









环境
- linux
- python 3.6
- tensorflow 1.12.0
文件准备工作
- 下载bert源代码 : https://github.com/google-research/bert
- 下载bert的预训练模型:BERT-Base, Uncased
- 12-layer, 768-hidden, 12-heads, 110M parameters
数据准备工作
建立一个$SQUAD_DIR文件夹,把下载好的文件放到文件夹下。
编码
在bert文件夹下的run_squad.py中comment掉以下几行
if (len(qa["answers"]) != 1) and (not is_impossible):
raise ValueError(
"For training, each question should have exactly 1 answer.")
编写运行脚本
在GPU服务器上,你可以这么运行BERT_BASE:
新建一个运行脚本文件名为“run.sh”,将文件内容编辑为:
export SQUAD_DIR=自己建的$SQUAD_DIR路径
export BERT_BASE_DIR=预训练模型所在路径
python run_squad.py \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--do_train=True \
--train_file=$SQUAD_DIR/train-v2.0.json \
--do_predict=True \
--predict_file=$SQUAD_DIR/dev-v2.0.json \
--train_batch_size=12 \
--learning_rate=3e-5 \
--num_train_epochs=2.0 \
--max_seq_length=328 \
--doc_stride=128 \
--output_dir=/tmp/squad_base \
--version_2_with_negative=True \
--null_score_diff_threshold=$THRESH
- $THRESH取-1到-5之间的值
- Google 设定的
max_seq_length参数的default值是328,因为我的训练文本比较长,这里我修改成了512。
运行脚本
chmod +x run.sh
./run.sh
- chmod +x 的意思就是给文件执行权限
- 运行的时间可能会有点久,视配置而定。运行结束后,会看到以下结果。
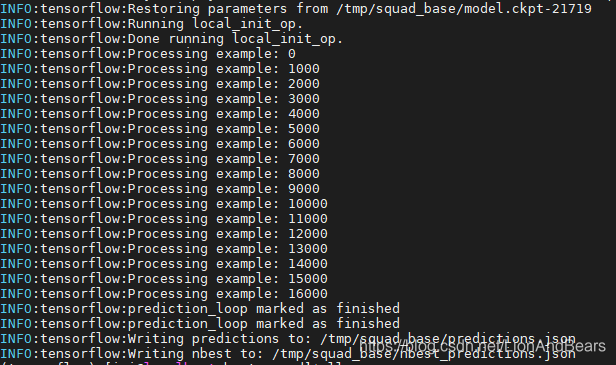
- 生成的结果储存在
/tmp/squad_base/路径下:
调参/预测
- 流程:
- 在bert文件夹里新建一个
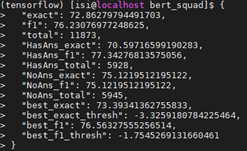
/squad/文件夹,把/tmp/squad_base/路径下的predictions.json和null_odds.json放到/squad/里。 - 使用以下指令给 dev set做预测&给$THRESH调参
python $SQUAD_DIR/evaluate-v2.0.py $SQUAD_DIR/dev-v2.0.json ./squad/predictions.json --na-prob-file ./squad/null_odds.json
- 效果(THRESH=-1):
踩过的坑
-
问题:运行
run.sh报错:ValueError: For training, each question should have exactly 1 answer.(tensorflow) [isi@localhost bert_squad]$ ./run.sh Traceback (most recent call last): File "run_squad.py", line 1282, in <module> tf.app.run() File "/u01/isi/anaconda3/envs/tensorflow/lib/python3.6/site-packages/tensorflow/python/platform/app.py", line 125, in run _sys.exit(main(argv)) File "run_squad.py", line 1158, in main input_file=FLAGS.train_file, is_training=True) File "run_squad.py", line 267, in read_squad_examples "For training, each question should have exactly 1 answer.") ValueError: For training, each question should have exactly 1 answer.解决方法:
打开run_squad.py,找到265-267行,comment掉以下代码。# if (len(qa["answers"]) != 1) and (not is_impossible): # raise ValueError( # "For training, each question should have exactly 1 answer.") -
ResourceExhaustedError 没内存了
ResourceExhaustedError (see above for traceback): OOM when allocating tensor with shape[12,12,512,512] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc [[node bert/encoder/layer_9/attention/self/Softmax (defined at /u01/isi/jingyiwang/bert_squad/modeling.py:720) = Softmax[T=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:GPU:0"](bert/encoder/layer_9/attention/self/add)]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. [[{{node truediv/_4029}} = _Recv[client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name="edge_3857_truediv", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]()]] Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.解决方法:
运行过程中遇到内存耗尽造成的花式报错,最后调用了4个GPU成功了。调用GPU只需要在run.sh开头添加export CUDA_VISIBLE_DEVICES=1,2,3,4(GPU编号) -
使用这段脚本
python $SQUAD_DIR/evaluate-v2.0.py $SQUAD_DIR/dev-v2.0.json ./squad/predictions.json --na-prob-file ./squad/null_odds.json给预测null和非空答案的阈值调参的时候,遇到以下错误:Traceback (most recent call last): File "squad_dir/evaluate-v2.0.py", line 276, in <module> main() File "squad_dir/evaluate-v2.0.py", line 236, in main preds = json.load(f) File "/anaconda3/envs/tensorflow/lib/python3.6/json/__init__.py", line 299, in load parse_constant=parse_constant, object_pairs_hook=object_pairs_hook, **kw) File "/anaconda3/envs/tensorflow/lib/python3.6/json/__init__.py", line 354, in loads return _default_decoder.decode(s) File "/anaconda3/envs/tensorflow/lib/python3.6/json/decoder.py", line 339, in decode obj, end = self.raw_decode(s, idx=_w(s, 0).end()) File "/anaconda3/envs/tensorflow/lib/python3.6/json/decoder.py", line 357, in raw_decode raise JSONDecodeError("Expecting value", s, err.value) from None json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)原因:
忘记删除之间错误版本的prediction.json文件
解决方法:
把代码跑通生成的那版prediction.json文件放在squad文件夹里














 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









