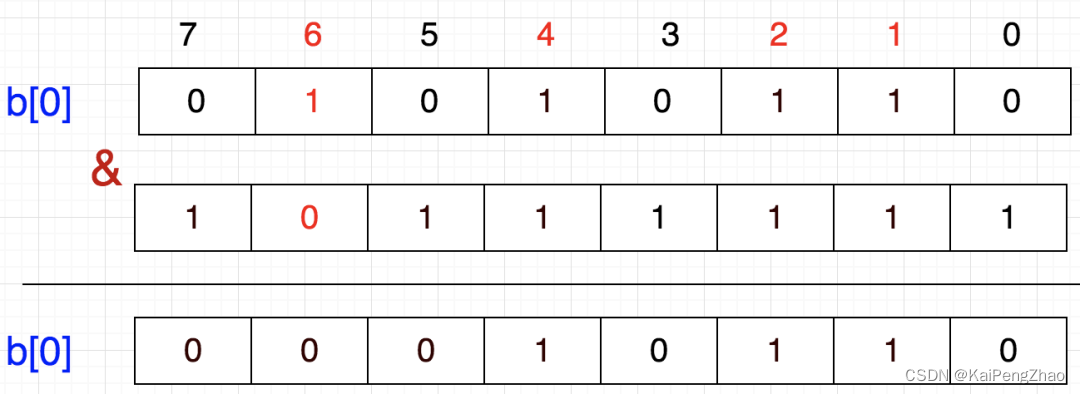
从图上看,只需将该数所在的位置为0即可
1左移6位,就到达6这个数字所代表的位,然后按位取反,最后与原数按位与,这样就把该位置为0了
b[0] = b[0] & (~(1<<6))
因此,公式可以概括为:b[i/32] = b[i/32] & (~(1<<(i%32))) 其中,i表示待删除的数
3.查找
这就比较简单了,前面我们说每一位代表一个数字,1表示有(或者说存在),0表示无(或者说不存在)。
通过把该为置为1或者0来达到添加和清除的效果,那么判断一个数存不存在就是判断该数所在的位是0还是1
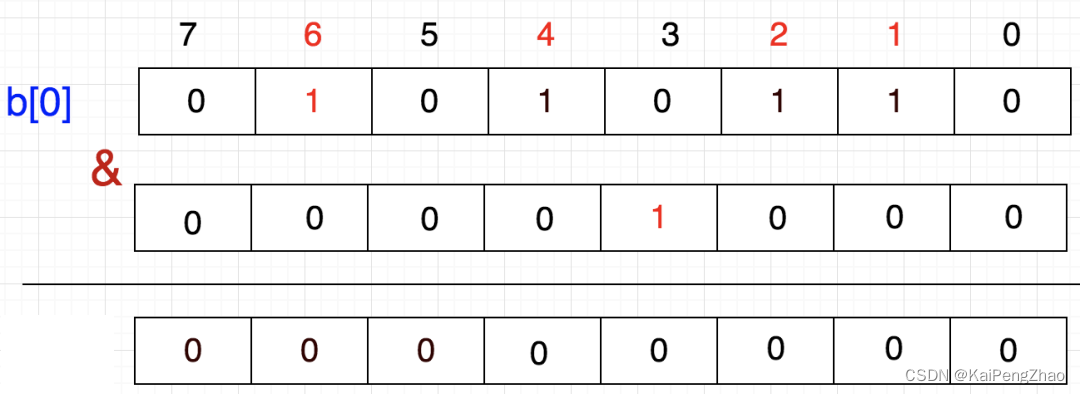
假设,我们想知道3在不在,那么只需判断 b[0] & (1<<3) 是否等于0,若是,则不存在;否则,就表示存在。
二、 实际应用
Bitmap主要用于快速检索关键字状态,通常要求关键字是一个连续的序列(或者关键字是一个连续序列中的大部分), 最基本的情况,使用1bit表示一个关键字的状态(可标示两种状态),但根据需要也可以使用2bit(表示4种状态),3bit(表示8种状态)。
Bitmap的主要应用场合:表示连续(或接近连续,即大部分会出现)的关键字序列的状态(状态数/关键字个数 越小越好)。
32位机器上,对于一个整型数,比如int a=1 在内存中占32bit位,这是为了方便计算机的运算。但是对于某些应用场景而言,这属于一种巨大的浪费,因为我们可以用对应的32bit位对应存储十进制的0-31个数,而这就是Bit-map的基本思想。
Bit-map算法利用这种思想处理大量数据的快速排序、查找、去重
1.快速排序
假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复),我们就可以采用Bit-map的方法来达到排序的目的。
要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0,然后将对应位置为1。
最后,遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的,时间复杂度O(n)。
在java中用BitSet实现了BitMap思想,我们也可以自己手写BitMap
@Test
public void bitmapSample() {
int [] array = new int [] {1,2,3,22,0,6};
BitSet bitSet = new BitSet(6); //将数组内容组bitmap
for(int i = 0; i<array.length; i++)
{
bitSet.set(array[i], true);
} //遍历存在的数据
int asInt = Arrays.stream(array).max().getAsInt();
for(int i = 0; i<=asInt; i++)
{ if (bitSet.get(i)){
System.out.println(i);
}
}
System.out.println("实际使用大小:"+bitSet.length());
System.out.println("逻辑大小:"+bitSet.size());
System.out.println("是否存在22:"+bitSet.get(22));
}输出结果:
0
1
2
3
6
22
实际使用大小:23
逻辑大小:64
是否存在22:true实际使用大小:23逻辑大小:64是否存在22:true
优点:
- 运算效率高,不需要进行比较和移位;
- 占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M
缺点:
- 所有的数据不能重复。即不可对重复的数据进行排序和查找。
- 只有当数据比较密集时才有优势
2.快速去重
20亿个整数中找出不重复的整数的个数,内存不足以容纳这20亿个整数。
首先,根据“内存空间不足以容纳这05亿个整数”我们可以快速的联想到Bit-map。
下边关键的问题就是怎么设计我们的Bit-map来表示这20亿个数字的状态了。
一个数字的状态只有三种,分别为不存在,只有一个,有重复。因此,我们只需要2bits就可以对一个数字的状态进行存储了,假设我们设定一个数字不存在为00,存在一次01,存在两次及其以上为11。那我们大概需要存储空间2G左右。
接下来的任务就是把这20亿个数字放进去(存储),如果对应的状态位为00,则将其变为01,表示存在一次;如果对应的状态位为01,则将其变为11,表示已经有一个了,即出现多次;如果为11,则对应的状态位保持不变,仍表示出现多次。
最后,统计状态位为01的个数,就得到了不重复的数字个数,时间复杂度为O(n)。
3.快速查找
这就是我们前面所说的了,int数组中的一个元素是4字节占32位,那么除以32就知道元素的下标,对32求余数(%32)就知道它在哪一位,如果该位是1,则表示存在。
最初让大家思考的问题也可以这么解决。
三、手写BitMap
public class BitMap { //保存数据的
private byte[] bits;
//能够存储多少数据
private int capacity;
public BitMap(int capacity){ this.capacity = capacity;
//1bit能存储8个数据,那么capacity数据需要多少个bit呢,capacity/8+1,右移3位相当于除以8
bits = new byte[(capacity >>3 )+1];
}
public void add(int num){ // num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后和以前的数据做|,这样,那个位置就替换成1了。
bits[arrayIndex] |= 1 << position;
}
public boolean contain(int num){ // num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后和以前的数据做&,判断是否为0即可
return (bits[arrayIndex] & (1 << position)) !=0;
}
public void clear(int num){ // num/8得到byte[]的index
int arrayIndex = num >> 3;
// num%8得到在byte[index]的位置
int position = num & 0x07;
//将1左移position后,那个位置自然就是1,然后对取反,再与当前值做&,即可清除当前的位置了.
bits[arrayIndex] &= ~(1 << position);
}
public static void main(String[] args) {
BitMap bitmap = new BitMap(100);
bitmap.add(7);
System.out.println("插入7成功");
boolean isexsit = bitmap.contain(7);
System.out.println("7是否存在:"+isexsit);
bitmap.clear(7);
isexsit = bitmap.contain(7);
System.out.println("7是否存在:"+isexsit);
}
}四、BitMap的问题
BitMap 的思想在面试的时候还是可以用来解决不少问题的,然后在很多系统中也都会用到,算是一种不错的解决问题的思路。
但是 BitMap 也有一些局限,因此会有其它一些基于 BitMap 的算法出现来解决这些问题。
- 数据碰撞。比如将字符串映射到 BitMap 的时候会有碰撞的问题,那就可以考虑用 Bloom Filter 来解决,Bloom Filter使用多个 Hash 函数来减少冲突的概率。
- 数据稀疏。又比如要存入(10,8887983,93452134)这三个数据,我们需要建立一个 99999999 长度的 BitMap ,但是实际上只存了3个数据,这时候就有很大的空间浪费,碰到这种问题的话,可以通过引入 Roaring BitMap 来解决。
1. Bloom Filters
Bloom Filters可以解决redis的缓存穿透问题,所以会在redis相关内容仔细和大家聊。
Bloom filter 是一个数据结构,它可以用来判断某个元素是否在集合内,具有运行快速,内存占用小的特点。
而高效插入和查询的代价就是,Bloom Filter 是一个基于概率的数据结构:它只能告诉我们一个元素绝对不在集合内或可能在集合内。
Bloom filter 的基础数据结构是一个 比特向量(可理解为数组)。
主要应用于大规模数据下不需要精确过滤的场景,如检查垃圾邮件地址,爬虫URL地址去重,解决缓存穿透问题等
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(哈希表)等等数据结构都是这种思路,但是随着集合中元素的增加,需要的存储空间越来越大;同时检索速度也越来越慢,检索时间复杂度分别是O(n)、O(log n)、O(1)。
布隆过滤器的原理是,当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组(Bit array)中的 K 个点,把它们置为 1 。检索时,只要看看这些点是不是都是1就知道元素是否在集合中;如果这些点有任何一个 0,则被检元素一定不在;如果都是1,则被检元素很可能在(之所以说“可能”是误差的存在)。
BloomFilter 流程
- 首先需要 k 个 hash 函数,每个函数可以把 key 散列成为 1 个整数;
- 初始化时,需要一个长度为 n 比特的数组,每个比特位初始化为 0;
- 某个 key 加入集合时,用 k 个 hash 函数计算出 k 个散列值,并把数组中对应的比特位置为 1;
- 判断某个 key 是否在集合时,用 k 个 hash 函数计算出 k 个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
在实际工作中避免不了会处理大量的数据,学会Bitmap这种思想处理实际问题一定会得心应手。















 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









