







一、前言
本章我们关注on-policy control 问题,这里采用参数化方法逼近action-value函数 q̂ (s,a,w)≈q(s,a) q ^ ( s , a , w ) ≈ q ( s , a ) ,其中, w w 为权重向量。在11章中会讨论off-policy方法。本章介绍了semi-gradient Sarsa算法,是对上一章中介绍的semi-gradient TD(0)的一种扩展,将其用于逼近action value, 并用于 on-policy control。在episodic 任务中,这种扩展是十分直观的,但对于连续问题来说,我们需要考虑如何将discount (折扣系数)用于定义optimal policy。值得注意的是,在对连续任务进行函数逼近时,我们必须放弃discount ,而改用一个新的形式 ” average reward”和一个“differential” value function进行表示。
首先,针对episodic任务,我们将上一章用于state value 的函数逼近思想扩展到action value上,然后我们将这些思想扩展到 on-policy GPI过程中,用 ϵ ϵ -greedy来选择action,最后针对连续任务,对包含differential value的average-reward运用上述思想。
二、Episode Semi-gradient Control
将第9章中的semi-gradient prediction 方法扩展到control问题中。这里,approximate action-value q̂ ≈qπ q ^ ≈ q π ,是权重向量 w w 的函数。在第9章中逼近state-value时,所采用的训练样例为 St↦Ut S t ↦ U t ,本章中所采用的训练样例为 St,At↦Ut S t , A t ↦ U t ,update target Ut U t 可以是 qπ(St,At) q π ( S t , A t ) 的任何逼近,无论是由MC还是n-step Sarsa获得。对action-value prediction 的梯度下降如下:
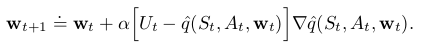
对one-step Sarsa而言,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1138
1138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









