







momentum算法:
除了batch/mini-batch/stochastic gradient descent 梯度下降法,还有一种算法叫做momentum梯度下降法,运行速度几乎总是快于标准的地图下降法,简而言之,基本的思想就是计算梯度的指数加权平均数,并利用该梯度更新权重 ,以下是batch/mini-batch gradient descent以及momentum梯度下降法走势图。
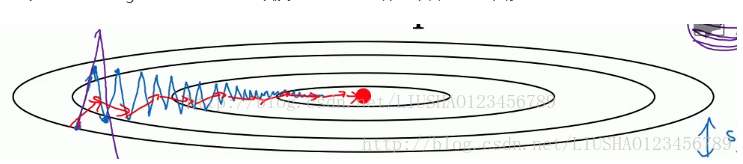
蓝线表示batch梯度下降法 ,红线是momentum梯度下降法
我们会发现梯度下降法需要很多计算步骤,慢慢摆动到最小值,这种上下波动减慢了梯度下降法的速度,导致我们无法使用更大的学习率,结果可能会偏离函数的范围,为了避免摆动过大,我们需要使用较小的学习率,另一个看待问题的角度是在纵轴上,我们希望慢一点,但是在横轴上,我们希望快一点,所以使用momentum梯度下降法,我们需要做的是,在每次迭代中,确切的说是在第t次迭代中,我么要计算微分dw,db,注意是利用现有的mini-batch计算dw,db,如果使用batch梯度下降法,则现在的mini-batch就是全部的batch,对于batch梯度下降法的效果是一样的。momentum的算法流程如下:
momentum
on iteration t:
compute dw,db on current mini-batch
V _ d w = β ∗ V _ d w + ( 1 − β ) ∗ d w {\rm{V}}\_{\rm{dw}} = {\rm{\beta*V}}\_{\rm{dw}} + \left( {1 - \beta } \right)*dw V_dw=β∗V_dw+(1−β)∗dw
V _ d b = β ∗ V _ d b + ( 1 − β ) ∗ d b {\rm{V}}\_{\rm{db}} = {\rm{\beta*V}}\_{\rm{db}} + \left( {1 - \beta } \right)*db V_db=β∗V_db+(1−β)∗db
w = w − α V d w {\rm{w}} = {\rm{w}} - {\rm{\alpha Vdw}} w=w−αVdw
b = b − α V d b {\rm{b}} = {\rm{b}} - {\rm{\alpha Vdb}} b=b−αVdb
在这里 β {\rm{\beta }} β相当于摩擦力,db,dw相当于加速度,这样就可以减缓梯度下降的幅度,如果平均这些梯度,就会发现这些纵轴上的摆动,平均值接近于零。因此用算法几次迭代之后,发现momentum梯度下降法,最终以纵轴方向摆动小了,横轴方向运动更快,因此算法走了一条更加直接的路径。
在上述算法中,有两个超参数,学习率 α {\rm{\alpha }} α以及参数 β {\rm{\beta }} β,在这里 β {\rm{\beta }} β控制着指数加权平均数, β {\rm{\beta }} β最常用的值是0.9。
RMSprop算法:
上面讲到momentum可以加快学习算法,还有一个叫做RMSprop算法,全称是(root mean square prop)算法,他也可以加速梯度下降,算法流程如下:
on iteration t:
compute dw,db on current mini-batch
S d w = β S d w + { 1 − β } d w 2 {\rm{Sdw}} = {\rm{\beta Sdw}} + \left\{ {1- \beta } \right\}d{w^2} Sdw=βSdw+{
1−β}dw2
S d b = β S d b + { 1 − β } d b 2 {\rm{Sdb}} = {\rm{\beta Sdb}} + \left\{ {1- \beta } \right\}d{b^2} Sdb=βSdb+{
1−β}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3083
3083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









