







一、使用场景
考虑一个场景,有一个redis集群,那么我们如何分配不同的要缓存的数据,使之能够尽可能均匀的存储到各个redis服务器上呢?肯定有人会想到使用传统的hash + 取模 算法。
服务器ID = hash(object) % N (N为服务器个数)
举个例子,如果我们有4个redis服务器,编号分别为0,1,2和3,产生的十个数据的hash值分别为1~10。列出具体的数据分布情况。
0号服务器:4、8
1号服务器:1、5、9
2号服务器:2、6、10
3号服务器:3、7、11
首先我们不管分布的是否均匀,我假设一种情况,如果多加一个节点,即4号服务器,那么这些数据是要重新分布的,重新分布的结果我们来看一下。
0号服务器:5、10
1号服务器:1、6
2号服务器:2、7
3号服务器:3、8
4号服务器:4、9可以看到,除了1、2、3这三个数据,其他数据的缓存位置都发生了变化,这样会导致很严重的性能问题。
这时候我们的一致性哈希算法就出场了。该算法的目的是在移除/新增一个节点时,尽可能减少“缓存数据key”到服务器映射的改变。
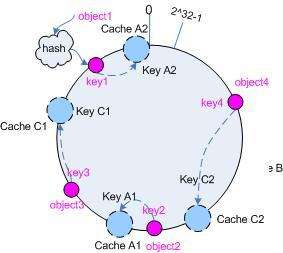
(1)首先要构造一个环形hash值区域,一般值区域为0~2^32-1。
(2)对key的值求hash值,h1 = hash(key),将该值放入环形hash区域的某个桶中。
(3)对每个redis服务器的编号值(可以是IP,也可以是其他某个标识符)求hash值,h2 = hash(node),将该值放入环形hash区域的某个桶中。
(4)每个缓存数据都缓存在它前方(hash环顺时针方向的前方)的redis服务器中。
(图片来自网络)
这样就完美解决了之前因为新增/移除节点而导致的数据缓存位置大幅度移动的情况,因为每个节点所在的hash桶的位置都是固定不变的,而且每个数据所在的hash桶位置也是不变的。因此如果在两个节点如图中的A1和C2之间再插入一个节点X,则若是X插入的位置在key2的位置的前面(A1与key2)之间,则整个图只需要移动key2的缓存位置,让object2缓存到X就行,如果X节点的插入位置在key2 和C2之间,则不需要移动任何缓存数据。
但是这样还是有缺陷的,可能会存在hash分布不均匀的情况,那就需要虚拟节点,因为在hash环上,节点越多,分布的会更均匀。
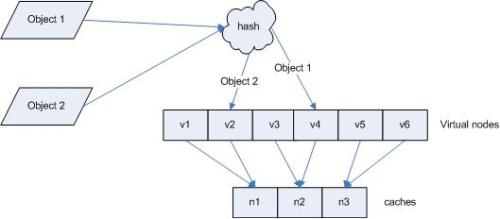
(图片来自网络)
在图中有v1~v6若干个节点,缓存数据都会分布在这几个节点上,但这都是虚拟的,缓存数据实际存储的位置时n1~n3,这样会使得缓存分布更加均匀。














 8828
8828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









