







之前经常听到散列表/哈希表这么个概念,但是一直没静下来好好研究这个东西。现在借着读《算法导论》这个机会,好好整理一下有关散列表的知识。留待以后复习使用。形象地来理解,散列表就相当于是一个字典。我们使用字典的时候通过拼音找到想要的字,那些读音相近的字都集合在一起,这样查找起来就很方便。或者,你可以把它理解成在手机通讯录,如果我现在想要找一个人的电话,一般是直接键入这个人的姓的字母,比如林**,我键入L,那么就会出现一堆林某某供我选择,当然这个第一个得到的林某某不一定是我想要的,因此还要解决“冲突”问题。下面,我们系统地整理一下散列表的相关知识。
散列表,也叫哈希表,是根据关键字(Key value)而直接访问在内存存储位置的数据结构。也就是说,它通过把键值通过一个函数的计算,映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
散列表是普通数组概念的推广。对于普通数组可以利用直接寻址法,在O(1)的时间内访问数组中的任意位置。
为表示动态集合,我们用一个数组,或称为直接寻址法(direct-address table),记为T[0 .. m-1],其中每个位置,或称为槽(slot),对应全域U中的一个关键字。
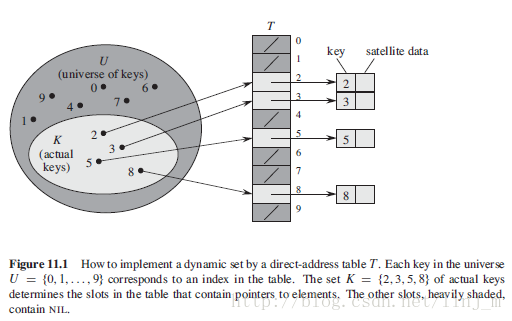
但是呢,直接寻址技术有个大缺点,那就是当全域U很大时,要存储一张大小为U的表T并不太明智,甚至是不可能,而且实际中利用到的关键字集合K相对于U可能很小。所以,我们需要设计一张表——散列表。
在直接寻址方式中,具有关键字k的元素被存放在slot k中;在散列方式中,该元素存放在槽h(k)中,即利用散列函数h,由关键字k计算出槽的位置。
这里,函数h将关键字的全域U映射到散列表T[0 .. m-1]的槽上:
h: U -> {0,1,..,m-1}
这里散列表的大小m一般比|U|小的多。我们可以说一个具有关键字k的元素被散列到槽h(k)上,也可以说h(k)是关键字k的散列值。如下图所示:
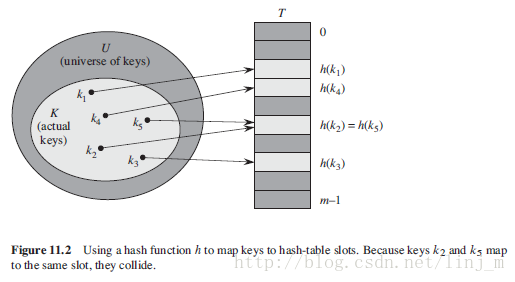
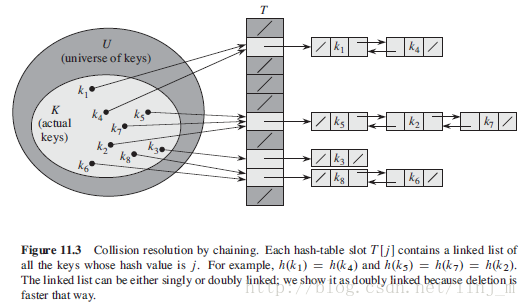
散列函数缩小了数组下标的范围,即缩小了数组的大小,使其|U|减小为m。但是,这么一减小,就会出现一个问题:两个关键字可能映射到同一个槽中,从而出现“冲突”。而这个问题,是散列表必须解决的。下面,我们介绍一个比较直接想到的方法——链接法解决冲突
在链接法中,把映射到同一个槽中的所有元素都放在一个链表中,如下图所示。
散列函数
一个好的散列函数满足简单均匀散列假设:每个关键字都被等可能地散列到m个槽位中的任何一个,并与其他关键字已散列到哪个槽位无关。但在实际中,这一假设很难实现。我们更多地是利用启发式方法来构建性能好的散列函数。设计过程中,可以利用关键字分布的有用信息。例如,在一个编译器的符号表中,关键字都是字符串,表示程序中的标识符。一些相近的符号经常会出现在同一个程序中,如pt和pts。好的散列函数应该能将这些相近符号散列到相同槽中的可能性最小化。
一种好的方法导出的散列值,在某种程度上应独立于数据可能存在的任何模式。
将关键字转换为自然数
多数散列函数都假定关键字的全域为自然数集N。因此,若所给关键字不是自然数,就需要找到一种方法来将他们转换为自然数。例如,一个字符串可以被转换为适当的基数符号表示的整数。这样,就可以把pt通过Ascii码转换为(112,116),然后以128为基数来表示,pt即为(112*128)+116=14 452。
除法散列法
通过取k除以m的余数,将关键字k映射到m个槽中的某一个上,即散列函数为:
h(k) = k mod m
不过在应用除法散列法时要避免选择m的某些值。例如,m不应为2的幂,因为如果m=2^p,则h(k)就是k的p个最低有效位数字。
一个不太接近2的整数幂的素数,常常是m的一个较好的选择。
乘法散列法
构造散列函数的乘法散列法包括两个步骤。
- 第一步,用关键字k乘上常数A(0<A<1),并提取kA的小数部分。
- 第二步,用m乘以这个值,再向下取整。
总之,散列函数为:
h(k) = [m(kA mod 1)]
这里"kA mod 1"是取kA的小数部分,即kA-[kA]。[]表示向下取整。
乘法散列法的一个优点是对m的选择不是特别关键,一个选择它为2的某个幂次。下面图介绍了一种计算散列值的方法。

全域散列法
——随机地选择散列函数,使之独立于要存储的关键字
如果让一个恶意的对手来针对某个特定的散列函数选择要散列的关键字,那么他会将n个关键字全部散列到同一个槽中,使得平均的检索时间为O(n)。任何一个特定的散列函数都可能出现这种令人恐怖的最坏情况。唯一有效的改进方法是随机地选择散列函数,使之独立于要存储的关键字,即采用全域散列法。
全域散列法在执行开始时,就从一组精心设计的函数中,随机地选择一个作为散列函数。就像在快速排序中一样,随机化保证了没有一种输入会始终导致最坏情况性能。因为随机地选择散列函数,算法在每一次执行时都会有所不同,甚至对于相同的输入都会如此。这样就可以确保对于任何输入,算法都具有较好的平均情况性能。
设H为一组有限散列函数,它将给定的关键字全域U映射到{0,1,…,m-1}中。这样的一个函数组称为全域的,如果对每一对不同的关键字k,l,满足h(k)=h(l)的散列函数h的个数至多为|H|/m。换句话说,如果从H中随机地选择一个散列函数,当关键字k!=l时,两者发生冲突的概率不大于1/m,这也正好是从集合{0,1,2,...,m-1}中独立地随机选择h(k)和h(l)时发生冲突的概念。
开放寻址法
线性探查
给定一个普通的散列函数h‘:U->{0 1 2 ...m-1},称之为辅助散列函数,线性探查方法采用的散列函数为:
h(k,i)=(h'(k)+i)mod m, i=0,1,2,...m-1
给定一个关键字k,首先探查槽T[h'(k)],即由辅助函数所给出的槽位。再探查槽T[h'(k)+1],以此类推,直到槽T[m-1]。然后又绕道T[0]、T[1]、……,直到T[h'(k)-1]。在线性探查中,初始探查位置决定了整个序列,故只有m种不同的探查序列。
二次探查
二次探查采用如下形式的散列函数:
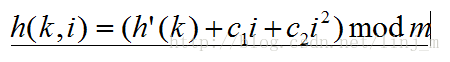
这种方法初次探查位置为T[h'(k)],后续的探查位置要加上一个偏移量,该偏移量以二次的方式依赖于探查序号i。
双重探查
双重探查是用于开放寻址法的最好方法之一,因为它所产生的排列具有随机选择排列的许多特性。散列函数如下:
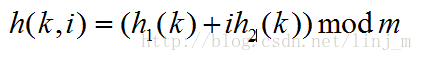
其中h1和h2均为辅助散列函数。














 4275
4275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









