







题目:单词接龙
Leetcode
给定两个单词(beginWord 和 endWord)和一个字典,找到从 beginWord 到 endWord 的最短转换序列的长度。转换需遵循如下规则:
每次转换只能改变一个字母。
转换过程中的中间单词必须是字典中的单词。
说明:
如果不存在这样的转换序列,返回 0。
所有单词具有相同的长度。
所有单词只由小写字母组成。
字典中不存在重复的单词。
你可以假设 beginWord 和 endWord 是非空的,且二者不相同。

解决方案
广度优先搜索BFS
每次只能改变一个字符,且等长。那么每改变一个字符,就会产生一个新的单词,而这个单词又可以继续一个字符,直到与目标单词相同。显然这里就构成了一个单词的搜索树。搜索树的深度就是我们需要改变的次数。题目想要求最少的转换次数,我们应该使用广度优先遍历。
易得一下代码:
class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
//BFS
//队列,同一层排除相同的
Set<String> queue = new HashSet<> ();
queue.add(beginWord);
Set<String> visited = new HashSet<>();
// 层数
int level = 0;
while(!queue.isEmpty()){
level ++;
Set<String> nextQueue = new HashSet<>();
// 遍历这一层
for(String str:queue){
visited.add(str);
int len = str.length();
//如果就是目标字符串,就直接返回结果
if (str.equals(endWord)){
return level;
}
//遍历每个位置字母
for(int i=0; i<len; i++){
// 从字典中选取可以转换的单词。
//注意这里要优化!!!
for(String word:wordList){
//排除自身
if(visited.contains(word)){
continue;
}
// 变更一个字符后可能的结果
if(isMatch(i,str, word)){
nextQueue.add(word);
}
}
}
}
queue = nextQueue;
}
return 0;
}
//判断某个单词除了位置i不一样外,其他是否相同。
// 即两个单词能否转换。
private boolean isMatch(int pos, String src, String tar){
int len = src.length();
for(int i = 0 ; i<len; i++){
if(i==pos){
continue;
}else if(src.charAt(i)!=tar.charAt(i)){
return false;
}
}
return true;
}
}
注意:
- 四层循环嵌套,这显然不是我们希望的到的时间复杂度。
- 而事实上,这个算法会超出时间限制。这个的问题在于在对某个查找某个单词的第i个位置转换时,都需要遍历一次字典。字典越长、单词越长,所需要的便利时间便上升。
- 对访问过的单词要记录到访问队列中,否则在无解的时候(不能通过return跳出循环),可能形成一个环无限循环、
优化:
对word list只进行一次遍历,然后把具有通用性的单词放到一起。
class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
//字典预处理
int len = beginWord.length();
// 通配符的字典
/*https://leetcode-cn.com/problems/word-ladder/solution/dan-ci-jie-long-by-leetcode/*/
Map<String, List<String>> allComboDict = new HashMap<>();
wordList.forEach(
word -> {
for (int i = 0; i < len; i++) {
// *ot *代表通配符,构造key
String newWord = word.substring(0, i) + '*' + word.substring(i + 1, len);
// 如果map里存在,就把队列拿出来,否则就创建一个。
List<String> transformations = allComboDict.getOrDefault(newWord, new ArrayList<>());
// 添加新的单词
transformations.add(word);
allComboDict.put(newWord, transformations);
}
});
//BFS
//队列,同一层排除相同的
Set<String> queue = new HashSet<> ();
queue.add(beginWord);
// 记录已经访问过的单词,这样能够大大降低冗余操作。
// 不是用这个超过时间限制或者形成环。无限循环
Set<String> visited = new HashSet<>();
// 层数
int level = 0;
while(!queue.isEmpty()){
level ++;
Set<String> nextQueue = new HashSet<>();
// 遍历这一层
for(String str:queue){
//如果就是目标字符串,就直接返回结果
if (str.equals(endWord)){
return level;
}
visited.add(str);
//遍历每个位置字母
for(int i=0; i<len; i++){
// 获取key
String key = str.substring(0, i) + '*' + str.substring(i + 1, len);
// 拿出统配的list
List<String> tarWordList = allComboDict.getOrDefault(key, new ArrayList<>());
// 遍历list
for (String word : tarWordList) {
// 如果就是当前的单词,则不加入下一层的队列中
if(visited.contains(word)){
continue;
}else{
nextQueue.add(word);
}
}
}
}
queue = nextQueue;
}
return 0;
}
}
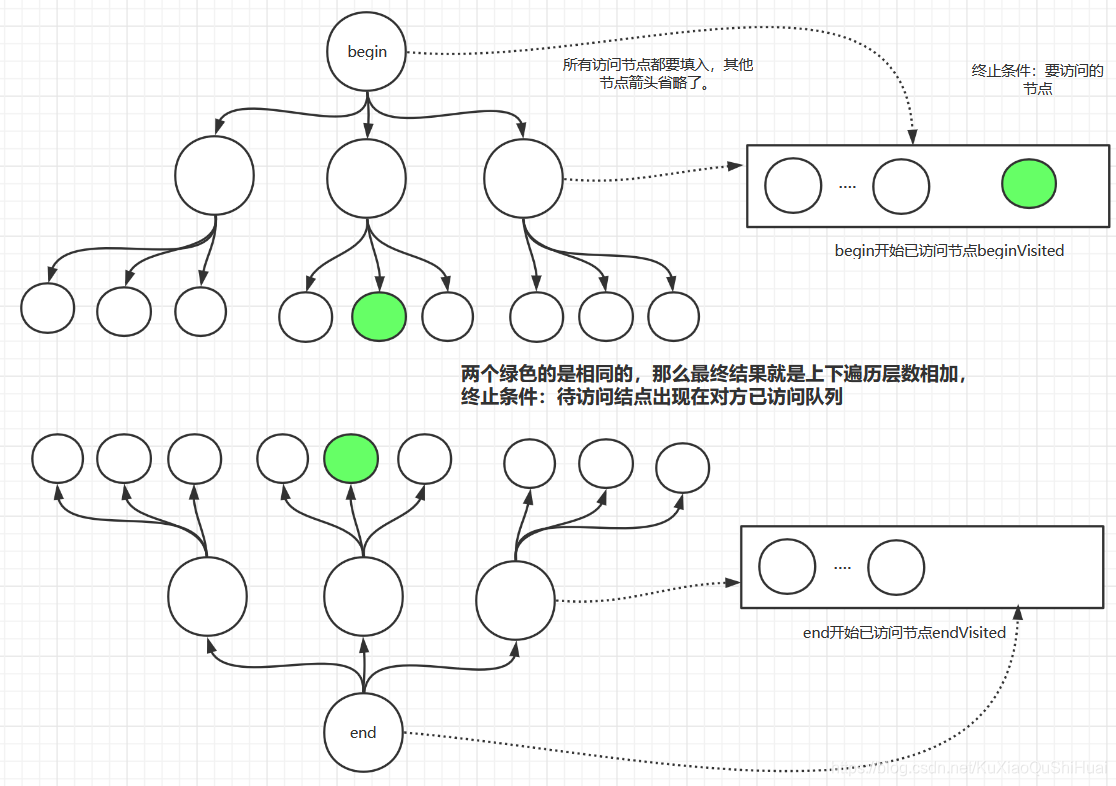
双向广度优先搜索
class Solution {
private Map<String, List<String>> allComboDict = new HashMap<String, List<String>>();
private int len;
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
// 两个访问队列, 每个节点是word和level
Queue<Pair<String, Integer>> beginQueue = new LinkedList<>();
Queue<Pair<String, Integer>> endQueue = new LinkedList<>();
// 已访问队列, 同时记录第几层访问了
Map<String, Integer> beginVisited = new HashMap<>();
Map<String, Integer> endVisited = new HashMap<>();
//注意放置
beginVisited.put(beginWord,1);
endVisited.put(endWord,1);
// 预处理wordList
this.len = beginWord.length();
wordList.forEach(word -> {
for (int i = 0; i < len; i++) {
// 构造通配单词
String newWord = word.substring(0, i) + "*" + word.substring(i + 1, len);
List<String> transFormations = allComboDict.getOrDefault(newWord, new ArrayList<>());
transFormations.add(word);
allComboDict.put(newWord, transFormations);
}
});
// 添加起始结点.由于begin和end一定不同,故至少一次转换。
beginQueue.add(new Pair<String, Integer>(beginWord, 1));
endQueue.add(new Pair<String, Integer>(endWord, 1));
// 注意:在双向BFS,即使endWord不在字典,仍可能通过变换一个字符和字典中出现的单词相同
// 这样就会和beginWord相遇。所以要先排除endWord不可达的情况。
if (!wordList.contains(endWord)) {
return 0;
}
while (!beginQueue.isEmpty() && !endQueue.isEmpty()) {
int ans = visitQueue(beginQueue, beginVisited, endVisited);
if (ans > -1) {
// 找到结果
return ans;
}
ans = visitQueue(endQueue, endVisited, beginVisited);
if (ans > -1) {
// 找到结果
return ans;
}
}
return 0;
}
private int visitQueue(Queue<Pair<String, Integer>> queue, Map<String, Integer> visited1,
Map<String, Integer> visited2) {
int size = queue.size();
// 获取节点
Pair<String, Integer> curPair = queue.poll();
// 获取单词
String curWord = curPair.getKey();
// 获取层级
int level = curPair.getValue();
for (int i = 0; i < this.len; i++) {
// 拼接成通用Map的key
String keyWord = curWord.substring(0, i) + '*' + curWord.substring(i + 1, this.len);
// 遍历
for (String word : allComboDict.getOrDefault(keyWord, new ArrayList<>())) {
// 另一个BFS已经访问过该节点
if (visited2.containsKey(word)) {
// 返回curWord的层级+另一个bfs遍历的层
return level + visited2.get(word);
}
// 本BFS没有访问过该节点
if (!visited1.containsKey(word)) {
// 添加到访问中
visited1.put(word, level+1);
queue.add(new Pair(word, level + 1));
}
}
}
return -1;
}
}
注意:
- 队列是节点里面包含了层级信息,所以就不需要像之前一样使用size来确定遍历某一层了。
- 注意已访问队列的放置时机。将要访问的节点放入队列的同时,就要放到visited队列中。
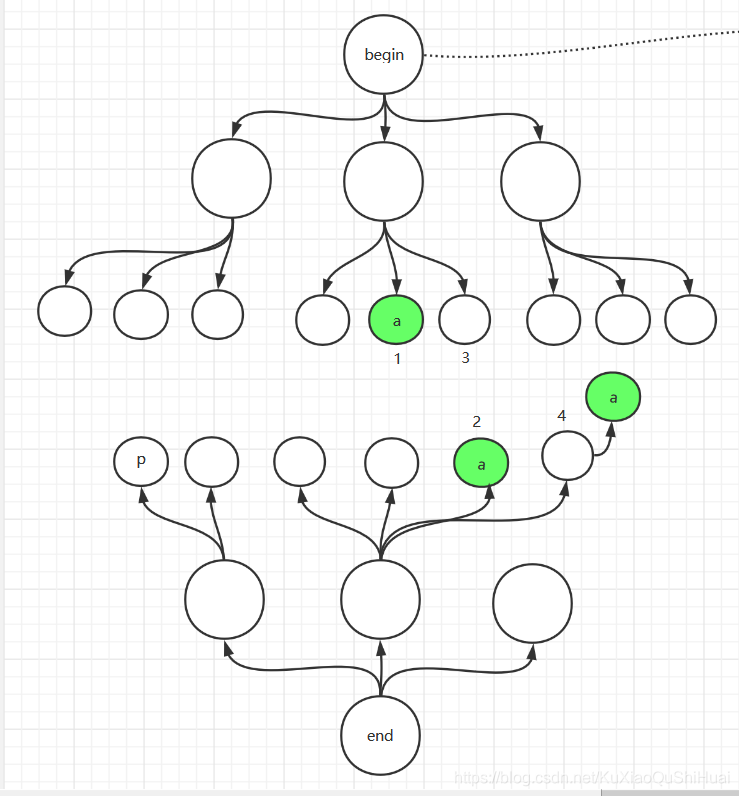
- 不要等着出队之后再放到visited节点中。例如1好节点出队,放入visited1队列中,然后2号节点出队,放入visited2中。接着3号节点,在4号节点时,发现要加入访问队列的a在visited1中包含了,这时返回的结果是3+4=7,而不是6。 也就是说在同层出现是不敏感,需要单独判断一下。














 2669
2669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









