






点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
背景
实现一个函数 实现一个重试功能,当异步任务失败时,等待N秒后会自动重试直到成功或达到最大重试次数。
const query = () => {
return fetch(
'https://api.juejin.cn/user_api/v1/user/dynamic?user_id=3649990025815853&cursor=0&aid=2608&uuid=7387740407814587904&spider=0',
);
};代码实现
/**
*
* @param task 返回一个promise的异步任务
* @param count 需要重试的次数
* @param time 每次重试间隔多久
* @returns 返回一个新promise
*/
const retry = (task, count = 5, time = 3 * 1000) => {
return new Promise((_res, _rej) => {
let doneCount = 0;
const run = () => {
task()
.then(data => {
_res(data);
})
.catch(err => {
doneCount++;
if (doneCount > count) {
_rej(err);
} else {
setTimeout(run, time);
}
});
};
run();
});
};
retry(query);代码分析
query函数返回一个fetch请求的结果,这个结果是一个Promise。retry函数创建并返回一个新的Promise,内部使用递归和setTimeout来实现重试逻辑。每次
task执行失败时,catch块会捕获错误,并增加doneCount计数器。如果
doneCount超过了count,retry函数会拒绝Promise并传递错误。如果没有超过重试次数,
setTimeout会延迟执行run函数,从而实现重试。
知识点
fetch API:
用于发起网络请求,获取资源。
fetch返回一个Promise对象,可以链式调用.then()和.catch()处理响应和错误;fetch()采用模块化设计,API 分散在多个对象上(Response 对象、Request 对象、Headers 对象);通过数据流(Stream 对象)处理数据,可以分块读取,有利于提高网站性能表现,减少内存占用,对于请求大文件或者网速慢的场景相当有用。
更多关于fetch使用[1] 可以参考这篇文章。
**Promise**:
当前主流的js异步编程方案中 都是基于promise的。promise最大的优点就是统一了异步调用的api,所有异步操作都可以使用相同的模式来处理问题。使用链式调用,避免了回调地狱。promise本质是一个存储回调的容器. 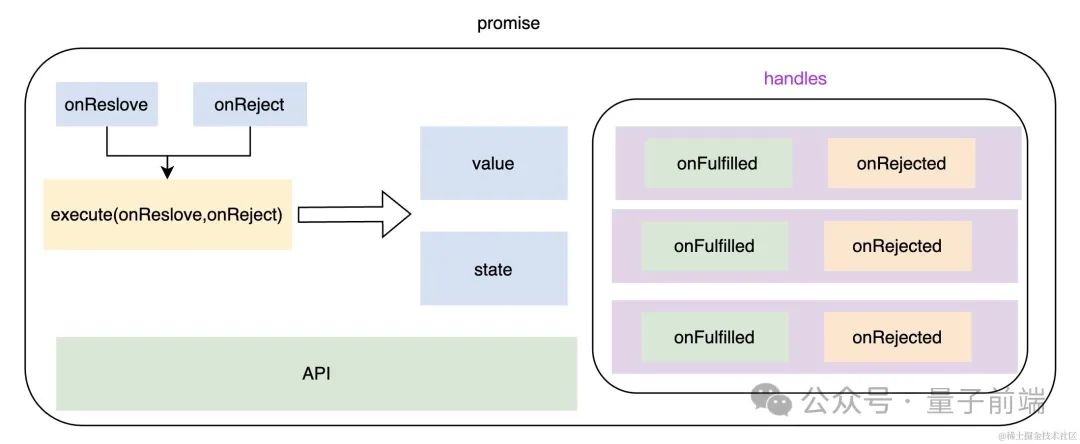 更多关于promise的知识点可以参考这篇文章。promise的本质[2]
更多关于promise的知识点可以参考这篇文章。promise的本质[2]
异步控制流 Asynchronous Control Flow:
"异步控制流"是指在编程中,特别是在涉及异步操作(如I/O操作、网络请求等)的编程中,管理和控制这些操作执行顺序和时间点的方法和策略。例如上面是通过 Promise 和 setTimeout 来控制异步操作的执行顺序。
在JavaScript中,由于其单线程的特性,异步控制流尤为重要,因为它允许程序在等待异步操作完成时继续执行其他代码,从而提高效率和响应性。
异步控制流还包括错误处理机制,确保当异步操作失败时,程序能够适当地响应并继续执行。
在异步控制流中,可以控制多个异步操作的并发执行,以及它们之间的同步关系,例如,只有在前一个异步操作完成后,才开始下一个操作。
合理的异步控制流可以减少等待时间,提高程序性能,特别是在I/O密集型或网络请求密集型的应用中。
递归:
run 函数通过递归调用自身来实现重试逻辑。每次请求失败后,会等待指定的时间间隔,然后再次尝试执行 task。
在JavaScript中,递归是指一个函数在其内部直接或间接地调用自身。递归通常用于解决一些具有自相似性的问题,即问题可以通过缩小或分解为相似的子问题来求解。在递归中,通常有以下两个关键部分:
基本情况(Base case):用于标识问题规模最小时的解决方案。基本情况是直接可解的,不需要递归求解。递归在到达基本情况时停止。
递归规模递减(Recursive case):把问题分解成更小规模的子问题,并调用自身来解决这些子问题。每次递归调用时,问题规模都应该减小,最终收敛到基本情况。
例如:
function fibonacci(n) {
// 基本情况 (n为0或1时,直接返回n)
if (n === 0 || n === 1) {
return n;
}
// 递归规模递减(求解子问题)
else {
return fibonacci(n - 1) + fibonacci(n - 2);
}
}递归在使用时需要格外注意,因为不合适或错误地使用递归可能导致栈溢出(调用栈的大小超过限制)或死循环。为了避免这些问题,请确保问题每次递归调用时都缩小了规模,并且在到达基本情况时停止递归。
闭包:
run 函数是一个闭包,它可以访问其外部作用域的变量,如 doneCount。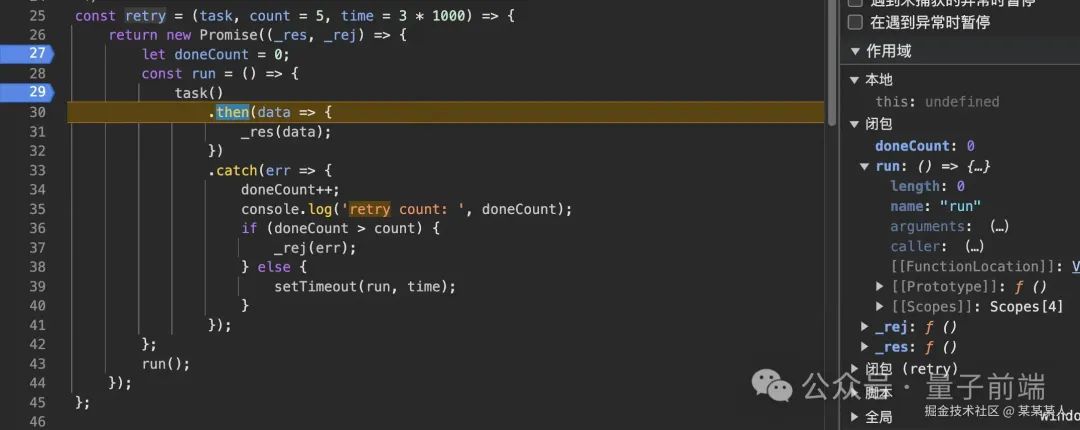
闭包的本质是函数,捕获了其静态词法作用域,从而形成了作用域链。这使得函数能够跨越其定义环境访问外部变量,是对作用域链和内存引用管理的深刻理解。
闭包揭示了 JavaScript 函数作为一等公民的重要特征。函数不仅可以作为值传递,还能保留其定义时的上下文,这为函数式编程提供了强大支持。
通过闭包,我们能够创建私有变量、实现数据封装和模块化,提升代码的安全性和可维护性。因此,掌握闭包是全面理解和高效使用 JavaScript 的关键。
更多关于闭包的知识点 参考这篇文章 js三座大山之函数闭包[3]
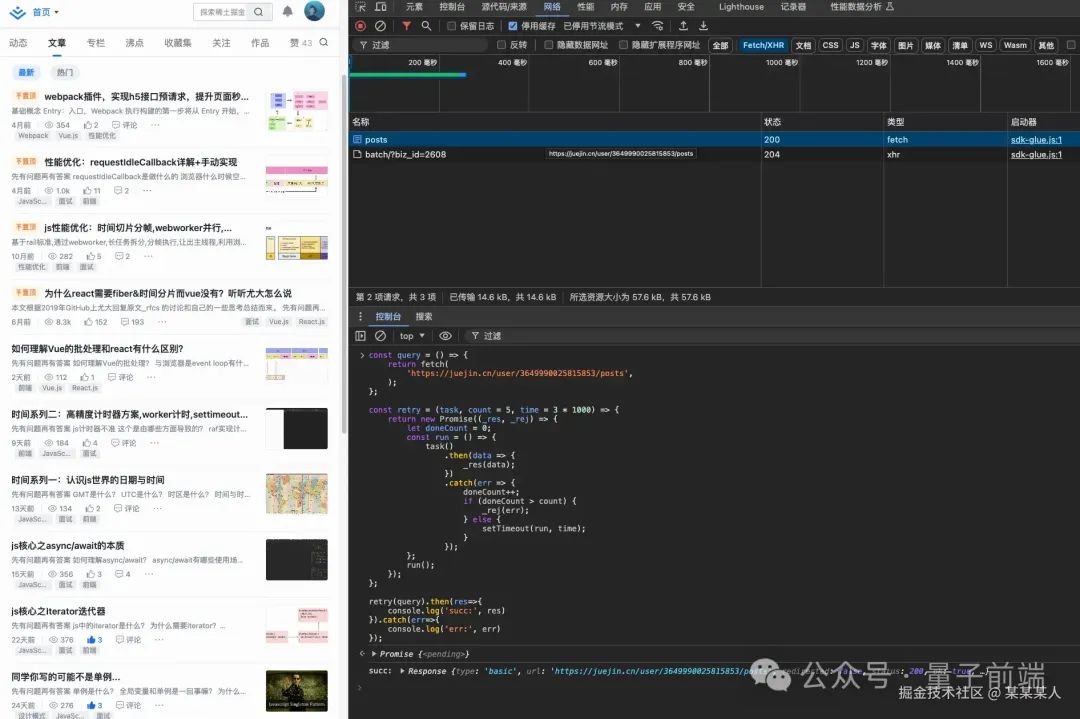
使用示例:
请求成功的case:
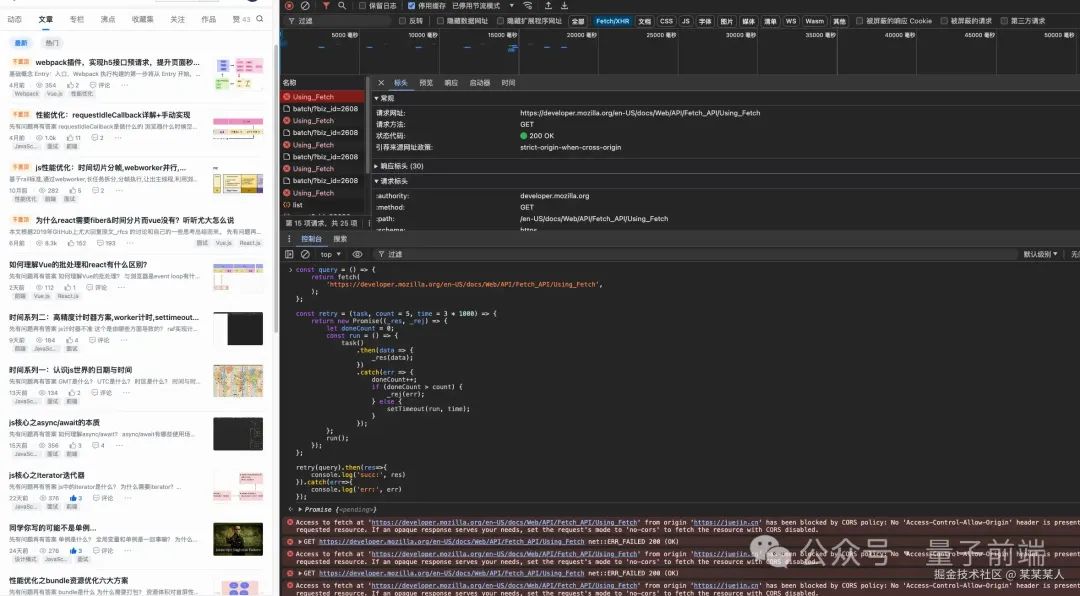
请求失败的case:
第N次成功
let exeCount = 0;
const query2 = () => {
return new Promise((_res, _rej) => {
setTimeout(() => {
++exeCount > 3 ? _res(exeCount) : _rej();
}, 1000);
});
};
retry(query2)
.then(res => {
console.log('succ:', res);
})
.catch(err => {
console.log('err:', err);
});重试了3次后第四次 请求成功 返回最终结果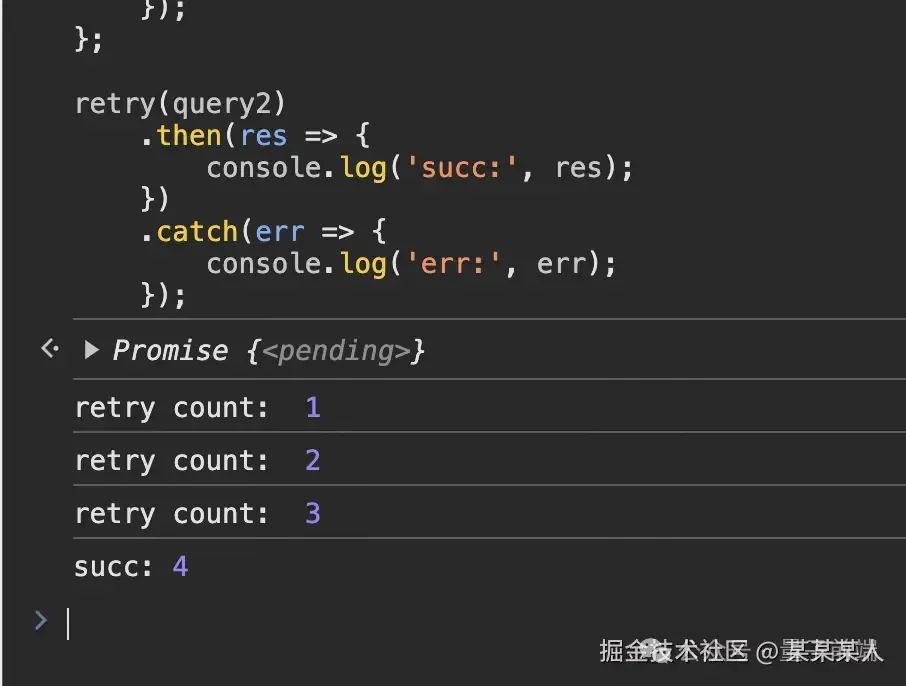
github仓库
源码 retry[4]
更多基于promise的 优化js运行时的解决方案 run-time-opti[5]
本库长期维护更新...
作者:某某某人
原文链接:https://juejin.cn/post/7395623789135265827

往期推荐



最后
欢迎加我微信,拉你进技术群,长期交流学习...
欢迎关注「前端Q」,认真学前端,做个专业的技术人...
点个在看支持我吧
















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









