其实讲了索引的这块了,接下来可能要讲的内容是物化视图,然后讲分区,然后数据库表结构的设计,你们总问我SQL优化,
那在讲整个物化视图之前,咱们之前讲索引了,对于数据库的设计,咱们从头到尾的去过一遍,然后我们工作中怎么去设计
表结构的,当然这个没有实例,只是凭我说一下,然后就是个人的一些工作中的总结,跟你说一下,大体上有几种,其实我还是
要画图,然后去说明,当然我只是拿ORACLE为例,MYSQL其实我也不是很熟,什么分区,分片,分表啊,这种都是很easy的东西,
但是只是说概念是很easy的,但是场景还是很麻烦的,你业务得懂,你还得考虑数据库的可扩展性,包括一些很多的问题,
说一说数据库的设计,我就画一张图吧,我这边画一幅画,可能列出来这么多种,当然我就用文字描述,在你们的心中,
对于数据库的好与坏,SQL语句优化怎样啊,这个其实相当于怎么说呢,或者你买一个产品,会有一个售前售后服务,我觉得
这个东西就相当于售后服务一样,SQL优化这个东西是属于售后,售后出现的事情,才叫做SQL优化,事前出现的问题不叫SQL优化,
这个SQL优化肯定是我们最后要做的一件事情,在你这个立项开始,在做分析开始,然后再加上表结构设计开始,等等这一系列东西,
咱们要关心的其实还是售前,这个才是解决的最根本方案,售后这个事其实我并不太看重,那我就从咱们最开始,我分两大点,第一
大点我用,数据库设计,无论是建模还是从整体所有的,分两大方面,第一方面是对于数据库表的设计,第二大方面其实是对于索引,
对于索引的设计,你不能这么说,对于结构优化的设计,这是两大方面
1. 数据库表的设计
(1)业务需要学会区分 先从表开始,咱们的一个数据库表,可能最初规划的时候,你有一点需要做的事情是,这个东西都是太简单的事情了,
咱们就不提数据库范式了,那个是规范,你一定要遵守是最好,数据库表的设计,第一点是要干什么事呢,在我看来你最重要的是业务你得
会切分,就是业务你得学会切分,然后这个业务你怎么去切分呢,业务切分就是相当于你某个产品吧,我们就举电商为例,电商那个产品为例,
其实电商这个东西之前也没提,他到底是怎么回事呢,因为它平台很大,涉及到很多系统的结合,可能传统行业走流程,电商走一个订单的
一个量,是一个很大的需求量,从供应商开始,一直到结束,涉及的东西其实是很复杂的,你比如说我打个最简单的比方,我在电商网站上,
现在给我一个平台,比如淘宝的平台,然后我有一个供应商,相当于卖东西的卖家,他想去卖一个产品,比如是苹果,IPHONE手机,或者
卖其他的东西,总之是卖一个产品,那最初肯定是做什么事啊,我这里面肯定是有一个供应商系统,肯定有一个供应商的系统,我就
这么写了,这个系统主要是做什么事呢,我这边来了一个供应商以后,他们要和网站要签一个合同的东西,就是供应商的资质啊,审批啊,
等等就是一系列的东西,这个东西其实是很复杂的,包括他的供应商的编号啊,还有许可啊,一堆,然后就往系统里去录入,然后他们两个
完成合同以后,这个供应商系统第一个步骤就走完了,填完这个东西以后,下一步怎么办,下一步可能就涉及到商品的系统了,
管理商品的,那这个商品可能不只是一个数据库,可能是多个数据库,比如你卖鞋,卖衣服,卖产品,卖吃的,还有卖其他东西的,
供应商还是要操作商品这个东西的,然后就往里添加商品,接下来还有一个库存的系统,进销存系统,库存,那这个库存的系统,
比如说,你卖手机,卖苹果,我这里就有添加苹果的商品了,然后你就得告诉苹果有多少条吗,比如他录入了500件商品,就是库存,
接下来往下走,这个东西还是很复杂的,还有一些其他的环节我就略了,因为太细节的环节我就略了,然后紧接着这个东西还有一个,
其实所有电商都有一个非常核心的模块,这个模块就是ERP,不管是天猫还是淘宝,还是其他的这个,都有这个ERP,不管是哪一个角色吧,
你做了这些操作以后,都得回到这个ERP系统里,然后由ERP交给前端的一个系统里,前端什么系统呢,就是咱们的网站系统,就是这个网站,
网站系统就是用户打开网站购物的网站,看到这个商品,访问商品这个模块,就是这个系统,接下来以后,其实整个这一块的过程,
一般在电商叫SCM,它是一套,是好几个系统组成的一个综合的系统,然后EPR里面的分类又更多了,然后接下来就是这个
用户client端,可能要去下订单买产品,买产品的过程中肯定会涉及到很复杂的逻辑,我举个最简单的例子,我们去提交订单的时候,
提交完了之后,每个电商都不一样,一般都会有一个分单的系统,什么意思呢,你这个网站是第三方的,还是自营的,会有淘宝,
天猫,自营的产品,京东自营的或者是其他自营的产品,把用户所下的单根据类型进行一个分流,根据类型进行一个分流,如果是
要走一个系统的话压力太大,这边可能就是处理订单的系统,这是一个分单的系统,然后这里有一个处理订单的系统,
自营的处理订单的系统,然后这是第三方处理订单的系统,三方处理订单的系统,然后接下来还有一些细粒度的系统,然后还有
什么发票啊,发票怎么管理,有一个发票的系统,然后还有一些更细节的系统了,你比如说我这边要做促销,还有好多的小系统,
价格管理的系统,这商品多少钱,还有一些促销的系统啊,这些都是加进来的业务,这些分散的点都非常的多,总之你要走一个流程
走完了之后,其实电商这东西怎么说呢,它是很复杂的,它是根据每一个人的角色不同,提供了一个职务,但是其实最终最核心的还是ERP,
无论什么样的系统,最总都会汇总到EPR系统里,这是内部人员去使用的,或者财务去使用的,
财务肯定是会涉及到钱啊,财务系统就涉及到结算了,一般是在咱们用户去付钱,交给的都是网站,然后和供应商定期签合同,
每个月的1号,2号,就是一个月一结算,这个月我卖了500件产品,然后你给我finace财务系统,然后财务系统对应的还有一个结算系统,
然后把对应的钱对应的供应商,是这样的,一般的都是这样的,包括你看到的一些淘宝啊,用户转账都是转到类似支付宝,余额宝,
自己的公司里,再过多少天以后,一个月以后,然后把这个钱转给供应商,都是这么去做的,其实针对于不同的操作,供应商其实也有
一个系统,这个只是供应商的合同系统,那你要是再往下分的话,供应商的管理系统,比如我用户去下一个订单,下一个订单之后,
比如要卖Iphone手机,其实供应商管理这个系统,比如用户下了一个手机Iphone,然后这边直接通知给供应商了,供应商肯定是自己
利用这套系统,做一些包裹啊,快递啊,这个系统是供应商自己操作的,是供应商自己具体去操作的,你比如用户买完了,
又申请取消订单,那供应商首先得知道,其实说白了吧,每一个角色,在咱们电商里边,你自己的这个人,每一个供应商
都是和用户直接打交道的,总之这个东西是很复杂的,就比如京东不是很大的网站,跟淘宝是没法比的,他那个系统里面就涉及到
100多个小系统,100多个子系统,就是覆盖的非常多吧,这个系统和系统之间,会有一些交叉,其实他们最终都是涉及到ERP,
往这里面去装数据,ERP它是不对外网公开的,它是内部去做的,大体上都是很乱,不说这事了,所以第一件事是很重要的,
要学会数据库设计,第一点就是学会业务切分,比如你做O2O电商,你自己有很丰富的经验,规划出来这个东西,业务切分是
非常重要的一件事,然后再往下看可能就是涉及到细节问题了,咱们去做数据库表结构设计,他这个东西就是分层,物理分层
(2)逻辑分层,这个什么意思呢,你自己得规划好,有一些就是基础信息,你这个平台搭建之初,肯定有一些基础信息,你上层的
业务其实是根据基础信息去操作的,刚才我只是根据供应商这一个角色,那你根据用户的角色就更麻烦了,用户可能会涉及到我的
空间,还有我买到的产品,涉及到网站就更多了,涉及到购物车,这个就很复杂了,这个就不说了,刚才我就说看到了分层,你要把
基础表要设计的非常好,你只有基础表设计得非常好以后,你再往上层去扩展业务的时候,你才好扩展,才很灵活,基础信息这个设计
是非常重要的,分层一般就是基础信息加上你的业务层,每一个业务层可能有一套数据库,你的一堆表,就是逻辑分层,就是数据库
分层,就这么说吧,你做好了这两件事以后,这个是整体最大的框架,然后再往下,数据库分层很重要,再往下才开始要设计一些数据库
表结构
(3)数据库表结构,就是在你了解业务的前提,数据建模,哪些业务和哪些业务分到一个数据库里,就比如供应商涉及到几张表里,
那他单独放在一个库里面,然后用户涉及到好几张表,单独放在一个库里面,这个东西相当于什么啊,就是一直拆分吗,有垂直,
垂直去拆分,那其实也是根据不同的业务去拆分,这个有点像第一块,还不一样,这是根据数据表层次的去拆分,然后呢,这个数据库表
结构的设计与拆分,大方向的垂直拆分以后,比如有一张订单表啊,或者是用户表啊,这个信息量都很大,然后你就会才去一定的策略了,
这个订单表很大的,这个时候才会涉及到水平拆分
(3.1)mysql水平拆分(分片) 比如说订单这个表,然后奇偶数,订单的ID,取余2等于0,比如取余3等于0,取余5等于
0,取余5等于0,可能不是4,2和4是一样的,取余3等于0,取余5等于0,可能是会把一张表水平的拆成多张表,这里面放取余等于2的一些数据
这里面放取余等于3的一些数据,这里面取余等于5的一些数据,可能还有其他的算法,不一定只是按照ID去拆分,我只是说订单,我只是说
用户,用户可能还有一些级别,VIP用户,普通用户啊,就好像腾讯里面的QQ,都有些级别吗,有黄钻,红钻,里面都有不同的业务功能,他那些
业务功能都是继承的,你可能有一个黄钻,基础功能有三个,1,2,3,黄钻在这两个基础上再加两个功能,然后红钻再在这个基础上再加几个
功能,然后紫钻再加几个功能,VIP,超级VIP,权限都有不同的,所以可能我猜想,我没看过腾讯,最大方法肯定是不会通过ID去分的,
最大方面可能是经过用户的Type类型,去进行一次水平的拆分,然后Type类型之后呢,要想QQ的用户量有多大啊,通过类型拆分了以后,
还得通过一次取模,再次产生,只能通过几级的拆分,第一级是通过Type,拆分3个表,然后一个Type里面再通过取模,再拆分,如果还复杂
就继续再拆分,这个架构就造成一个什么问题呢,我查数据的时候,这个就很难查,我要查一些数据在这个库里有,在这个库里有,还是
在这个库里有,那就可能是两个库进行join了,join查询了,或者是三个库里进行join查询了,多个库进行join,垂直拆分是按照业务
去拆分,一会会讲到,拆分是吧,刚才是按照业务拆分,3个库join这块,不是有人要我讲mycat,mysql,mysql的代理是mycat,mysql的
最佳代理,就好像咖啡加牛奶,这个最佳代理,其实我也去看了一天,这个东西其实非常不成熟,因为它现在只支持两个表的join,
多个表的join就是不支持的,而且其实你仔细想一想,这个性能真的有他说的这么高吗,我觉得不见得,虽然我没有做过测试,
但是mycat肯定比你自己写业务要快,其实在一个开源产品上做一个封装了,如果你有能力的话,你也可以自己公司开发一套,其实
你看京东,就包括淘宝,他肯定不是用开源的mycat,淘宝是用comba,他肯定是类似于mycat这种东西,但是他是自己实现的,他自己实现
可能是通过NIO异步的通信,去解决了这个问题,比如像数据库中间件,他为什么开源啊,因为做不了那么强大的东西,
所以开源,然后一般是根据你实际的业务去设计数据库中间件,说我这个东西到底要返回哪几个库,然后我怎么去做访问,采用什么技术,
然后数据来了之后我要怎么合并,然后我怎么去排序,怎么去做统计分析计算,一系列的东西,根据你公司实际的业务去做实际优化的,
不可能有一种通用的产品能实现这个事,这是我自己感觉的,MYCAT是我暂时pass掉的一个东西,因为它现在才出到1.5版本很不稳定,
两个表join,而且两个表join的时候还有各种各样的问题,然后分片就是把一个表里的数据分成多个数据库,分片的这个概念,他们之间
做汇总的时候,他也有一些问题,说是挺清晰的,但是其实还是挺呕心的事,就是MYSQL的一些原生的问题也没有解决,之前咱们说MYSQL,
MYSQL的主从怎么做啊,比如这是MSYQL的主服务器,这是MYSQL的从服务器,其实那天也说了,MYSQL主服务器有一个binlog日志,就好像
ORACLE的日志归档一样,就是咱们两个都是空库前提下,没有数据的情况下,如果有数据,就要先备份一下,把这里的数据导到这里面,
好多年前我一直用MYSQL,MYSQL有两个线程,跟主数据库,从库有两个线程,一个是跟主数据库通信的线程,一个是解析日志
的线程,他把里面的日志转化成SQL,去执行,其实还是一条SQL一条SQL的去执行,所以说MYSQL的这种主从同步,它是逻辑上的同步,
不是物理上的同步,物理上的同步是把数据直接COPY到这上面了,这种同步其实性能还是很不好的,你想想啊,就好像我们把一个dump文件,
去导入mysql,去批量的去执行SQL,往里面加数据,他其实就是这种逻辑,然后利用主从还有问题,比如我配置了一主多从的机制,可能两个
从,3个从,4个从,主挂了,他的切换一个从服务器,这个时间段如果有数据进来,他挂了的时候如果我进来,那我肯定有丢数据的问题,
所以说即使是主修复好了,然后主服务器再上来的时候,那肯定数据就不一致了,就会有这个问题,其实碰到过很多的这种案例,开始做
MYSQL主从,各种各样的问题,数据不一致,就比如MYSQL的硬件坏了,磁盘坏了,然后切到一台从服务器上,然后就会产生这个问题,
如果你要做多主呢,多态主服务器系统,其实他还能保证高可靠,数据不丢失,但是会有一个问题,从服务器挂,这也是MYSQL的一些问题,
然后现在不是基于这个问题有一个MYSQL,我记得看文档它是用这个hproxy,去做这个高可用这个事,两台这个hproxy,访问我们的
中间件mycat,后面再通过心跳的机制,去监控MYSQL的集群,其实他这个东西也做的不稳定,反正也不太好,你还不如采用
这个官方提供的方案,去做主从,做主从分离,我刚才说到的这个事情,是数据库的拆分问题,然后这个拆分其实分的很细,
主要说其实是水平拆分,水平拆分,那这可能是MYSQL的解决方案,因为你在数据大的时候怎么办,那就水平拆分,其实要是到
ORACLE里面那就easy了,ORACLE他肯定要保证数据不丢失,性能也能保证,分库是已经实现分库了,把一些固定的业务逻辑的表
放在一个库中,垂直拆分是第一步,相当在ORACLE里面呢,可能产生分区的方案,一些各种各样的分区
(3.2)分区:
只有你想不到的,没有不提供的,各种各样的分区,咱们以后要讲,我们讲的range分区啊,区间分区啊,list分区啊,间隔分区啊,包括
hash分区啊,很多很多,七八种分区吧,这个东西还可以转成自定义,然后MYSQL他要求的是单个分区,MYSQL他就不叫分区了,MYSQL的
叫分片,就把它放在不同的数据源上,单个分片是不大于1000万条数据,我觉的这个频率还是很大的,就算你一个片上只能放1000万
条数据,当然是单表1000万条数据,一个片上,其实咱们的这个ORACLE分区已经很明了,你可以做无数个分区,ORACLE当是记得是OCP
的时候,他要求是500万条数据一个分区,那其实一个大表可以是无限个分区,然后每个分区可以存个500万条数据,然后他这个分区的
查询的性能还是很大的,还是很好的,其实早期就是因为MYSQL的分区性能不好,5.0之前可能还没有分区的特性呢,5.0之前是没有
分区这个特性的,5.0之后有分区这个特性,但是性能还是和ORACLE没法比,它会产生一个分布式事务的问题,分片MYSQL,就是相当于
ORACLE里面的分区,最终我要两张表的数据进行join的时候,当时我们的ORACLE是能做的,ORACLE叫做跨分区查询吗,我这500万条
数据和这500万条数据今夕跨分区查询,如果是多表join的话,MYSQL就得用多表join来完成这个事,那还有一件事情,是什么呢,
就是咱们要讲的物化视图
(3.2)物化视图:
其实物化视图这个概念,就解决了多表join的这个问题,多表join会有很多问题,分布式事务的问题,两个数据库要做写操作的话,
有分布式事务的问题,ORACLE里面的解决方案就是物化视图,那你想一想一件事,比如我们做多表join,一张表里数据量很大,这一张
表里数据量也很大,然后这一张表里数据量也很大,很多张表进行join,他join他,他join他,可能还有一些子查询,一系列这个复杂
的东西,MYSQL就解决不了这个问题,但是咱们ORACLE里边呢,MYSQL里也有视图,在ORACLE里面有一个物化视图的概念,就是把你
自己写好的一个视图变成一个实体,就是变成一个存到数据库的一个位置,它是物理级的存储,物化视图的概念,那咱们平常的
视图呢,是一个虚表,其实走视图还是要走几张表联合起来找到一个结果,那在咱们的ORACLE里边,物化视图就是相当于把这
几张表的查询结果,放到一个表里,这个表就保存着一些数据,那我client在进行查询的时候,确实是查这张表里的数据,
查物化视图表里的数据,如果是正常视图呢,其实还是相当于你走这个,1,2,3,4,5,这几张表join,那这个区分就很大了,
join和不join的区别就很大了,所以物化视图是能提高咱们查询的效率,也是非常高的查询,能明白我说的意思吧,然后
继续再看,其实还有,如果你系统够好的话,就相当于把数据存在一个中间表里,如果真涉及到一种业务的话,其实解决方案还有很多很多
(4)中间表:
中间表的方案,中间表的方案是什么意思呢,其实就是物化视图的另一种了,比如你这个表的数据量很大,然后很多条数据,然后我可以把
这个东西汇总成一张小表,比如你这里一天要存放10条数据,某一条记录吧,比如我这个表里有一个type字段,一天要存放10条数据,然后
还有好多条type类型,那我可以把他利用一些存储过程,有一些其他的手段,把他这个进行统计分析,存到另外一张中间表里,那就是
每一条数据就存一个type,一天的数据是10条,然后type2这个数据是15条,type3是多少条,然后我做月,年统计分析的时候,可能就查
这一张表,再来一个,可能这个是天表,这边可能就是月,然后再来一张表就是季度,或者是年份,有很多张表,或者你也可以把月季年,
划分成一张表,然后自己经历的一个周期,根据周期的类型去指定月份,季度,年,这个就相当于一个中间表的方案,这个时候也叫缓冲表,
我最后用户client端去做查询的时候,只要查天的表,月,季,年的就行了,不会走这个数量很大的基表,去做查询了,其实还有很多种,
还有其他的方案,设计的方案
(5)设计的方案:
你有没有想过你这个数据量很大的时候,我能不能靠一些优雅的数据表的设计,去完成一个很好地事,比如你这个表要和其他的表进行join,
做其他的事情,这里可能是一个树形,可能是其他的结构,第一张表和第二张表要关联的字段,已经关联好了,已经存储好的一个节奏,
我可能利用一个存储过程,很简洁的,然后再和这张表进行join,这个效果性能可能就会更好了,针对于不同的场景,具体去做业务逻辑
的设计,然后抽象出一张比较简单的表,然后他们两个进行join,咱们数据库瓶颈的一些方案吧,这个是我们单独从数据库表去走,
你就会有这么多的方案
2. 对于结构优化的设计
由于咱们昨天讲了索引了,第一方面咱们先放在这里不讲,先讲第二方面,咱们先讲第二方面,然后从结构上来,从结构上去优化的话,
还有很多,最简单的就是建立咱们的索引,最简单的一种方案就是建立咱们的索引
(1)建立索引:
我想问一下你们平时工作的时候,都是怎么去建立索引的,比如设计这个表啊,数据量可能是比较大的,可能有几百万,几千万,可能
更大的条数,你们都是怎么去建立索引的,有没有可能经常去建立一些规则索引,就是经常关联字段去建立索引,就是规则索引吧,
在建立规则索引之后,怎么去查询呢,就是根据解释索引吧,其实规则索引还是挺难建的一个,你是怎么去建立规则索引的,这个
规则索引不好建,难道你说,你在设计表之初就得想好这个事,比如这个表,这个ID先不考虑,他就是咱们要建立的一个规则索引,
可能有一个name,这里面可能有一个其他的字段,可能有一个其他的区域,AREA,AREA区域,还有一个什么啊,比如一个日期date,
然后可能还有一些字段,我现在就跟你说一个问题,就是这张表数据量很大很大,几亿,上亿,或者几十亿,那你除了要分区以外,
分区是肯定的,这么大的表,那么你现在这个规则怎么去建立呢,规则索引什么意思,就是你主键不是来一个uuid就完事了,
就是有一定规则的去生成的,比如前几位你要规划成什么样,后几位你要规划成什么样,然后再往后几位你又要怎么去规划,
然后最后去查询的时候,正常来讲如果你不建这个规则索引的时候,我举个例子,某一天我这个type字段挺频繁查询的,
那怎么办啊,后期我们在type上建一个索引吧,在type上加一个索引,那现在这张表就两个索引了,到最后你发现日期也
是非常频繁的去查询,怎么办啊,咱们再去在日期上建一个索引,就三个索引了,然后随着字段的多,你的需求不断地去扩张,
那你就会发现,完了,还得建一个索引,本身一个数据库表的数据就很大,再建10个索引,你以后再做持久化操作insert的时候,
或者update的时候,你总得维护索引,你总得去做,IO性能,就是包括你读的时候,找的时候都很麻烦,会根据几个索引规则去找,
这个性能肯定是不高的,那我想问一下,你是怎么去建立规则索引的,最常用使用的查询条件,后期也补过索引,where条件多例的话,
算出不重复的总数,然后创建符合索引,由多到少排序,肯定也会涉及到一些,就得建复合索引,你得考虑这张表有多少个字段,
你得有预留字段,后期需求扩展可能要添加,或者从考虑之初,这张表可能是不稳定的,以后可能会加业务,要把这个业务口流出来,
来一个额外的一个外键,然后把业务这张表直接给建出来,可能直接关联出来,以后什么时候用到这个业务了,这张表直接当外键了,
直接和我扩张业务的这张表,直接挂钩了,预留字段是干什么事,预留字段其实预留的都是外键,因为咱们工作都好几年了
就肯定会看到一些公司,不管有的没的会的不会的,一张表里总会有几个预留字段,那这个预留字段你知道他是真正干什么用的吗,
你别告诉我预留字段以后的目的就是为了我有一个条件,我加一个字段,然后去做一个预留字段的,不是这个事的,预留字段其实
不是干这个事的,预留字段是干什么事的,是我以后,刚才我们说了,我这张表不可预期,我这张表写完了之后,我要预留几个字段,
尽可能的预留多几个字段,比如预留4,5个字段,我可能后期有一个业务,这个业务可能有涉及到一张表,根这张表产生关联,
那我就会预留一个字段,那这个字段就相当于这张表的外键,就是他这个外键跟他关联吗,这个预留字段是干这个事的,以后我就要往
预留字段上加一个新表,然后用这连个join起来,我觉得预留字段最主要的目的是干这个事,他不是说随便一个字段加一个需求,
然后你就改了,我宁愿加个需求加个字段我可以做其他的事,不去做这个事情,能明白我的意思吧,然后这个建立索引其实还有
规则的,刚才我说到了这块,就是做扩展字段,这个规则是什么啊,咱们索引是不能做任何函数操作的,能理解我的意思吧,比如
你where条件,where id,比如id是一个索引字段,你要把id做一些函数的操作,substring啊,或者其他的那你这个索引值就失效了,
就是你这个索引不能做任何函数的操作,主要是做函数的操作索引的值就失效了,这个应该能理解吧,应该知道吧,这个应该能理解吧,
只要随便加一个函数,就失效了是不是,那你现在这个索引你要怎么加呢,是不是挺不好加的,我们的规则是,正常我们的规则是怎么加呢,
就是这个东西是这样的,比如说我有一个业务,首先看哪个是最大的一块,比如说咱们要统计人吧,全国各地的人,区域就是北京,
天津,上海,这个范围是最大的一块,北京这块有多少人,天津的这块有多少人,然后上海这块有多少人,咱们就举个例子吧,
因为我也没看过腾讯的user表里面,怎么去设计的,我就是猜测,随便猜啊,他肯定首先是按区域去划分的,你比如说北京,他这个
字段就是1100,我就随便写一个,北京可能是1000,前四位,那索引的前四位就是1000,然后呢再往下走,北京下面还有一些区域吧,
大兴,昌平啊,什么房山啊,区域是不是有一些区域编号,就是10001100,延庆,随便举一个例子,然后大兴是10001200,我就按照这个
数字当做一个type类型了,然后再往下走,它是属于什么会员级别的,当然会员级别不是固定死的,主键的,刚才我们只是随便一说,
因为QQ有一个会员升级的功能,开始可能是一个普通用户,那以后可能就变成一个会员了,不可能去改主键去,思路是错的,
他不可能这么去建,但是咱们假设吧,他有些其他的字段,那就继续往下划分,比如第一种人员的类型,你有一个外键表,
第一种人员类型,然后type是1的话,我就写一个1,然后第二种,type是2的话,在这个基础之上再去扩展,那这个时候就变成
100011001什么,这边就变成100011002什么什么,反正就是按照这个规则吧,去往里加数字,然后会剩下不够的位数,
我们可能生成一个UUID,比如我用了多少位,用了10位,UUID一般是32位,或者你再长一点,可能还有20位是我自己
随机生成的一个UUID,那这个整体去拼成一个ID,就是根据业务规则去拼成ID,这样的话你做查询就简单了,
你要查北京的怎么查,北京不是1000开头的吗,那我就查北京的区域,
1000后面一堆数小于等于id,大于2000后面一堆,最后肯定会转成0123这种形式的,按照这种形式去查询,那这个索引肯定是会
加主键的,加index,一下子就过滤了一部分数据了,你要查北京延庆的,那就这样,10001100后面一堆数字,然后去小于
等于id,然后大于100012000后面一堆的数字,中间一小部分数据就是属于北京,再往后就是延庆的数据,直接给我过滤出来了,
就是具有业务规则的索引,都是这么去建立的,1000后面加一个斜杠,加一个type就是abcd,就是这种东西肯定不行,或者是
加一些其他的东西,总之你不能让这个索引最终失效,因为你不能在这个索引上加任何的函数,所以就固定了咱们业务组件的
规则,就是一个数值,加上一个随机的UUID,UUID不都是这样的吗,不是AF207CKO13就是这种吗,
这戏字母啊,都会转成0123这种形式的,就是一个32位的大数字,然后通过这种东西去查,说的挺多的,明白我的意思吧,
这种就是建立索引的规则
(1.1)建立普通索引
(1.2)建立规则索引
(1.3)建立复合索引
DataBase 是ORCL,这个Schema,没关系,就是随便看一眼,就是有一个DAT_CHECK_DATA表,表里就是我们的检测,以后数量肯定会很大的,
我没模拟的这么大,我就放了一点点数据,就放了10150条数据,就是一万多条吗,就是以这种规则,看见了吧

其实我这个主键是有业务规则的,其实我这个业务规则就是相当简单了,就是前几位可能都是北京下面的了,北京下面的某一个区域,
你会发现前面都是一样的,前面都是1129,然后这个是1112,然后没有了,就是1129和1112,这都是有业务规则的,然后后面就是根据
你生成的日期,我copy一下,我直接粘到这儿,1129就是一个规则,可能是北京的一个区域,然后再空格,2015年06月份19号,是这么划分
的,我们在这里找一个1129的,这个就是这样的,那这个业务划分就是这样的,2015年11月21号,其实都是有这种业务规则去划分的,
那我现在想问你,1129是什么东西呢,有一个叫dist这张表
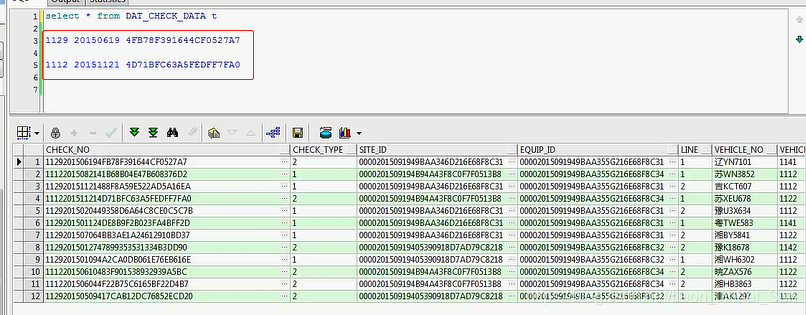
我先query一下,其实你会发现,这个它是有规则的,1129其实就是把112900后面的两个0省略了,1129其实是属于北京市的一个延庆县,
1112是属于北京市的一个通州,通州区的一个数据,那我现在就可以去做一个过滤了,那我查询的时候怎么去查询啊
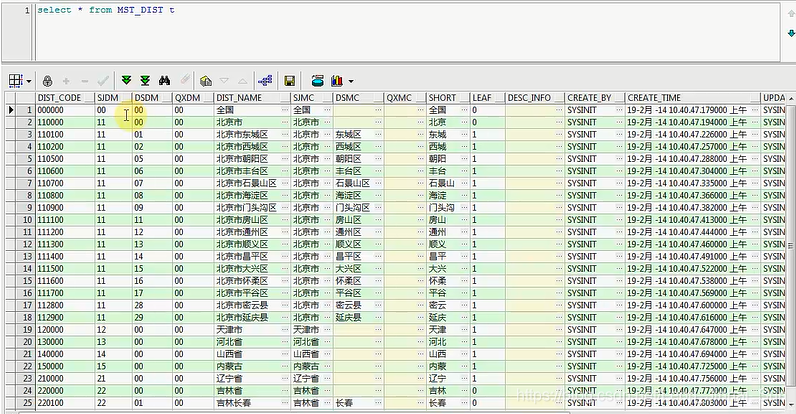
比如我这张表里有这么多数据,只想查延庆或者通州的数据,我查的时候就是SELECT * FROM 表,然后这个表叫DCD,where条件
就是什么啊,就是CHECK_NO肯定是一个主键,他应该是满足什么条件呢,大于等于这个值吗,这后面应该怎么去补全呢,2015年这一块,
你要是想查所有的数据,那我2015年,可能还有2014年的,也可以去划分,现在我就想查所有的数据,比如我现在就想查2015年6月份的数据,
那怎么查,就是前面都是不变的,不是1506开头的吗,6月份的数据这里就归零,20150600,后面的就全用0去替换一下,这个你确实得这样去做
你要去查6月份的数据,然后把这个复制一下,然后再小于,这样就查询到延庆所有6月份的数据了,直接七月份吧,你就一个SELECT,就是他
大于等于,然后加上AND条件,然后这边是小于,应该是这种语法,这样您看一共有多少条数据,一共649条数据,他一定是2015年6月份到7
月份的,并且是某一个延庆,延庆县的所有的数据,这样的话查询起来就很快了,相当于我直接分区域,直接去查询了,直接走索引了,
刚才的操作理解了吗,这样是不是很轻松就查出来了,明白我说的意思吧,正常情况下,咱们不建立规则索引的情况下,你得怎么查,
咱们如果不建立规则索引的话你怎么查啊,想想你要查区域的话,就是这个DAT表,你得join这个DIST,你这个表里得建一个区域的外键,
然后还得join这张表,两张表进行join,join完了之后你再取出来,那个数据,这样的话你不觉得性能就这样下去了吗,就是我们要把
规则加上去的时候我们就要把规则放在里面,然后查询的时候去做,意思就是这个规则本身就一个索引,大体我就要给你演示这个事,
就是有很多规则它是很正常的规则,无论是时间维度,还是空间维度,这些都是咱们建立规则索引的时候需要考虑的一个事情,就是你必须
做一个设计,你最简单最基础的入门,你要考虑这个索引,你去看看哪个维度比较好,你比如你要按区域划分的话,这就是一个空间维度,
北京,延庆,天津,上海,根据你这个数据量,到底是以空间维度开头,还是以时间维度开头,明白我的意思吧,我这个是空间维度加上时间维度
能够过滤出来的量比较大,所以说我就按空间,如果你时间过滤出来的维度比较大,就时间放在前面,而空间往后走,还有其他的特殊的结构,
明白我说的意思吧,差不多就是这个意思,就是按照不同的维度去建立这个索引,当然这个是一种方案啦,我觉得还是很好用的
(3)复合索引:
还有一种就是复合索引了,就比如说你这个维度啊,你现在不确定,你要有两个索引,要有预留的方案,比如这个表以后建索引可能
要很多很多,那你就得复合索引,联合主键,这么去查,这个维度都不够用了,因为咱们的索引字段一般都是32位的,可能以后我加完
了之后,还不够了,肯定还要预留一个字段,他们两个可能要拼成一个联合主键,那如果你确定有这个事的话,那你最好做什么事啊,
你最好建表之初,把这个字段加上一个联合主键,你宁可这边插入1,2,3,4这种排序,你都可以去做这个事情,那如果其它方案呢,
那就算了,一般我去建立数据库表的规则,接下来还是这个规则啦,接下来还是规则啦,这是索引的建立,没一张表我还要去建立规则,
这个数据规则
(4)数据规则:
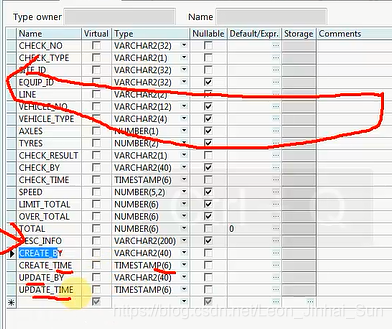
这个数据规则是什么啊,就是无论说我什么表啊,我永远都不会少了4个字段的,这4个字段永远都是放在表的最后的,你可以看一下,
无论哪张表都是有这个东西的,咱们去Edit,去做这个事,这张表里,无论什么情况,后头有4个字段,CREATE_BY,CREATE_TIME,
UPDATE_BY,UPDATE_TIME,就是插入数据的人是谁,创建人是谁,一条数据是谁创建的,创建时间是什么,有时间戳的,更新人,
更新时间,我所有的表基本上都会有这4条字段,为什么啊,这个是咱们以后做数据交换的时候,做数据分析的时候一个非常
有用的,乐观锁version,这个怎么说呢,你是并发的时候需要考虑的,我是很少去做这个事的,其实这个问题用时间戳就可以解决,
在ORACLE来讲其实用时间戳就可以解决,当然时间戳可能就是小数点后面的几位吧,当然我不可能保证这个时间太细,
太细就产生什么了,什么意思呢,这一块比如我有一张表,插入了一堆数据,然后这个数据,有一个人,又把这条数据区更新了,
那么会有一个什么情况,做统计分析的时候,就不对了,原先这个条记录可能是100,这个值,咱们要做统计分析的这个字段,
这条数据是100,然后第一天上传了之后,咱们去做一个统计分析的一个汇总,一个东西给汇总出来了,比如这条记录的汇总值,
当天的值可能是5000,这一列的数据是5000,然后是第二天,或者是过几天,或一个月,甚至是过好久,然后当时那个人录入数据的
时候是录错了,这块不是100了,然后把这个改了,那你想想这个统计分析的结果是多少了,应该是5020了,是5010,是5100,
之前这个值是100,100的时候是5000,把他改成200的时候再加100,就是5100,所以说呢,这个时候你就的用UPDATE_TIME去做
一个数据的重新统计了,你就查询一下这个UPDATE_TIME有变更吗,哪张表UPDATE_TIME变更了,然后把UPDATE_TIME变更的抓出来,
抓出来之后,看看这条记录统计的到底是哪一天的,然后再把这条数据重新统计一遍,把之前的这条记录删了,然后再重新统计一遍,
统计完了之后再放到这个位置,可能还会设计到后端的存储过程的事情,这个是在统计分析的时候一个很常见的业务吧,就是UPDATE_TIME
可以做这个事情,包括两个库做数据交换的时候,都是通过时间戳去判断,这个东西是不是最近的,或者像你说的,用VERSION
去判断,开始改了,就有一张级联的一张表,VERSION是1.0版本,然后这边并发的来了,那我就2.0,3.0,VERSION变更了,这个数据就不能
弄了,还有一些其他的方案,除了数据规则,添加你认为必要的扩展资料,可能就是这个事
(5)预留字段:
就是我刚才说的预留字段,就是关联其他业务的,就是在我去做数据库表结构设计的时候,就是我单纯从数据库表结构设计的时候,
那我就可能会考虑这些问题,然后看我的业务对应哪几种方案,当然可能还会有很多的方案,这个还是具体的业务具体的分析,
你看看怎么去做比较合适,包括还可以有一些数据的冗余,这一块也加上吧,这些可能都是一些解决方案
(6)做一些合理的冗余:
这是做什么事呢,ORACLE其实很早就提出冗余这个事,然后MSYQL近几年才出来这个事,我觉得其实这个很正常,就比如说有一个应用
场景,就是你现在做一个水平切割,就是做水平分表分库,无论说你是把一张表的几个字段,拆分成几张小表,把这个表的数据水平的
去切分,成两张表,不管怎么样也好,分表分库也好,或者是垂直拆分也好,你都要应该理想化的去看待这个事情,你可以合理的去做
一些冗余,那比如说我举个例子,比如说我有一个业务,这个业务能够单独的去独立开来,一张库,这张库可能有四五张表,然后对着
四五张表简单的join,完成了我们所说的一个事,然后呢,这是一块业务,说的是一个什么业务呢,刚才我们说的电商系统,又回到了
那个电商了,这是一个购物车或者商品的业务,电商里面其实还有一块,支付业务,有的人支付是自己做的,有的是调第三方接口什么的,
这就不说了,这一块总之是一个独立的业务,分一块独立的业务,比如刚才的供应商吧,那我问你供应商和这个商品,他既然是两个系统,
整体一个大系统有一个名字,一个小系统独立的起个名字,然后这个系统里面有几张表,那你一定会发现这个供应商里面,肯定会涉及到
数据,其中有一张表我可以做什么事呢,我这张供应商这张表里面,我可以有自己的字段,而且我可以把商品里要查询的字段呢,
比如商品表我要加3字段,这张表需要加2个字段,这张表我需要加2个字段,那么我这7个字段就可以合理的去冗余到这张表里,能理解我
说的意思吧,这是避免一个什么问题,避免两个数据库之间要进行一个join,要进行分布式事务的问题,那以后我们可以做什么事啊,
我单纯一个数据源连一个数据库,我通过一张表就可以返回数据,我没必要把这一张表的数据再抽出来,再查询给我,那这个就看你怎么去
做了,这几个字段在不同的表中,你这样做就很麻烦,很累,就是相对于这种合理的冗余,也是我们采取数据库设计的一种手段,能理解我说的
意思吧,反正就是说,设计这个事情,是很不好把控的,没有说固定来讲设计就好,还是根据不同的需求去设计表结构,当然,大方向的原原则,
我在这里可能就总结了几点了,这可能是我工作常用的几招,大体上就是这样





















 5673
5673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









