







背景:在很多业务场景下,我们都需要一个唯一的 ID 来进行一些数据的交互,那么如何生成这个唯一的 ID 呢?
如果在单机的情况下,生成唯一ID,可以利用机器内存的特点,通过内存分配即可。但我们线上的服务部署往往是多机器、多集群的。在这种情况下就要考虑分布式 ID 生成器了。如何确保数据唯一就显得很重要。
1、数据库自增ID
最简单,使用最广泛的场景:单表设置一个自增 ID,我们很多情况下的数据查询、获取都是通过该方式。
但存在较明显的弊端:
1、受限于DB最大连接数,高并发场景下会占用连接数,增加DB压力。而且主从延迟的情况下会出现数据获取不准确的问题。
2、单表数据越来越大, 后期分库分表会存在压力,拓展能力差。
2、UUID
UUID是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。
UUID由以下几部分组成:
1、当前日期时间。
2、时钟序列。
3、全局唯一的IEEE机器识别号,如果有网卡从网卡MAC地址获得,没有网卡以其他方式获得。
UUID目前使用普遍的是微软的GUID,其格式如下:
xxxxxxxx-xxxx- xxxx-xxxxxxxxxxxxxxxx(8-4-4-16),其中每个 x 是 0-9 或 a-f 范围内的一个十六
进制的数字。
示例:b6489592-4726-4d68-a52b-63e2bbddfbf3
1~8位采用系统时间,在系统时间上精确到毫秒级保证时间上的惟一性;
9~16位采用底层的IP地址,在服务器集群中的惟一性;
17~24位采用当前对象的HashCode值,在一个内部对象上的惟一性;
25~32位采用调用方法的一个随机数,在一个对象内的毫秒级的惟一性。复制代码
标准的UUID格式:
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (8-4-4-4-12)
注:关于 java 的 orm 不讨论。
缺点:
1、生成的结果串会比较长。
3、雪花算法
SnowFlake算法生成的唯一 id 是一个64bit大小的整数,它的结构如下图:
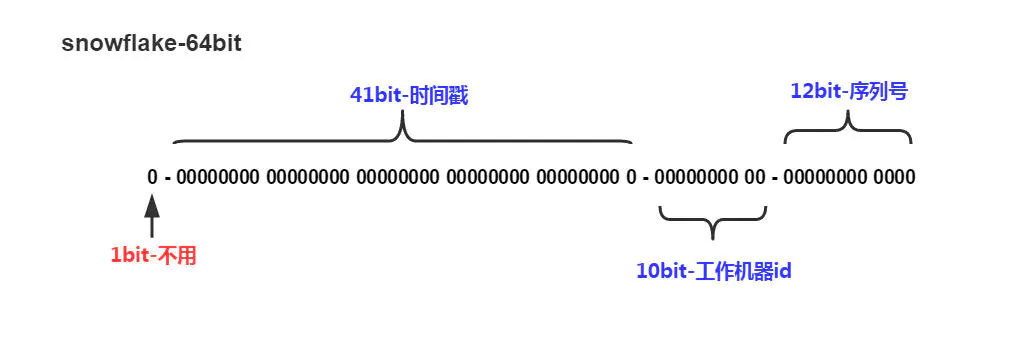
41bit (0, 2^41) 1589206824687 12bit
组成部分如下:
1、1bit 位不用,因为对于long类型,二进制中最高位是符号位,1代表负,0代表正。
2、41bit 时间位,记录的为毫秒级别的时间戳。取值范围为 (0, 2^41) ,举例:
当前毫秒级别时间戳:1589206824687
bit位表示:10111001000000100000110111011011011101111
3、10bit 机器 id (可划分为 5bit 的 datacenterId,5bit 的工作 workerId)
4、12bit 的序列号,用来记录同毫秒内产生的不同 id。
优势:
1、可以按照时间趋势递增
2、中间的机器位可以配合业务灵活的分配到其它位上,也可以借用其它区块的bit位
3、分布式系统内不会存在相同的两个id,因为有datacenterId、workerId来保证
缺点:
1、单机器出现时钟回拨,可能会出现 ID 冲撞。如何解决?可利用拓展位进行回拨记录。
来源:江湖百晓生
https://juejin.cn/post/6844904153894879239


















 2172
2172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









