







1 并发容器的演进
工具类转换线程安全
Collections.synchronizedList(list) 内部采用同步代码块的形式,加锁保证线程安全。
public E get(int index) { synchronized (mutex) {return list.get(index);}}
Vectior和HashTable则采用的是同步方法加锁。
绝大多数情况下,ConcurrentHashMap和CopyOnWriteArrayList性能更好。CopyOnWriteArrayList适合读多写少,list一直修改的话,可以采用Collections形式。
- ConcurrentHashMap:线程安全的HashMap
- CopyOnWriteArrayList:线程安全的List
- BlockingQueue:接口,阻塞队列,非常适用于作为数据共享的通道
- ConCurrentLinkedQueue:高效的非阻塞并发队列,使用链表实现。可以视作一个线程安全的LinkedList
2 ConnrentHashMap
2.1 HashMap
为什么HashMap线程不安全?
- 线程同时put操作碰撞导致数据丢失;
- 线程同时put扩容时导致数据丢失。
- 死循环造成CPU 100%。因为在多线程并发扩容时,在resize的transer方法可能会产生环形链表,从而导致死循环。https://coolshell.cn/articles/9606.html
2.2 ConcurrentHashMap的实现原理
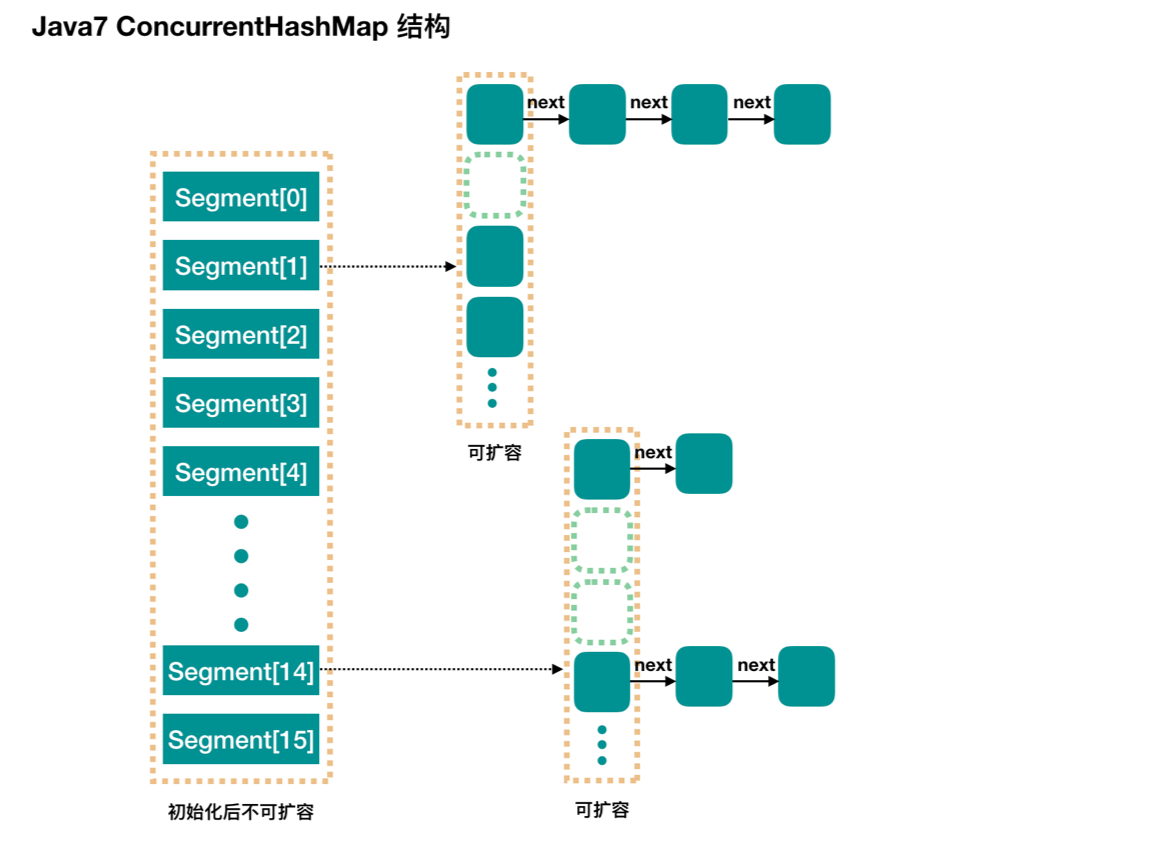
1.7版本结构,最外层设置多个segment,每个segment底层结构与HashMap类似,仍然是数组和链表组成拉链法。每个segment有独立的ReentrantLock锁,相互之间不影响,提高并发效率。默认是16个Segment,也就是说支持16个线程的并发写。segment初始化时设置,设置后不能修改。
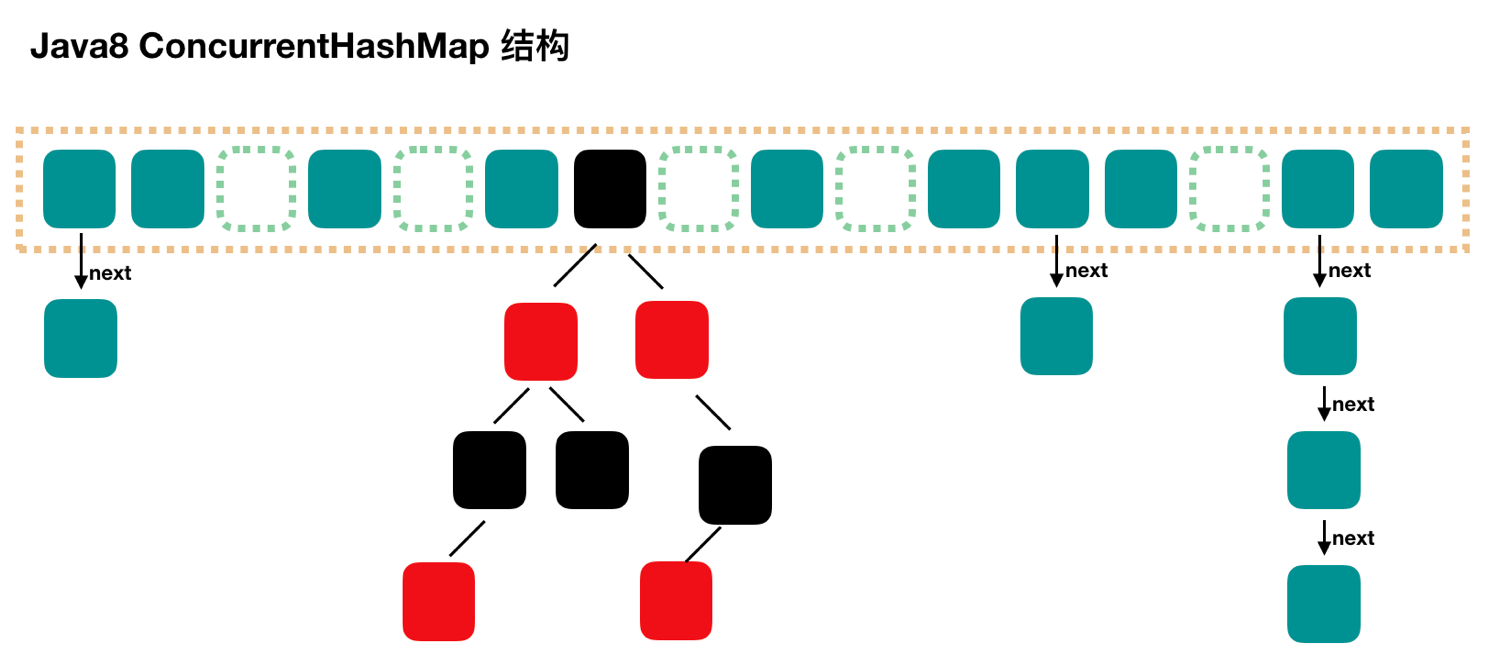
1.8版本,底层采用node+CAS+synchronized实现。结构与JDK1.8版本的HashMap类似,相对于1.7版本,锁粒度更小,每个node都有并发能力。
源码分析主要参考put/get方法实现。
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key和value不允许为空
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
// 记录链表长度
int binCount = 0;
// 循环遍历数组
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
// 数组为空,初始化数组
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 数组索引位置桶为空,CAS初始化Node
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
// 数组正在resize扩容,则帮助扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// 找到值并且相同,则直接返回
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else { // 采用synchronized内置锁写入数据
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
区别:
- 数据结构:主要体现在并发度
- Hash碰撞:1.7采用拉链法,1.8采用了HashMap的红黑树转换的形式。
- 并发工具:1.7采用ReentrantLock,1.8采用synchronized和CAS。
2.3 使用时需要注意的问题
使用ConcurrentHashMap只能保证对于map的put、get操作是线程安全的,而组合操作不能保证线程安全,例如a++。
public class OptionsNotSafe implements Runnable {
/**
* map容器
*/
private static ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
public static void main(String[] args) throws InterruptedException {
map.put("sum", 0);
Thread thread1 = new Thread(new OptionsNotSafe());
Thread thread2 = new Thread(new OptionsNotSafe());
thread1.start();
thread2.start();
}
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
Integer old = map.get("sum");
map.put("sum", old + 1);
}
}
}
可以通过synchronized同步代码块解决,但是会破坏ConcurrentHashMap思想。
public void run() {
for (int i = 0; i < 10000; i++) {
while (true){
Integer old = map.get("sum");
Integer newVal = old + 1;
if (map.replace("sum", old, newVal)) {
break;
}
}
}
}
replace采用的是自旋的思想,更新成功才返回true。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









