






目标分类
1.数据准备
数据来源:
现有数据集的子集;网络采集;人工标注
数据扩充:
原始数据切割;噪声颜色等像素变化;旋转平移等姿态变化
数据规范:
均值处理;归一化;大小调整 resize
图像效果算子
使更模糊(高斯卷积核),使更清楚(unsharp卷积核),动作模糊(motion filter)
旋转平移 R, T
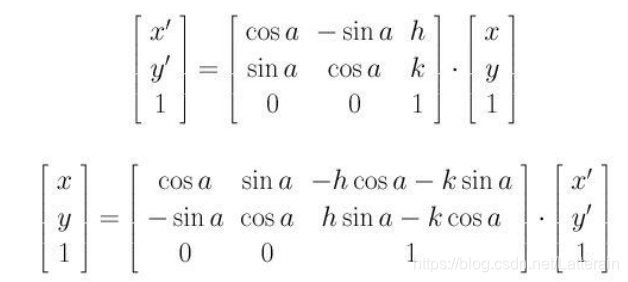
2. 模型设计
基于现有模型局部更改(借鉴已有模型)
类型:
分类:表情分类,人群分类
分类+回归:表情+程度,种类+信心,什么人+人数
多目标分类: 面部行为,群体行为,车流预测
注意力网络添加
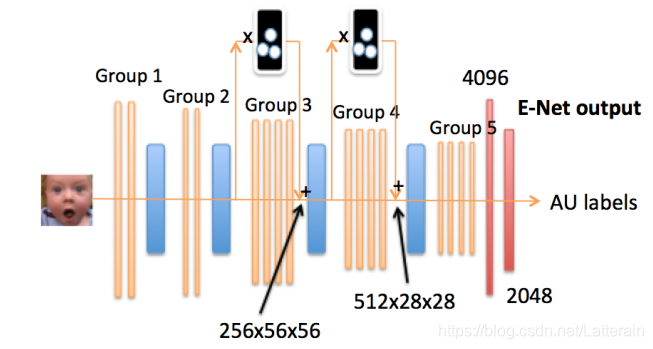
局部学习网络
针对不同的区域进行针对性学习,不同的区域的学习对区域的分布能够自动适应
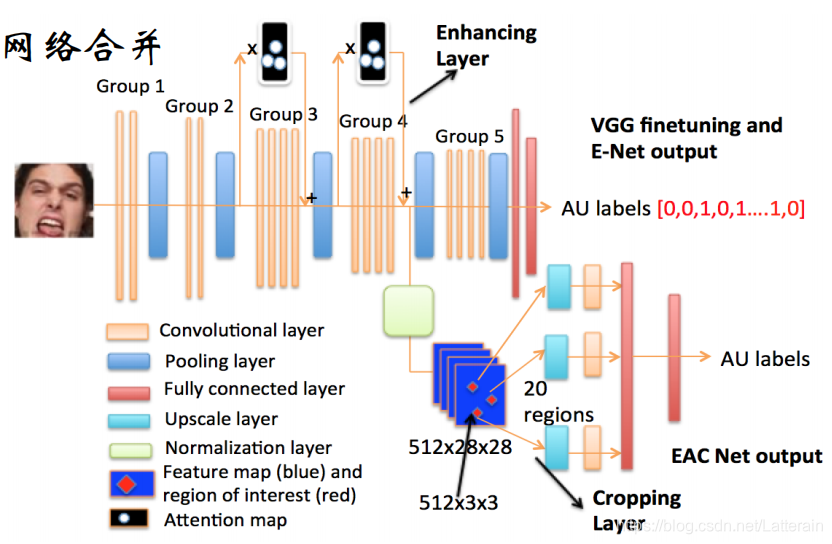
无需提前进行面部对准就可以对面部行为识别
脸部各个行为单元局部针对学习,局部信息可以单独用于某个行为单元识别
可以根据控制肌肉的分布以及人脸特征点检测结果确定区域,更具有合理性以及可操作性。
3. 训练细节
-
GPU-Batch size, 是否并行
GPU内存和batch size 关系 -
数据循环方式/平衡性考虑
数量较少的类别,数据是否需要补偿
从头到尾多次循环
每次随机选取部分数据 -
网络深度宽度确定
层数变多,参数变少 -
损失函数设计
分类:softmax,直接拟合 -
学习率变化方式,模型各层学习率是否一致
模型各层学习率是否一致 -
评价方式:准确率,F1 score
F1 score = 2precisionrecall/(precision+recall)
迁移学习
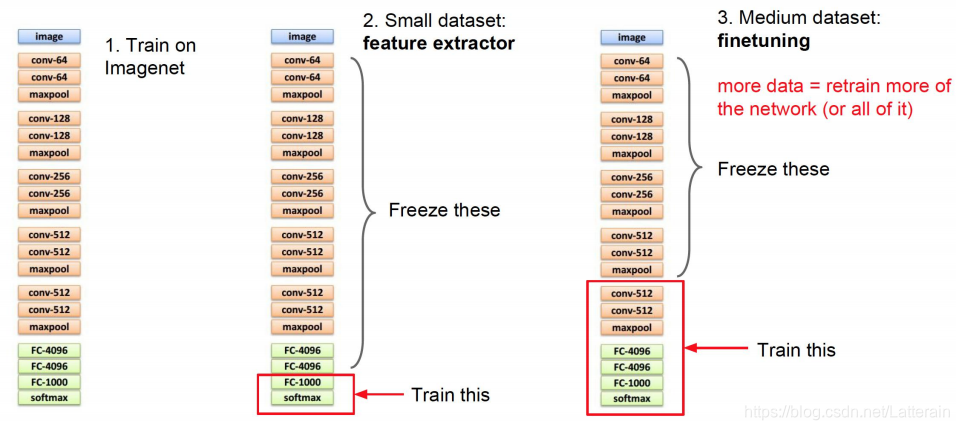
不同数据情况:

学习率处理:
最低卷积层基本不变
中间卷积层看情况
最后全连接层,结构参数均变化
ImageNet模型,这里选择VGG,因为结构简单。














 9154
9154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









