




一、索引概述
索引是数据库中一种可选的数据结构,她通常与表或簇相关。用户可以在表的一列或数列上建立索引,以提高在此表上执行 SQL 语句的性能。正确地使用索引能够显著的减少磁盘 I/O。
用户可以为一个表创建多个索引,只要不同索引使用的列或列的组合(combination of columns)不同即可。
例如,下列语句中指定的列组合是有效的:
CREATE INDEX employees_idx1 ON employees (last_name, job_id);
CREATE INDEX employees_idx2 ON employees (job_id, last_name);
无论索引是否存在都无需对已有的 SQL 语句进行修改。索引只是提供了一种快速访问数据的路径,因此她只会影响查询的执行速度。当给出一个已经被索引的数据值后,就可以通过索引直接地定位到包含此值的所有数据行。
索引在逻辑上和物理上都与其基表(base table)是相互独立的。用户可以随时创建(create)或移除(drop)一个索引,而不会影响其基表或基表上的其他索引。当用户移除一个索引时,所有的应用程序仍然能够继续工作,但是数据访问速度有可能会降低。作为一种独立的数据结构,索引需要占用存储空间。
当索引被创建后,对其的维护与使用都是 Oracle 自动完成的。当索引所依赖的数据发生插入,更新,删除等操作时,Oracle 会自动地将这些数据变化反映到相关的索引中,无需用户的额外操作。
即便索引的基表中插入新的数据,对被索引数据的查询性能基本上能够保持稳定不变。但是,如果在一个表上建立了过多的索引,将降低其插入,更新,及删除的性能。因为 Oracle 必须同时修改与此表相关的索引信息。
优化器可以使用已有的索引来建立(build)新的索引。这将加快新索引的建立速度。
唯一索引、非唯一索引、组合索引
unique index OR nounique index: 索引可以是唯一(unique)的或非唯一(nonunique)的。在一个表上建立唯一索引(unique index)能够保证此表的索引列(一列或多列)不存在重复值。而非唯一索引(nonunique index)并不对索引列值进行这样的限制。
Oracle 建议使用 CREATE UNIQUE INDEX 语句显式地创建唯一索引(unique index)。通过主键(primary key)或唯一约束(unique constraint)来创建唯一索引不能保证创建新的索引,而且用这些方式创建的索引不能保证为唯一索引。
红色部分字意思也许不是很好理解,下面以实验来说明:create table test_a as select * from dba_objects;
create index test_a_idx_1 on test_a (object_id,owner);
--查看刚刚建立的索引test_a_idx_1
INDEX_NAME INDEX_TYPE TABLE_OWNER UNIQUENESS
TEST_A_IDX_1 NORMAL SCOTT NONUNIQUE
索引test_a_idx_1 为一个组合索引,非唯一索引。
目前表test_a上还没有指定主键,现在,我们指定object_id为主键。
alter table test_a
add constraint test_a_pk primary key(object_id);
现在查看表约束情况:
CONSTRAINT_NAME CONSTRAINT_TYPE TABLE_NAME INDEX_NAME
TEST_A_PK P TEST_A TEST_A_IDX_1
按理,在表test_a上的object_id创建了主键,会创建一个以主键名相同的唯一索引,但是此处,却没有。因为,此时,主键列上(object_id)已经存在一个索引(若为复合索引,object_id必须为引导列)。此时主键会使用此索引,但是该索引却是为NONUNIQUE。
composite index: 指创建在一个表的多列上的索引。复合索引内的列可以任意排列,她们在数据表中也无需相邻。
如果一个 SELECT 语句的 WHERE 子句中引用了复合索引(composite index)的全部列(all of the column)或自首列开始且连续的部分列(leading portion of the column),将有助于提高此查询的性能。因此,索引定义中列的顺序是很重要的。大体上说,经常访问的列(most commonly accessed)或选择性较大的列(most selective)应该放在前面。
一个表上没有单独的可以唯一标识一行的列,就可以使用多列组合来取得唯一标识。使用组合索引。
一个常规的(regular)复合索引(composite index)不能超过 32 列,而位图索引(bitmap index)不能超过 30 列。索引中一个键值(key value)的总长度大致上不应超过一个数据块(data block)总可用空间的一半。
二、索引和空值
对于一个数据表的两行或多行,如果其索引列(key column)中全部非空(non-NULL)的值完全相同(identical),那么在索引中这些行将被认为是相同的;反之,在索引中这些行将被认为是不同的。因此使用UNIQUE 索引可以避免将包含 NULL 的行视为相同的。以上讨论并不包括索引列的列值(column value)全部为NULL 的情况。
Oracle 不会将索引列(key column)全部为 NULL 的数据行加入到索引中。不过位图索引(bitmap index)是个例外,簇键(cluster key)的列值(column value)全部为NULL 时也是例外。
测试:
create table test_b(id number,no number);
create unique index test_b_uniq_idx_a on test_b (id,no);
insert into test_b
values(1,null);
insert into test_b
values(null,1);
insert into test_b
values(1,1);
insert into test_b
values(null,null);
--分析索引,查看有多少个leaf block。
analyze index test_b_uniq_idx_a validate structure;
select name,lf_rows from index_stats;
NAME LF_ROWS
1 TEST_B_UNIQ_IDX_A 3
--只有3个,全为空的哪一行,没有被索引。
--再插入一行全空值,分析索引。
insert into test_b
values(null,null);
analyze index test_b_uniq_idx_a validate structure;
select name,lf_rows from index_stats;
NAME LF_ROWS
1 TEST_B_UNIQ_IDX_A 3
三、索引的存储
当用户创建索引时,Oracle 会自动地在表空间(tablespace)中创建索引段(index segment)来存储索引的数据。用户可以通过以下方式控制索引段的空间分配和使用:
- 设置索引段的存储参数(storage parameter)来控制如何为此索引段分配数据扩展(extent)
- 为索引段设置 PCTFREE 参数,来控制组成数据扩展的各个数据块(data block)的可用空间情况。
3、1 索引的块格式
一个数据块(data block)内可用于存储索引数据的空间等于数据块容量减去数据块管理开销(overhead),索引条目管理开销(entry overhead),rowid,及记录每个索引值长度的 1 字节(byte)。
当用户创建索引时,Oracle 取得所有被索引列的数据并进行排序,之后将排序后索引值和与此值相对应的 rowid 按照从下到上的顺序加载到索引中。
例如,以下语句:
CREATE INDEX employees_last_name ON employees(last_name);Oracle 先将 employees 表按 last_name 列排序,再将排序后的 列及相应的 rowid 按从下到上的顺序加载到索引中。
3、2 索引的内部结构
Oracle 使用平衡树(B-tree)存储索引以便提升数据访问速度。当不使用索引时,用户必须对数据进行顺序扫描(sequential scan)来查找指定的值。如果有 n 行数据,那么平均需要扫描的行为 n/2。因此当数据量增长时,这种方法的开销将显著增长。
如果将一个已排序的值列(list of the values)划分为多个区间(range),每个区间的末尾包含指向下个区间的指针(pointer),而搜索树(search tree)中则保存指向每个区间的指针。此时在 n 行数据中查询一个值所需的时间为 log(n)。
平衡树索引(B-tree index)的结构:
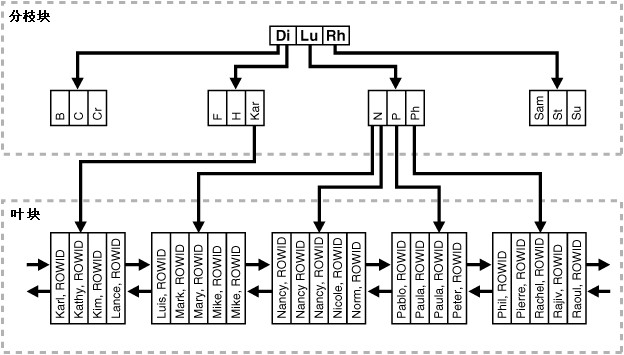
在一个平衡树索引(B-tree index)中,最底层的索引块(叶块(leaf block))存储了被索引的数据值,以及对应的 rowid。叶块之间以双向链表的形式相互连接。位于叶块之上的索引块被称为分支块(branch block),分枝块中包含了指向下层索引块的指针。如果被索引的列存储的是字符数据(character data),那么索引值为这些字符数据在当前数据库字符集(database character set)中的二进制值(binary value)。
四、索引类型
- B-tree indexes 标准的所有类型。在主键或者搞选择性列上有卓越的性能,B-树索引分为以下几个类型
- Index-organized tables --索引组织表
- Reverse key indexes --反向键索引
- Descending indexes --降序索引
- B-tree cluster indexes --B-树集群索引
- Bitmap and bitmap join indexes
- Function-based indexes
- Application domain indexes
对于唯一索引(unique index),每个索引值对应着唯一的一个 rowid。对于非唯一索引(nonunique index),每个索引值对应着多个已排序的 rowid。因此在非唯一索引中,索引数据是按照索引键(index key)及 rowid 共同排序的。键值(key value)全部为NULL 的行不会被索引,只有簇索引(cluster index)例外。在数据表中,如果两个数据行的全部键值都为 NULL,也不会与唯一索引相冲突。
B-Tree Indexes
--此部分摘自oracle conceptsB-树索引内部结构:
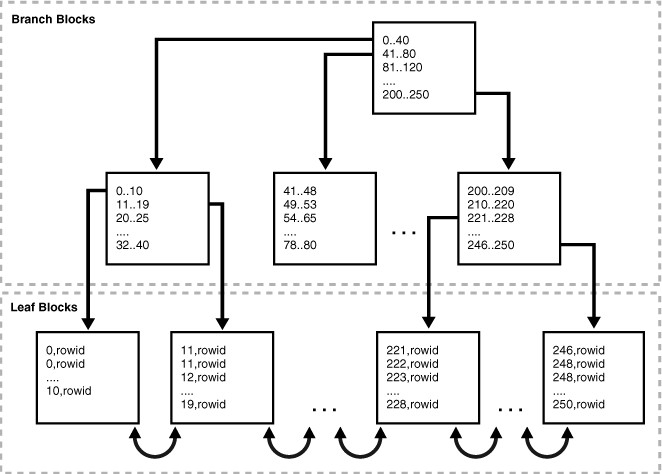
Branch Blocks and Leaf Blocks
A B-tree index has two types of blocks:branch blocks for searching and leaf blocks that store values. The upper-level branch blocks of a B-tree index contain index data that points to lower-level index blocks. the root branch block has an entry 0-40, which points to the leftmost block in the next branch level. This branch block contains entries such as0-10 and 11-19. Each of these entries points to a leaf block that contains key values that fall in the range.
A B-tree index is balanced because all leaf blocks automatically stay at the same depth. Thus, retrieval of any record from anywhere in the index takes approximately the same amount of time. Theheight of the index is the number of blocks required to go from the root block to a leaf block. The branch level is the height minus 1. in up Figure, the index has a height of 3 and a branch level of 2.
Branch blocks store the minimum key prefix needed to make a branching decision between two keys. This technique enables the database to fit as much data as possible on each branch block. The branch blocks contain a pointer to the child block containing the key. The number of keys and pointers is limited by the block size.
The leaf blocks contain every indexed data value and a corresponding rowid used to locate the actual row. Each entry is sorted by (key, rowid). Within a leaf block, a key and rowid is linked to its left and right sibling entries. The leaf blocks themselves are also doubly linked. In Figure 3-1 the leftmost leaf block (0-10) is linked to the second leaf block (11-19).
Reverse Key Indexes --反向键索引
本质与B-树索引一致,列的顺序被完全保存,只是字节是反向的。优点是
Ascending and Descending Indexes --升序、降序索引
In an ascending index, Oracle Database stores data in ascending order. By default, character data is ordered by the binary values contained in each byte of the value, numeric data from smallest to largest number, and date from earliest to latest value.
For an example of an ascending index, consider the following SQL statement:
CREATE INDEX emp_deptid_ix ON hr.employees(department_id); --默认ascending
Oracle Database sorts the hr.employees table on the department_id column. It loads the ascending index with the department_id and corresponding rowid values in ascending order, starting with 0. When it uses the index, Oracle Database searches the sorted department_id values and uses the associated rowids to locate rows having the requested department_id value.
By specifying the DESC keyword in the CREATE INDEX statement, you can create a descending index. In this case, the index stores data on a specified column or columns in descending order. If the index in Figure 3-1 on the employees.department_id column were descending, then the leaf blocking containing 250 would be on the left side of the tree and block with 0 on the right. The default search through a descending index is from highest to lowest value.
Descending indexes are useful when a query sorts some columns ascending and others descending. For an example, assume that you create a composite index on the last_name and department_id columns as follows:
CREATE INDEX emp_name_dpt_ix ON hr.employees(last_name ASC, department_id DESC);
If a user queries hr.employees for last names in ascending order (A to Z) and department IDs in descending order (high to low), then the database can use this index to retrieve the data and avoid the extra step of sorting it.
Bitmap Indexes
位图索引结构
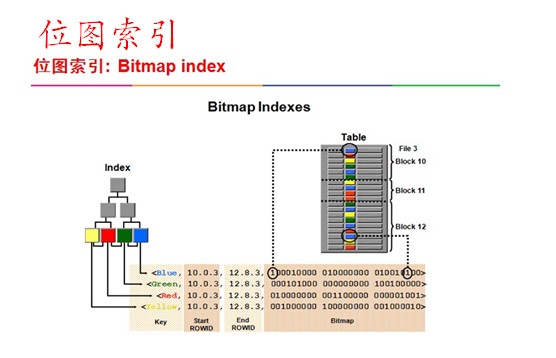
位图索为每个唯一键创建一个位图。然后把与键值所关联的ROWID保存为位图,最多可指定30列。
|
| ||||
| 客户编号 | 婚姻状况 | 地区 | 性别 | 收入水平 |
|
| ||||
| 101 | 单身 | 东部 | 男性 | 一级 |
| 102 | 已婚 | 中部 | 女性 | 四级 |
| 103 | 已婚 | 西部 | 女性 | 二级 |
| 104 | 离异 | 西部 | 男性 | 四级 |
| 105 | 单身 | 中部 | 女性 | 二级 |
| 106 | 已婚 | 中部 | 女性 | 三级 |
婚姻状况,地区,性别,和收入水平都是小基数(low-cardinality)的列。婚姻状况及地区有 3 种可能值,性别有两种,收入水平有 4 种。因此这 4 列上均适合创建位图索引(bitmap index)。而客户编号列上不应创建位图索引,因为此列基数很大。在此列上创建平衡树索引(B-tree index)的存储和查询效率会较高。
|
| ||
| 地区='东部' | 地区='中部' | 地区='西部' |
|
| ||
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 0 | 1 | 0 |
|
| ||
使用位图索引(bitmap index)处理此查询时,通过布尔运算(Boolean operation)很容易得到一个位图结果集(resulting bitmap)
比如 查询:住在中部或西部地区的已婚客户有多少?
SELECT COUNT(*) FROM CUSTOMER
WHERE MARITAL_STATUS = 'married' AND REGION IN ('central','west');
使用位图索引(bitmap index)处理此查询时,通过布尔运算(Boolean operation)很容易得到一个位图结果集(resulting bitmap)

位图索引和空值
与其他大多数索引不同,位图索引(bitmap index)可以包含键值(key value)为 NULL 的行。将键值为空的行进行索引对有些 SQL 语句是有用处的,例如包含 COUNT 聚合函数的查询。
Bitmap indexes are primarily designed for ata warehousing or environments in which queries reference many columns in an ad hoc fashion. Situations that may call for a bitmap index include:
-
The indexed columns have low cardinality, that is, the number of distinct values is small compared to the number of table rows.
-
The indexed table is either read-only or not subject to significant modification by DML statements.
If the indexed column in a single row is updated, then the database locks the index key entry (for example, M or F) and not the individual bit mapped to the updated row. Because a key points to many rows, DML on indexed data typically locks all of these rows. For this reason, bitmap indexes are not appropriate for many OLTP applications.
实验:
创建test_c,并在id列上 建立一个位图索引。
create table test_c (id number,name varchar2(10));
create bitmap index test_c_bm_idx_1 on test_c(id);
--向表中插入值,不要提交
insert into test_c values (1,'a');
然后 打开外一个连接,也插入值
insert into test_c values (1,'b');
这时,会发现插入等待
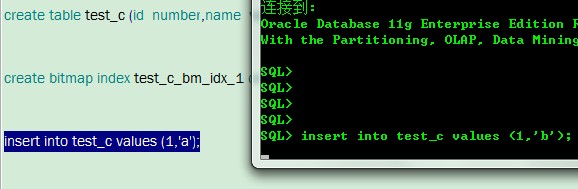
因为在表的ID列上有位图索引,会为id列每一个唯一的值建立一个位图。两次插入的值,id为1,属于同一个位图。然后在第一次插入操作未提交的时候,索引将id为1的位图锁住,我们再次插入id为1的数据,就无法更新该位图,导致锁住。此时我们测试其他id,则不会出现锁住的情况
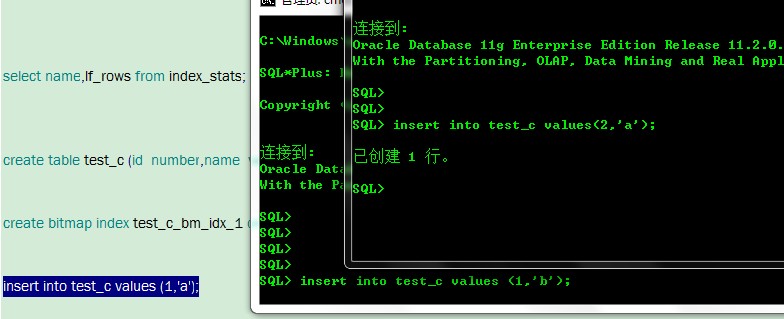
要打破这种锁定的局面,只需要提交第一个插入值的操作,第二个操作将自动成功。
因此,位图索引不适合在OLTP中运用。适用于基数低数量大的表,而且具有叫少的更新表的任务。
Function-Based Indexes --函数索引
预先计算给定的函数,并在索引中存储结果。当where子句中包含函数事,函数索引是较好的选择。
exp
CREATE INDEX emp_fname_uppercase_idx ON employees ( UPPER(first_name) );
SELECT * FROM employees WHERE UPPER(first_name) = 'AUDREY';


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









