






论文题目:CLIP-AE: A Multi-Modal Unsupervised Images Enhancement Method Based on High-Order Adaptive Curve for Visual Disbalance Defects(基于高阶自适应曲线的视觉失衡缺陷多模态无监督图像增强方法CLIP-AE)
期刊:IEEE TRANSACTIONS ON MULTIMEDIA(计算机科学 Top)
摘要:对于低光图像中的视觉不平衡缺陷(VDDs),如亮度不均匀和色彩不平衡,现有的增强方法难以从局部区域提取缺陷特征,并根据这些缺陷的不同程度进行自适应增强。为了解决这些挑战,我们提出了一种基于高阶自适应曲线的无监督多模态增强方法,命名为CLIP-AE。具体来说,我们引入了一种利用对比语言图像预训练(CLIP)的多模态循环优化方法。该方法迭代优化变量嵌入提示和自适应增强模块(AEM),建立提示与图像中详细风格特征之间的依赖关系,引导AEM进行自适应图像增强。此外,我们实现了渐进式特征对齐策略,通过使用具有相同内容特征和增量样式特征的多个增强图像来增强模型感知样式特征的能力,提高优化效率。在AEM中,优化的超参数生成网络(HGN)生成最优超参数,驱动高维nestedgamma校正(HDN-Gamma)对vdd进行逐像素自适应增强。HDN-Gamma使用特定的增强曲线进一步映射像素值,以避免伪影。大量实验表明,该方法有效地改善了视觉不平衡缺陷,减少了伪影。与7种最先进的算法相比,我们的方法显示出显著的改进(PSNR: 16.46%, 16.89%和15.14%;SSIM: 9.26%, 8.02%, 9.85%;在LOL、SICE和MIT-Adobe FiveK数据集上,MUSIQ分别为6.37%、6.54%和7.45%)。该方法为将多媒体技术应用于弱光图像增强任务提供了一种新颖的解决方案。
CLIP-AE:基于多模态学习的低光图像增强新范式
引言
在智能手机摄影日益普及的今天,低光环境下的图像质量问题困扰着无数用户。无论是夜景拍摄、室内暗光还是逆光场景,拍出的照片往往存在亮度不足、颜色失真等问题。本文将深入解读一篇发表在IEEE顶级多媒体期刊上的最新研究——CLIP-AE,看看研究者们如何巧妙地将多模态学习技术应用于低光图像增强任务。
一、问题背景:什么是视觉失衡缺陷?

1.1 VDDs的定义与表现
论文首次系统性地提出了视觉失衡缺陷(Visual Disbalance Defects, VDDs)的概念。与简单的"整体过暗"不同,VDDs强调的是图像中局部区域的不均匀缺陷:
┌─────────────────────────────────────────────┐
│ 视觉失衡缺陷的两大表现 │
├─────────────────────────────────────────────┤
│ 🔦 亮度不均匀: │
│ • 同一图像中存在过亮和过暗区域 │
│ • 不同区域的亮度缺陷程度各异 │
│ • 亮暗区域之间没有清晰边界,呈渐变过渡 │
├─────────────────────────────────────────────┤
│ 🎨 颜色失衡: │
│ • 色彩分布不均匀 │
│ • 局部区域出现色偏 │
│ • 整体色调偏移 │
└─────────────────────────────────────────────┘
1.2 为什么VDDs难以处理?
论文指出了VDDs增强任务面临的两大核心挑战:
挑战一:自适应增强的复杂性
传统方法通常采用"一刀切"的全局增强策略,对整张图像应用相同的增强强度。但VDDs要求针对不同区域的不同缺陷程度进行差异化处理。例如:
- 阴影区域需要大幅提亮
- 正常曝光区域需要轻微调整
- 高光区域可能需要适度压暗
挑战二:缺乏明确的学习标签
由于不同类型的VDDs缺乏清晰的参考标准,增强方法难以学习正确的特征映射关系,导致感知性能受限。
1.3 现有方法的局限性
论文系统分析了现有方法的三大不足:
| 方法类别 | 代表方法 | 主要问题 |
|---|---|---|
| 多曝光融合 | EEMEFN | 融合策略无法精确消除不同程度的缺陷 |
| 语义先验引导 | SKF | 对细节亮度特征的捕捉仍不准确 |
| 无监督GAN | EnlightenGAN | 易产生伪影,像素映射不准确 |
| 基于曲线的方法 | ZeroDCE | 曲线映射范围受限 |
特别值得关注的是ZeroDCE方法。它提出了一个优雅的增强曲线:
![]()
然而,论文通过可视化分析发现,这个曲线的映射范围有限——当输入灰度值较低时(如x=0.1),无论如何调整参数α,输出值都无法映射到足够高的动态范围,限制了对暗区的有效增强。
二、方法详解:CLIP-AE的技术架构
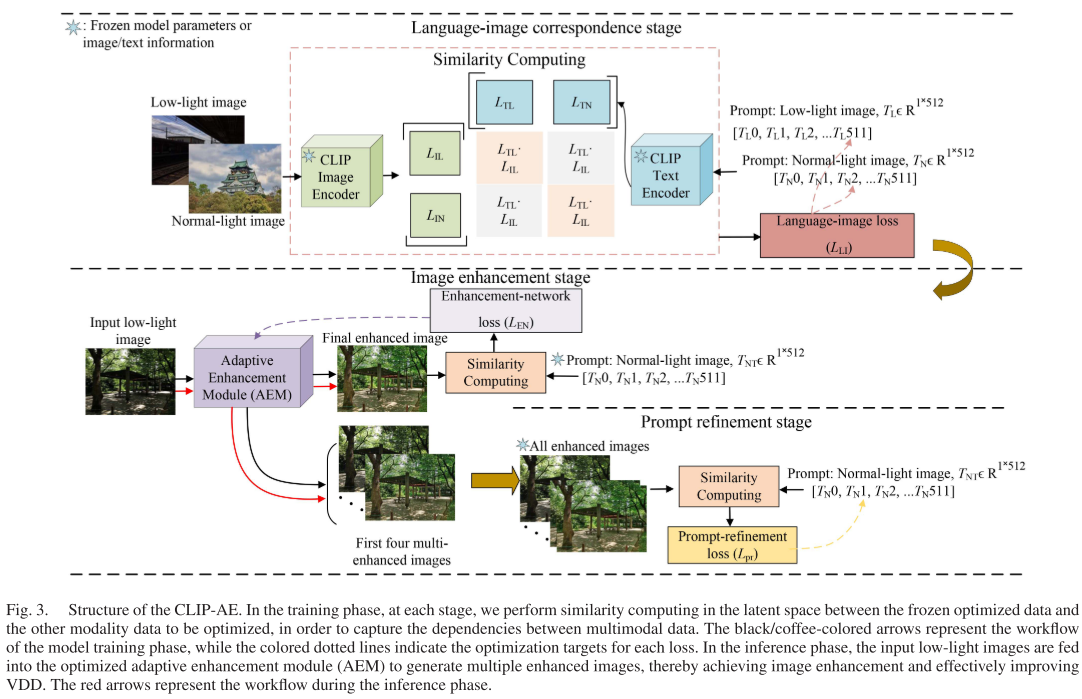
CLIP-AE的核心思想是:利用多模态学习建立文本提示与图像风格特征的对应关系,指导自适应增强模块针对不同区域的VDDs进行精准增强。
2.1 整体框架
CLIP-AE包含三个核心组件:
┌────────────────────────────────────────────────────────────┐
│ CLIP-AE 整体架构 │
├────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 语言-图像 │ → │ 图像增强 │ → │ 提示精炼 │ │
│ │ 对应阶段 │ │ 阶段 │ │ 阶段 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ ↑ │ │
│ └────────────── 循环优化 ←───────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ 自适应增强模块 (AEM) │ │
│ │ ┌─────────────┐ ┌─────────────────────────┐ │ │
│ │ │ HGN │ ──────→ │ HDN-Gamma │ │ │
│ │ │ 超参数生成网络 │ │ 高维嵌套Gamma校正 │ │ │
│ │ └─────────────┘ └─────────────────────────┘ │ │
│ └──────────────────────────────────────────────────────┘ │
└────────────────────────────────────────────────────────────┘
2.2 多模态循环优化方法
这是CLIP-AE的第一个核心创新。传统的CLIP应用于图像分类,建立的是"文本描述-物体类别"的对应关系。但在低光增强任务中,我们需要建立的是"嵌入提示-风格特征"的对应关系。
阶段一:语言-图像对应
# 伪代码示意
L_IL = CLIP_Image_Encoder(I_L) # 低光图像的latent token
L_IN = CLIP_Image_Encoder(I_N) # 正常光图像的latent token
L_TL = CLIP_Text_Encoder(T_L) # "低光"提示的latent token
L_TN = CLIP_Text_Encoder(T_N) # "正常光"提示的latent token
# 通过对比学习损失建立对应关系
L_LI = ContrastiveLoss(L_IL, L_IN, L_TL, L_TN)
这里的关键设计是:使用随机嵌入提示替代传统文本提示。为什么?因为:
- 用文字准确描述图像的风格特征很困难
- 不同的文字描述可能导致模型学习不一致
- 手动创建"文本-图像"配对费时费力
阶段二:图像增强
利用优化后的提示T_NT指导自适应增强模块(AEM)的优化:
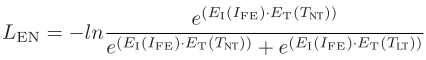
阶段三:提示精炼——渐进式特征对齐
这是一个精妙的设计!论文利用AEM生成的多个中间增强图像(I_E0, I_E1, I_E2, I_E3, I_FE)来进一步优化提示。
输入图像 → I_E0 → I_E1 → I_E2 → I_E3 → I_FE(最终增强)
│ │ │ │ │
└──────┴──────┴──────┴──────┘
增量式风格特征
相同的内容特征
这些图像具有:
- 相同的内容信息(都是同一张图片)
- 递增的风格特征(亮度逐步增加)
通过Margin Ranking Loss,确保提示T_NT:
- 更关注风格特征而非内容信息
- 与正常光图像的相似度高于低光图像
效率提升:传统方法需要~20K epochs收敛,CLIP-AE只需8.48K epochs!
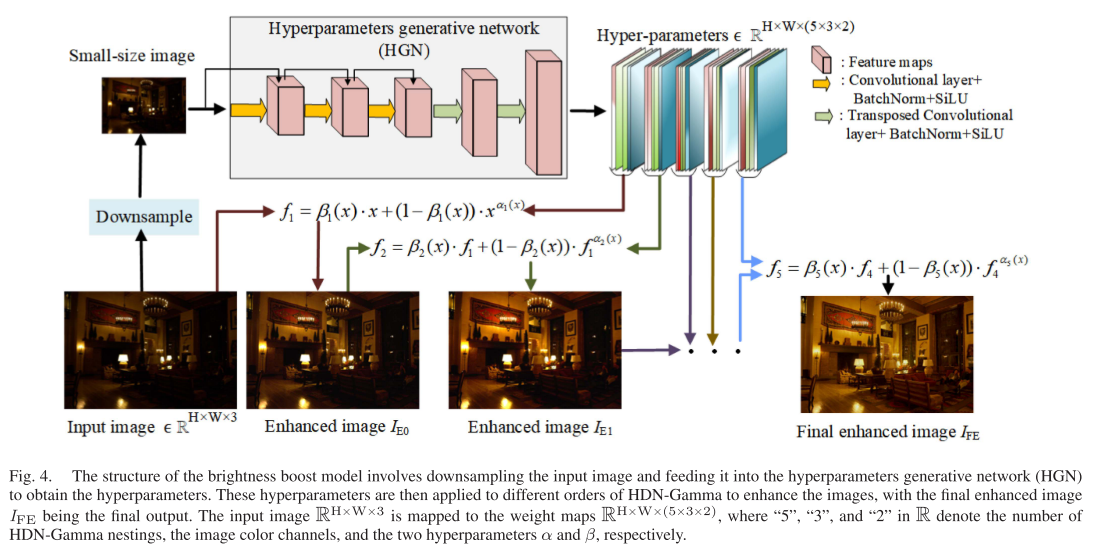
2.3 高维嵌套Gamma校正(HDN-Gamma)
这是CLIP-AE的第二个核心创新,旨在解决ZeroDCE曲线映射范围受限的问题。
基本公式
![]()
这是一个幂函数与线性函数的平滑融合:
- α:控制幂函数的曲率
- β:动态控制两种函数的融合权重
参数作用分析
| 参数范围 | 效果 |
|---|---|
| α ∈ (0,1), β→0 | 大幅提升低灰度值,适合严重低光图像 |
| α < 1, β→1 | 轻微增强,适合非极端低光图像 |
| α > 1, β→0 | 压制高灰度值,适合改善过曝区域 |
函数嵌套策略
为了提升非线性拟合能力,论文采用递归嵌套:
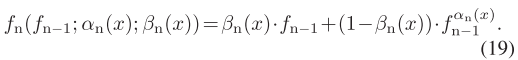
实验表明,5阶嵌套是最优选择——更高阶会导致曲线呈直角状,失去增强效果。
像素级自适应增强
最后,HDN-Gamma采用像素级增强策略:为每个像素生成独立的(α, β)参数对,实现真正的自适应增强。
输入图像 R^(H×W×3) → HGN → 权重图 R^(H×W×30)
│
└→ 5阶嵌套 × 3通道 × 2参数
2.4 为什么HDN-Gamma能避免伪影?
无监督学习的一个常见问题是产生伪影。HDN-Gamma通过约束映射范围来解决:
- 值域恒定:当输入为0或1时,输出保持不变
- 单调递增:避免将亮区变暗
- 可微分:满足神经网络反向传播要求
- 范围约束:输出始终在[0,1]范围内
三、实验验证
3.1 实验设置
- 数据集:LOL、SICE、MIT-Adobe FiveK
- 对比方法:7种SOTA算法(IAT、URetinex-Net、RetinexNet、ZeroDCE、EnlightenGAN、SCI、CLIP-LIT)
- 评估指标:PSNR、SSIM、MUSIQ
3.2 定量结果
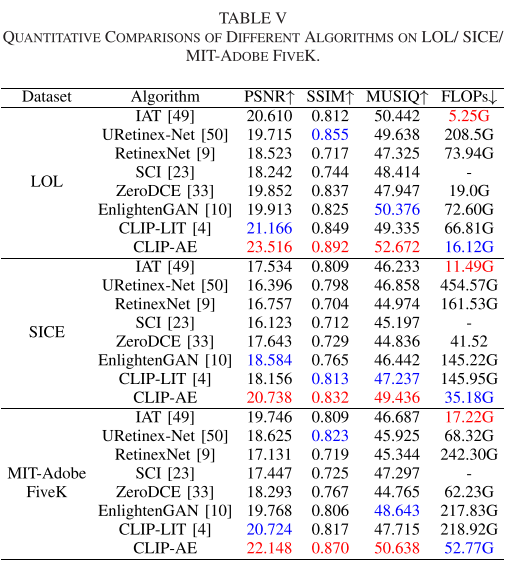
| 数据集 | 指标 | CLIP-AE | vs CLIP-LIT | vs ZeroDCE |
|---|---|---|---|---|
| LOL | PSNR | 最优 | +10.73% | +19.02% |
| LOL | SSIM | 最优 | +4.63% | +11.38% |
| LOL | MUSIQ | 最优 | +5.84% | +11.07% |
| SICE | PSNR | 最优 | 显著提升 | 显著提升 |
| MIT-Adobe FiveK | PSNR | 最优 | 显著提升 | 显著提升 |
综合提升:
- PSNR: 16.46%, 16.89%, 15.14%
- SSIM: 9.26%, 8.02%, 9.85%
- MUSIQ: 6.37%, 6.54%, 7.45%
3.3 计算效率
| 方法 | 相对计算复杂度 |
|---|---|
| CLIP-LIT | 100% (基准) |
| CLIP-AE | 24.13% (降低75.87%) |
| ZeroDCE | 高于CLIP-AE 15.16% |
3.4 消融实验亮点
优化方法的有效性:
- 相比原始CLIP优化方法,提出的循环优化方法在所有IQA指标上都有提升
- 训练收敛速度提升约2.4倍
HDN-Gamma vs ZeroDCE:
- 4阶HDN-Gamma的映射能力≈8阶ZeroDCE
- 2阶HDN-Gamma即可满足标准增强需求
- 显著降低计算复杂度
3.5 视觉效果对比

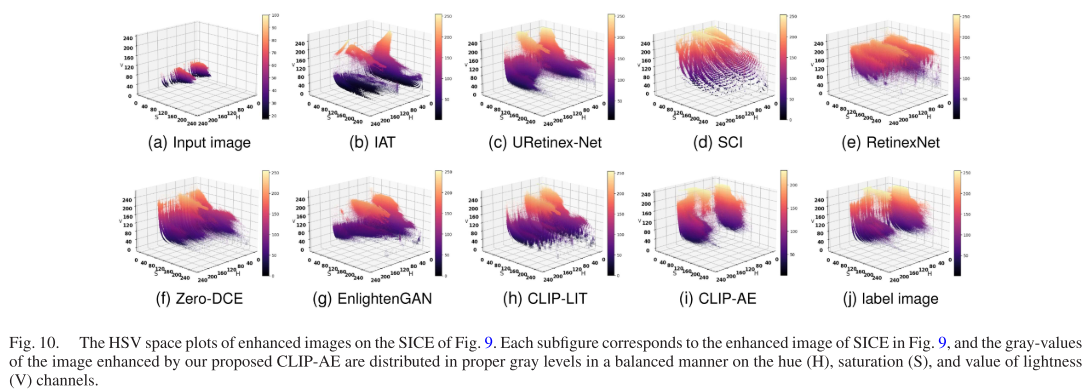
论文展示了多个典型场景的增强效果:
逆光人像场景:

- IAT、SCI:人脸可见但背景严重过曝
- EnlightenGAN、CLIP-LIT:避免过曝但人脸增强不足
- CLIP-AE:人脸清晰、背景不过曝
全局低光场景:

- URetinex-Net、SCI、EnlightenGAN:对比度低
- RetinexNet、EnlightenGAN:色彩失真
- CLIP-AE:整体亮度提升、阴影细节恢复
高分辨率细节保留:
- ZeroDCE、EnlightenGAN:产生虚假细节
- IAT:严重色彩失真
- CLIP-AE:保持内容完整、有效增强
四、方法局限性与未来方向
论文诚实地指出了一些局限:
- 训练效率:虽然比传统CLIP方法效率更高,但仍需大量训练迭代
- 局部细节增强:在某些场景下,局部细节区域的亮度增强效果不如全局方法明显
- 曲线映射的权衡:为避免伪影而设计的约束范围,可能在某些情况下限制了亮度提升幅度
未来研究方向:
- 进一步提升多模态对比学习的效率
- 在自适应亮度增强和伪影预防之间寻找更好的平衡点
五、总结
CLIP-AE是一项将多模态学习成功应用于低光图像增强的创新工作,其核心贡献包括:
✅ 理论创新:首次系统定义VDDs问题,提出针对性解决方案
✅ 方法创新:
- 多模态循环优化方法
- 渐进式特征对齐策略
- 高维嵌套Gamma校正
✅ 实践价值:
- 显著优于现有SOTA方法
- 计算效率大幅提升
- 有效避免颜色失真和伪影
这项工作为多媒体技术在低光图像增强领域的应用提供了新思路,也为后续研究奠定了坚实基础。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









