







目前,对于文章中提取关键词最常用的方法莫过于TF-IDF,但是这样提取出来的关键词并不一定准确。
举个最简单的例子来说,在新闻中最前面出现“记者李元芳报道”,分词后的结果是“记者、李元芳、报道”,对于这三个词,“记者”和“报道”的经常出现,idf值一般来说可能会很低,而“李元芳”这个刚出道不久名不见经传的无名小辈可能对google免疫,造成的结果是idf值极高。尽管“李元芳”在文章中仅出现这一次,但足以奠定它是关键词老大的地位。
显然如果把“李元芳”作为文章关键词是错误的,至少也不应该排在前五位。于是有人想到可以用词频的方法来干掉“李元芳”,文中出现一次的统统不考虑,这样的方法在一些情况下有效,但是当文章很短,几乎每个词都仅出现一次的时候就提取不到任何关键词了。另一种方法是干掉idf值很高的,但是值多高才是高这又是一个问题。
细细分析来看,之所以出现这样的局面完全是idf在作怪。其实在求解idf的时候,需要得到每个词词频,而这又需要语料来统计。显然,语料是越多越好,无奈现实中我们得不到这么多的语料,所以只能从特殊到一般,这虽然有道理,但是不是很准确就难说了。
为了彻底解决这个问题,应该要做到不需要使用词频进行关键词提取。于是,聪明人士引入了信息熵的概念,具体可以看这里:
http://zh.wikipedia.org/wiki/%E7%86%B5_(%E4%BF%A1%E6%81%AF%E8%AE%BA)
前面都是铺垫,下面就说说如何在文章中利用信息熵提取关键词:
首先我们需要明确一点,一个词之所以能称为关键词,原因就在于这个词左右能搭配的词很丰富,于是我们可以定义一个词的信息熵:
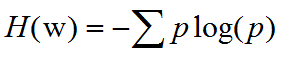
W代表该词,p代表该词左右出现的不同词的数目。
比如现在某篇文章中出现了两次 A W C, 一次B W D
那么W的左侧信息熵为:
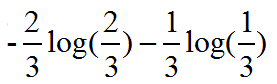
2/3表示词组A在3次中出现了2次,B只出现了一次,故为1/3.
W右侧的信息熵也是一样的。如果是A W C, B W C
那么W右侧就是0,因为是 -1log(1)。
对所有的词计算左右信息熵,如果某个词的左右信息熵都很大,那这个词就很可能是关键词。
拿文章一开始提到的反例来说,“李元芳”只在开头出现了一次,于是信息熵为0,肯定不会是关键词了。
最后考虑一种特殊情况,如果某个词左侧的信息熵很大,右侧信息熵很小,而他右侧的词左侧信息熵很小,右侧信息熵很大。形象描述为 X B C Y,B与C经常一同出现,但是X和Y经常变化,于是可以把B和C组合起来当成一个关键词,我们常常见到“智能手机”作为一个关键词出现就是这个道理。这也涉及到NLP中另一个很有意思的研究方向-新词发现。















 8994
8994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









