







[算法系列] 递归应用: 快速排序+归并排序算法, 核心思想与拓展 … 附赠 堆排序算法
写完发现本文过于杂乱, 列个纲要叭:
- 本文是递归系列的第二篇, 在上篇文章 搞懂递归, 看这篇就够了 !! 递归设计思路 + 经典例题层层递进 介绍递归后, 本文将举熟悉的快速排序和归并排序算法小小地介绍分治的思想.
- 将对快排的划分partition算法和归排的合并merge算法进行介绍并适当扩展
- 将介绍递归和树的关系, 顺带介绍堆排序算法
分治: 将原问题划分成若干个规模较小而原问题一致的子问题; 递归地解决这些子问题, 然后再合并其结果, 就得到原问题的解
分治模式在每一层递归上都有三个步骤:
- 分解devide : 将原问题分解(划分)成一系列的子问题
- 解决conquer: 递归地解决各子问题, 若子问题足够小, 则直接有解
- 合并combine:将子问题合并成原问题的解
分治的关键点
- 原问题可以一直分解为形式相同的子问题, 当子问题规模较小时,就可以自然求解, 比如一个元素自然有序
- 子问题可以通过合并得到原问题的解
- 子问题的分解以及解的合并一定是比较简单的, 额外开销不可能太多, 否则分解和合并的时间可能超过暴力解法, 得不偿失
回顾+引子
我们先回顾上篇文章搞懂递归, 看这篇就够了 !! 递归设计思路 + 经典例题层层递进中的把插入排序修改为递归形式的例子:
# 插入排序的递归形式
def insert_sort(arr , k):
if k == 0 :
return ;
#对前n -1 个元素排序
insert_sort(arr, k -1)
# 把位置k的元素插入到前面的部分
x = arr[k]
index = k -1
while index > -1 and x <arr[index] :
arr[index + 1] = arr[index]
index -= 1
arr[index+1] = x
我们将索引k作为变化参数进行递归, 相当于我们每次分解为 数组长度减1 的子问题进行求解, 所以k 初始为最后一个元素的下标, 然后逐次减少 , 直到k = 0. 再看上述代码, 实际的插入过程是在递归调用后进行的, 由上篇文章中提到的在归回来时产生的副作用, 这就相当于一来 k就一直减减,减到0, 然后层层归来, 逐层返回, 再进行下面插入操作. 因此实际的执行顺序和循环版插排是一样的, 这也体现了递归和循环的统一.
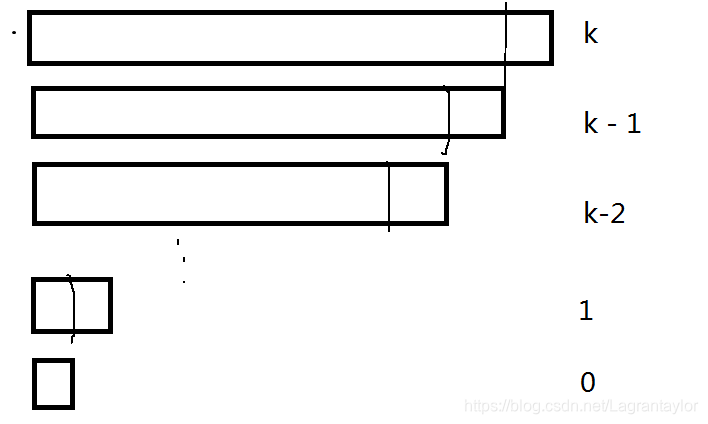
结合上面的图, 我们可以看出, 每一层递归中只有一次划分, 每次划分只划了一个元素(k到k -1) 得到子问题. 在不断归回来的时, 保证前k-1是排好序的, 第k个按照同样方法插到某一位置使得前k个有序, 这就是我们的合并 .
哦… 原来插排一次只划了最后一个走, 那我们为什么不从中间划, 一次划个一半呢?

我们来考虑它的子问题, k-1个有序是k个有序的子问题, 那么从中间划分是不是可以把左右分别有序作为整体有序的子问题呢? (太聪明了, 这就是归并算法), 那我们再想想, 左右两边有序使得整体有序…这个过程稍显繁琐(合并费劲)…
那能不能我们从中间某个位置划一刀, 使得比这个位置上大的元素全放在右边, 小的全放在左边呢? 当然可以, 而且这就是没有合并的事了(划分费劲). 当然, 此划出来的位置上的元素, 一定也在他最终的位置了
快速排序算法
- 分解: 数组arr[p…r] 被划分成两个子数组arr[p…q - 1] 和 arr[p+1 … r], 使得arr[q]为大小居中的数, 左侧arr[p…q - 1]每个元素都小于它, 右侧 arr[p…q - 1] 每个元素都大于等于它. 其中计算下标q也是划分的一部分.
- 解决: 通过递归调用快速排序对两个子数组arr[p…q - 1] 和 arr[p+1 … r] 分别进行排序
- 合并: 因为子数组都是原址排序的,所以每一轮的arr[q]总是有序的, 不需要合并.
伪代码如下:
QuickSort(arr,p,r)
if p < r
q = partition(arr, p, r)
QuickSort(arr,p,q-1)
QuickSort(arr,q+1,r)
问题的关键就在于得到这个划分位置的parition函数. 但是以哪一个元素来划分呢? 我们规定以每次数组的第一个元素(主元pivot)来进行划分.
pariition函数思路
双向扫描法, 头尾指针往中间扫, 从左侧找到大于主元的元素, 从右侧找到小于等于主元的元素二者交换, 继续扫描, 直到左侧无大元素, 右侧无小元素.
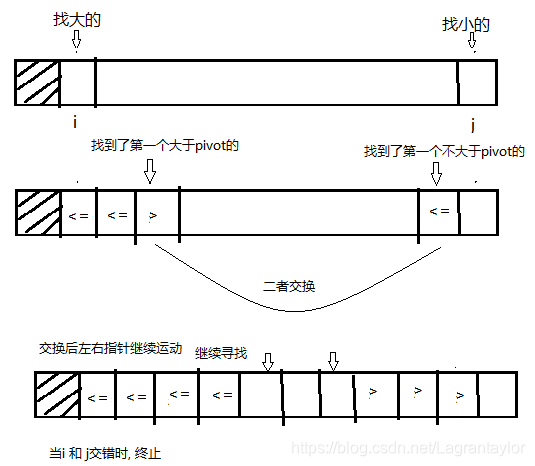
def quick_sort(arr,p,r):
if p < r:
q = partition(arr, p, r)
quick_sort(arr,p, q-1)
quick_sort(arr,q+1 ,r)
def partition(arr, p, r):
pivot = arr[p]
left = p + 1
right = r
while left <= right:
# left 不断往右走, 直到遇到大于主元的元素
while left <= right and arr[left] <= pivot:
left += 1 # 循环退出时, left一定是指向第一个大于主元的位置
while left <= right and arr[right] > pivot:
right -= 1 # 循环退出时, right 一定是指向第一个小于等于主元的位置
if left < right:
swap(arr, left, right)
swap(arr, p, right)
# while 退出时,两者交错,right指向的是最后一个小于等于主元的位置,也就是主元应该待的位置
swap(arr, p ,right)
return right
def swap(arr , i , j):
temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
思考, 我们在选pivot时是直接选最左边arr[p]作为pivot的, 那么能不能进行有一些优化呢? p, p和r中间的那个值, 以及q 选一个中间的作为pivot
归并排序算法
前面已经谈到归并排序的相关特点, 下面来详细看看:
- 分解: 将n 个元素分成含 n/ 2 个元素的子序列
- 解决: 对两个子序列递归地进行排序
- 合并: 合并两个已排序的子序列得到排序结果
和快排不同的是: 分解容易合并麻烦
代码如下:
def merge_sort(arr , low , high):
if low < high:
middle = low + int( (high - low) / 2 )
merge_sort(arr , low , middle) #对左侧排序
merge_sort(arr , middle + 1 , high) #对右侧排序
merge(arr , low , middle , high) #合并
关键在于合并函数merge 的实现
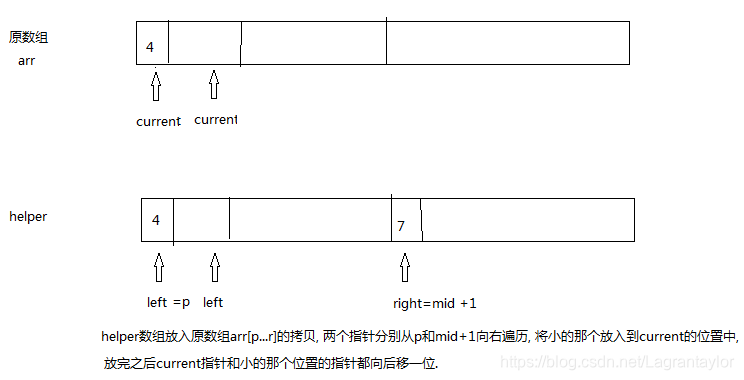
# 归并排序算法
def merge_sort(arr , low , high):
if low < high:
middle = low + int( (high - low) / 2 )
merge_sort(arr , low , middle) #对左侧排序
merge_sort(arr , middle + 1 , high) #对右侧排序
merge(arr , low , middle , high) #合并
helper = [0] * len(arr)
def merge(arr,p , mid ,r):
# 先把arr中的数据拷贝到helper中
copy(arr,p , helper , p , r-p +1)
left = p #左侧队伍的头部指针, 指向待比较的元素
right = mid + 1 #右侧队伍的头部元素, 指向待比较的元素
current = p # 元素组的指针, 指向待填入数据的位置
while left <= mid and right <= r:
if helper[left] < helper[right]:
arr[current] = helper[left]
current += 1
left += 1
else:
arr[current] = helper[right]
current += 1
right += 1
#有一边有剩余
if left <= mid:
while left <= mid:
arr[current] = helper[left]
current += 1
left += 1
def copy(arr,p , helper , q , len):
while len > 0:
helper[q] = arr[p]
q += 1
p += 1
len -= 1
针对快排的[partition和归排的merge, 下面是一些拓展
调整数组顺序使所有奇数位于偶数前面
输入一个整数数组, 调整数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数都位于后半部分. 要求时间复杂度为O(n)
思路1: 使用归并算法的合并思想. 用一个和原数组arr相同的helper数组, 用一个指针current遍历helper. 原数组arr 用p,r收尾两个指针遍历, 当current指向奇数时存入arr[p],p后移; 当current指向偶数时存入arr[r],r前移. 该方法时间复杂度O(n), 空间复杂度也是O(n)
# merge 思想
def put_even_forward(arr):
helper = [0] * len(arr)
copy(arr , 0 , helper , 0 , len(arr))
current = 0
p = 0
r = len(arr) - 1
while(current < len(arr)):
if helper[current] % 2:
arr[p] = helper[current]
p +=1
current += 1
else:
arr[r] = helper[current]
r -= 1
current += 1
思路2: 使用快排的划分思想, 空间复杂度降为O(1). 指针p,r 分别指向arr的开头和末尾, 当两指针不重合时分别向中间遍历. 遍历途中, 如果:
- arr[p]: 奇数, ==> p 一直增大遇到的第一个偶数为止
- arr[p]: 偶数, arr[r]: 偶数 ==> r 一直减到遇到的第一个奇数, 然后交换, p++
- arr[p] : 偶数, arr[r] : 奇数 ==> 交换, p ++, r –
# 快排思路
def put_even_forward_qk(arr):
p = 0
r = len(arr) - 1
while p < r:
while arr[p] % 2 : # 找到了arr[p]为偶数
p += 1
while arr[r] % 2 == 0: # 找到了arr[r]为奇
r -= 1
swap(arr, p ,r) #现在进行交换
p += 1
r -= 1
def swap(arr , i , j):
temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
第 k 个的元素
用尽量高的效率求出一个乱序数组中按值顺序排的第k个元素值. 比如arr= [3,1,4,8,7,5,9], 当k = 3 时返回4.
显然可以先通过快排将arr 变得有序,再取arr[k - 1]即可, 此时时间复杂度为 O(nlogn), 那么有更高效的算法吗?
回顾快排的partition函数部分, 每一次partition后, 将把pivot放到他排好序的位置上. 比如这个排好序的位置是q , 我们可以讨论k 与 q 的大小关系, 如果k < q , 则说明k 在q的左边, 接着在p 和 q 之间进行partition … 就像二分查找一样, 找到k的位置.
def select_k (arr, p , r,k):
q = departion(arr , p , r)
if q == k - 1: # 我们所说的第k个, 实际上是在排好序后的数组的arr[k-1], 所以比较时得减1
return arr[q]
elif q > k :
return select_k(arr , p , q - 1 , k)
else :
return select_k(arr , q +1 , r , k - q) #注意这里 k-q, 在整体的第k个实际是在右边的第k-q个
#和快排的一样
def departion(arr, p, r):
pivot = arr[p]
left = p + 1
right = r
while left <= right:
# left 不断往右走, 直到遇到大于主元的元素
while left <= right and arr[left] <= pivot:
left += 1 # 循环退出时, left一定是指向第一个大于主元的位置
while left <= right and arr[right] > pivot:
right -= 1 # 循环退出时, right 一定是指向第一个小于等于主元的位置
if left < right:
swap(arr, left, right)
# while 退出时,两者交错,right指向的是最后一个小于等于主元的位置,也就是主元应该待的位置
swap(arr, p ,right)
return right
超过一半的数字
找出一个无序数组中,出现次数超过一半的那个元素值. 比如 arr1 = [2,3,6,3,3,3,4,3,3,2,2,2,3,2,3] ,则返回3.
[法1] 将整个数组排序后, 取中间的那个数字 O(nlogn)
[法2] 还是使用快排的departion函数进行分割,找到排序后中间位置上的数字 O(n).相当于直接调用
select_k(arr , 0 , len(arr) - 1, int(len(arr) / 2) )
[法3] 使用hashmap…也就是python中的字典.
def find_more_half_hash(arr):
map = dict()
for e in arr:
if e in map:
map[e] += 1
else:
map[e] = 1
res = 0
for key in map.keys():
if map[key] * 2 > len(arr):
res = key
break
return res
合并有序数组
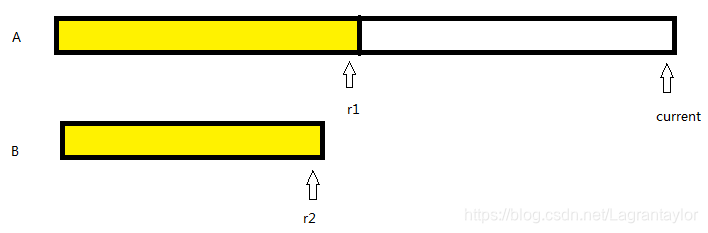
给定两个排序后的数组 A 和 B , 其中A的末端有足够的缓冲空间容纳B, 写一个方法,将B合并入A并且整体有序.
[解]使用归并排序中的merge方法的思想. 使用三个指针 ; r1, r2 分别指向A的末尾和B有元素的末尾, current指向A的最后. 然后 逐个逐个地向前放入A和B中大的那一个, 和归并的merge方法不同之处在于是从后往前合并.
逆序对个数:
一个数列中顺序取两个数, 如果左边的数大, 右边的数小,则称这两个数为一个逆序对. 求出一个数列中有多少个逆序对?
这个题看似和快排归并没啥关系, 其实不然. 考虑归并中的merge方法, 在合并时, 我们是分了左边小和右边小的, else时是右边小于左边, 将右边的放入元素组, 而每次比较右边小于左边时, 不正好是一个逆序对么?
故其实只需要在merge中进行改进即可
while left <= mid and right <= r:
if helper[left] < helper[right]:
arr[current] = helper[left]
current += 1
left += 1
else:
arr[current] = helper[right]
current += 1
right += 1
num_nixu += mid - left + 1 # num_nixu 记录逆序的个数, 当右边更小时, 逆序个数增加左边子数组个数
本文内容包括两个部分,
- 结合上一篇文章讲的递归 ,进而引出分治算法相关概念. 引出并讨论了两个常见的使用递归分治的快排和归排算法.
- 针对快排的划分函数partition和归并排序的合并函数merge的核心思想, 介绍了一些更多的应用, 可加深如多指针遍历, 合并思想的印象.
下面一部分介绍递归和树之间一些基础东西, 顺带把堆排序也介绍了
递归与树
如下有一颗二叉树, 我们尝试用顺序表(数组)去存储. 按照圆圈里的数字的顺序, 并作为下标
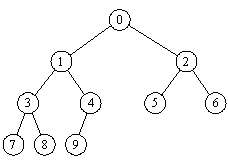
这很简单.

观察发现, 在数组中给定任意一个下标为 i 的元素, 其左右孩子和父亲(如果有的话)的下标有如下关系:
父亲: arr[(i-1)/2]
/
元素: arr[i]
/ \
左孩子: arr[2 * i + 1] 右孩子: arr[2 *i + 2]
比如i = 2时,孩子为5,6 父亲为 (2-1)/2 = 0.
树的三种遍历方式
前序遍历.
对每个结点i, 在访问其左右孩子之前, 先访问自身i, 再访问左孩子, 最后访问右孩子. 显然递归思想可以解决这样问题. 回顾 . 对于每一次访问, 做三件事情:
- 访问自己结点位置上的元素
- 访问左孩子
- 访问右孩子
找重复: 对于每个结点, 均有上述三个操作
找变化: 下标i在每一次访问都不同, 取决于前面谈到的下标间关系, 可将下标作为递归函数的参数.
找出口: 当 下标 i 超过数组长度时, 说明访问到底, 此时需要返回.
def pre_order(arr, i):
if i >= len(arr):
return
print(arr[i], end=" ") # 这里的访问方式为打印处元素的值
pre_order(arr , 2 * i + 1)
pre_order(arr , 2 * i + 2)
中序遍历. 先访问左孩子, 然后访问自身, 最后访问右子树. 因此调整先序遍历中的三件事情顺序即可. 后序同理.
堆与堆排序
在了解了树的顺序表存储方式, 以及树的一些递归特性后, 我们可以引入"堆"的概念.
大顶堆: 对完全二叉树中每一个元素arr[i] , 如果它有孩子, 则它的值一定大于每一个孩子, 比如:
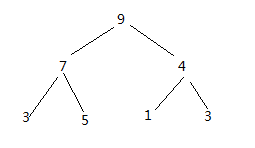
这样来看, 大顶堆中的最大的元素一定在最顶上. 我们也称这是堆有序的
因此, 对一个数组排序,可以这样做:
- 将数组调整为一个大顶堆
- 将这个大顶堆的最上面(第一个)元素放到数组末尾, 最大的有序
- 将剩下的元素再调整为大顶堆
- 将这个大顶堆的最上面(第一个)元素放到数组倒数第二个, 第二大也有序
- 将剩下元素再调整为大顶堆
- … 直到所有元素都有序
问题的关键在于如何调整形成大顶堆(堆有序)了: 我们可以依次遍历树, 将小的沉到sink下面去,而形成堆有序.
准确来说:
-
遍历前一半的元素,
-
对每个元素, 将其和自己的孩子比较, 要是比(左右孩子中)大的那个孩子小, 就与其交换. 交换后依旧和孩子的孩子进行比较/交换, 直到沉到最低(没有孩子)
def sink(arr,k,N):
'''
:param arr: 需要堆有序化的数组
:param k: 要不要下沉的那个元素下标
:param N: 因为在排序中我们后面建堆规模是逐渐减小的, 需要一个参数去控制堆的大小
:return:
'''
while 2 * k <= N : # 对后一半元素不用再看要不要下沉,因为他们丁克(没孩子)
j = 2 * k
if j < N and arr[j] < arr[j+1]:
j +=1 # 如果有孩子更大,要换也换右孩子
if arr[k] >= arr[j] :
break # 比较后还是比孩子大则不需交换
swap(arr, k , j)
k = j # 进行下一轮比较
def swap(arr,i,j):
temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
因此堆排序算法如下
-
将整个数组调整成大顶堆
-
对于堆中的每个元素将第一个与arr[N]交换,使得第下标为N的元素在正确位置上 (N初始为 数组长度减1)
然后N - 1, 重新建堆, 重复上述过程
def heap_sort(arr):
N = len(arr) - 1
for k in range( int(N/2) , -1 , -1):
sink(arr, k , N)
while N > 0:
swap(arr, 0, N)
N -= 1
sink(arr, 0, N )
k = j # 进行下一轮比较
def swap(arr,i,j):
temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
在接下的文章中, 将继续介绍有递归的稍微深入点的东西, 帮助我们更透彻地理解recursion(递归/递推). 之后会对分治,回溯, 剪枝等更复杂的应用如进行介绍.














 2382
2382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









