






本系列介绍的是Lyft在面对越来越多的开发人员和服务时,如何高效扩展开发实践,本文是第三篇。
第一部分:开发和测试环境的历史
第二部分:优化快速本地开发
第三部分:利用覆盖机制在预发环境中扩展服务网格(本文)
第四部分:基于自动验收测试的部署门禁[1]
在之前的文章中,我们描述了为快速迭代本地服务而设计的笔记本电脑开发工作流程。在这篇文章中,将详细介绍安全且隔离的端到端(E2E)测试解决方案:预生产共享环境。在深入研究实现细节之前,我们将简要回顾促使我们构建这一系统的问题。
— 1 —
以前的集成环境
在本系列的第1部分中,我们介绍了在之前用于多服务端到端测试的工具Onebox。Onebox的用户需要租用大型AWS EC2虚拟机来启动100多个服务,以验证修改是否能够跨服务边界工作。这种解决方案为每个开发人员提供了一个沙盒,运行自己版本的Lyft,控制每个服务的版本、数据库内容和运行时配置。
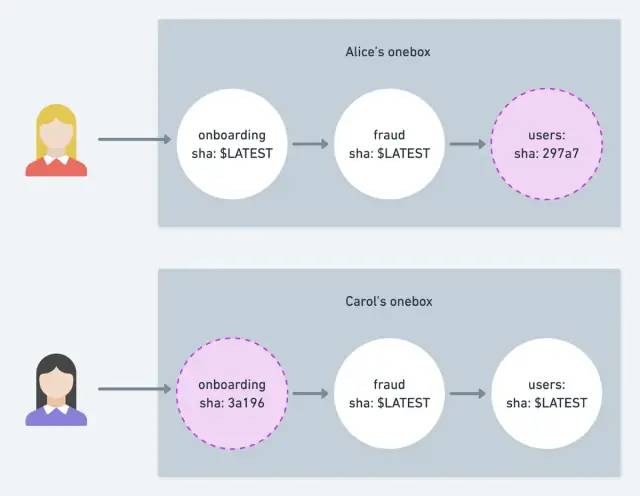
每个开发人员都运行并管理自己独立的Onebox
不幸的是,随着Lyft的工程师和服务数量的增加,Onebox遇到了规模问题(详情见第一篇文章),我们需要找到可持续的替代方案来执行端到端测试。
我们将共享的预发环境视为一种可行的替代品。预发环境与生产环境的相似性让我们充满信心,但我们需要添加缺失的部分,从而提供一个安全的开发环境:隔离。
预发环境(Staging Environment)
预发环境运行与生产环境相同的技术栈,但使用了弹性资源、模拟用户数据以及人造Web流量生成器。预发环境是Lyft一级环境,如果环境变得不稳定,SLO[2]受到影响,随时待命的工程师和开发人员就会提升SEV[3]。
尽管预发环境的可用性和真正的流量增加了端到端的可信度,但如果我们鼓励广泛使用预发环境,就可能会出现一些问题:
预发环境是完全共享的环境,就像生产环境一样,如果有人将一个故障实例部署到预发集群,就会影响到其他(可能是传递性的)依赖该服务的人。
交付新代码的方式是将PR合并到主线,从而触发一个新的部署流水线。为了测试实验性变更如何在端到端环境中工作,需要承受大量的过程负担:编写测试、代码审查、合并,并通过CI/CD进行进展。
这个繁重的过程可能会导致用户使用“逃生口”:将PR分支直接部署到预发环境。当未处理的提交在预发环境下运行时,将进一步放大降低环境稳定性的缺陷问题。
我们的目标是克服这些挑战,使预发环境更适合手工验证端到端工作流。我们想让用户在准备阶段测试他们的代码,而不是被过程所困。如果他们的修订出现问题的话,最小化变更的影响半径。为了实现这一点,我们创建了staging override。
Staging Overrides(预发覆盖)
Staging override是一组用于在预发环境中安全快速的验证用户变更的工具。我们从根本上改变了隔离模型的方法:在共享环境中隔离请求,而不是提供完全隔离的环境。其核心是,我们允许用户重写通过预发环境的请求,并有条件的执行实验代码。大致的工作流程如下:
在预发环境上创建一个不向服务发现注册的新部署,就是我们所说的卸载部署(offloaded deployment),并且保证向这个服务发出请求的其他用户不会被路由到这个(可能被破坏的)实例。
基础架构应该知道如何解释在请求头中嵌入的覆盖信息,从而确保覆盖元数据(override metadata)在整个调用图(request call graph)中传播。
修改每个服务的路由规则,从而可以利用请求头中提供的覆盖信息,根据覆盖元数据指定的规则,路由到对应的卸载部署(offloaded deployment)。
示例场景
假设一个用户想要在端到端场景中测试新版本的onboarding服务。之前基于Onebox,用户可以启动Lyft堆栈的整个副本,并修改相应服务,以验证是否如预期般工作。
如今在预发环境中,用户可以共享环境,但可以替换已卸载的实例,这些实例不会影响到正常的预发流量。
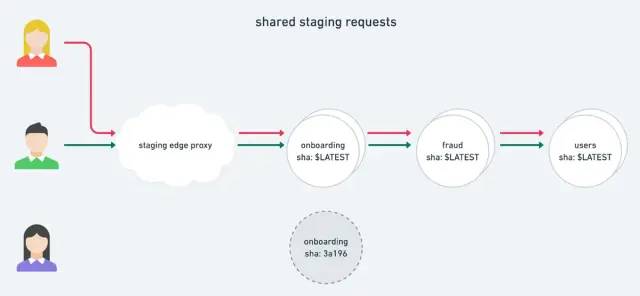
典型用户向预发环境发出的请求不会通过任何被实时卸载的实例
通过给请求附加特定的头(request baggage),用户可以选择将请求路由到新实例:
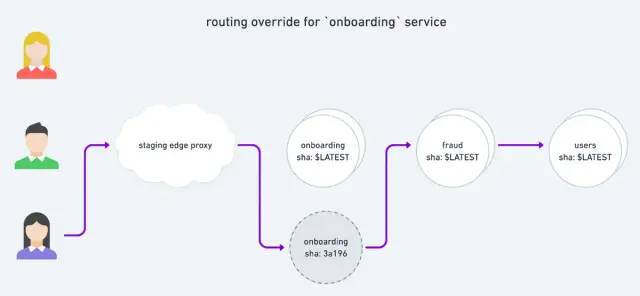
头部元数据允许用户在每个请求的基础上修改调用流
在本文的其余部分,我们将深入探讨如何构建这些组件来提供集成调试体验。
— 2 —
卸载部署(Offloaded Deployments)

Lyft使用Envoy作为服务网络代理,处理众多服务之间的通信
在Lyft,每项服务的每个实例都被部署在一个Envoy sidecar旁边,作为该服务的唯一出入口。通过确保所有网络流量都通过Envoy,我们为开发人员提供了一个简化的流量视图,该视图以一种与语言无关的方式提供了服务抽象、可观察性和可扩展性。
服务通过向其Envoy sidecar发送请求来调用上游服务,Envoy将请求转发到上游的健康实例。我们通过控制平面更新Envoy的配置,控制平面基于Kubernetes事件通过xDS API[4]进行更新。
避免服务发现
如果我们希望创建一个不会从网格中正常获取服务流量的实例,我们需要指示控制平面将其排除在服务发现之外。为了实现这一点,我们在Kubernetes Pod标签中嵌入额外的信息,表示该Pod已被卸载:
...
app=foo
environment=staging
offloaded-deploy=true
...然后我们可以修改控制平面来过滤这些实例,确保它们在准备阶段不接收标准流量。
当用户准备在预发环境(本地迭代后)创建卸载部署时,首先必须在GitHub中创建一个pull request。我们的持续集成将自动启动部署所需的容器镜像构建。然后用户可以利用GitHub机器人显式的卸载部署他们的服务到预发环境:
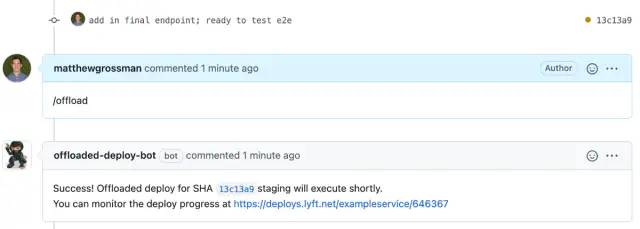
我们的GitHub机器人可以从PR简单的创建一个卸载部署
通过这一方式,用户可以为某个服务创建独立的部署,与普通的临时部署共享完全相同的环境:与标准数据库的交互,出口调用到其他服务,并且可以被标准的指标/日志/分析系统所观测。
对于那些只想ssh到实例并测试脚本或运行调试器而不担心影响预发环境其余部分的开发人员来说,这被证明非常有用。然而,当开发人员可以在手机上打开Lyft应用,并确保请求在一个卸载部署中得到PR代码的服务时,卸载部署才真正具有威力。
— 3 —
覆盖报头和上下文传播(Override Headers and Context Propagation)
要将请求路由到已卸载的部署,需要在请求中嵌入元数据,以便通知基础设施何时修改调用流。元数据包含想要覆盖的服务的路由规则,以及应该将流量引导到哪些卸载的部署上去。我们决定将这些元数据携带在请求头中,从而对服务和服务所有者保持透明。
不过,我们需要确保头信息可以通过使用不同语言编写的服务在网格中传播。我们已经使用OpenTracing报头(x-ot-span-context)将跟踪信息从一个请求传播到下一个请求。
OpenTracing有一个叫做“baggage[5]”的概念,这是一个嵌在跨服务边界的报头中的持久化键/值结构。将元数据编码到baggage中,通过请求和跟踪库将其从一个请求传播到下一个请求,使我们能够进行快速的处理。
构造和附加Baggage
实际的HTTP报头是一个base64编码的trace protobuf。我们创建了自己的protobuf,命名为Overrides,注入到跟踪的baggage中,如下代码演示:
syntax = "proto3";
/* container for override metadata */
message Overrides {
// maps cluster_name -> ip_port
map<string, string> routing_overrides = 1;
}我们可以将样本数据结构嵌入到跟踪baggage中
from base64 import standard_b64decode, standard_b64encode
from flask import Flask, request
from lightstep.lightstep_carrier_pb2 import BinaryCarrier
import overrides_pb2
def header_from_overrides(overrides: overrides_pb2.Overrides) -> bytes:
"""
Attach the `overrides` to the trace's baggage and return the new `x-ot-span-context` header
"""
# decode the trace from the current request context
header = request.headers.get('x-ot-span-context', '')
trace_proto = BinaryCarrier()
trace_proto.ParseFromString(standard_b64decode(header))
# b64encode the provided custom `overrides` and place in the baggage
b64_overrides = standard_b64encode(overrides.SerializeToString())
trace_proto.basic_ctx.baggage_items['overrides'] = b64_overrides
# re-encode the modified trace for use as an outgoing HTTP header
return standard_b64encode(trace_proto.SerializeToString())
# create a sample `Overrides` proto that overrides routing for `users` service
overrides_proto = overrides_pb2.Overrides()
overrides_proto.routing_overrides["users"] = "10.0.0.42:80"
with Flask(__name__).test_request_context('/add-baggage'):
new_header_with_baggage = header_from_overrides(overrides_proto)
print({"x-ot-span-context": new_header_with_baggage})
# {'x-ot-span-context': b'Ei8iLQoJb3ZlcnJpZGVzEiBDaFVLQlhWelpYSnpFZ3d4TUM0d0xqQXVOREk2T0RBPQ=='}如何提取当前的trace并覆盖
为了从开发人员那里抽象出这种数据序列化,我们为现有的代理应用程序添加了创建头的工具(请阅读更多关于代理的信息)。开发人员将客户端指向代理,从而可以用用户定义的Typescript代码拦截请求/响应数据。我们创建了一个助手函数setEnvoyOverride(service: string, sha: string),它将通过sha查找IP地址,创建Override protobuf,编码头部,并确保它被附加到通过代理的每个请求上。
上下文传播(Context Propagation)
上下文传播在任何一个分布式跟踪系统中都很重要。我们需要元数据在请求的整个生命周期内都可用,以确保许多深层调用的服务能够访问用户指定的覆盖。我们希望确保每个服务都能将元数据正确转发到请求流中后续的服务中——即使服务本身并不关心其内容。
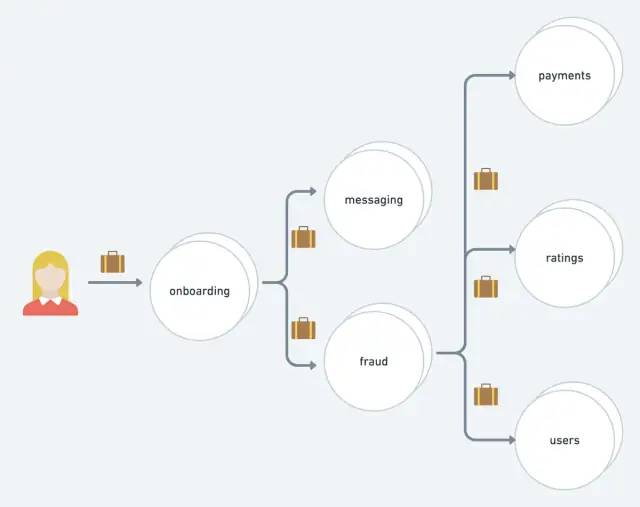
调用图中的每个服务都必须传播元数据以实现完整的跟踪覆盖
Lyft的基础设施用我们最常用的语言(Python、Go、Typescript)维护标准的请求库,为开发人员处理上下文传播。如果服务所有者使用这些库调用另一个服务,上下文传播对用户就是透明的。
不幸的是,在这个项目推出期间,我们发现上下文传播并不像我们希望的那样普遍。
最初经常有用户来找我们,说他们的请求没有被覆盖,罪魁祸首通常是trace丢失。我们投入了大量资金,以确保上下文传播能够跨各种语言特性(例如Python gevent/greenlets)、多种请求协议(HTTP/gRPC)以及各种异步作业/队列(SQS[6])工作。我们还添加了可观察性和工具来诊断涉及trace丢失的问题,例如标识没有添加头部的服务出口的指示板。
— 4 —
扩展Envoy
既然我们已经在请求中传播了重写元数据,就需要修改网络层来读取元数据并重定向到想要的卸载实例。
因为我们所有服务都是通过Envoy sidecar发出请求的,所以可以在这些代理中嵌入一些中间件来读取覆盖并适当修改路由规则。我们利用Envoy的HTTP过滤系统处理请求,因此在HTTP过滤器中实现了两个步骤:读取请求头的覆盖信息,并修改路由规则,从而将路由重定向到已卸载的部署。
利用Envoy HTTP过滤器跟踪
我们决定创建一个解码过滤器,允许我们在请求被发送到上游集群之前解析并对覆盖做出反应。HTTP过滤系统提供了简单的API,可以获取当前的目的路由以及正在处理的请求的所有报头。虽然是用C++实现的,但下面的伪代码反映了基本要点:
def routing_overrides_filter(route, headers):
routing_overrides = headers.trace().baggage()['overrides'] # {'users': '10.0.0.42:80'}
next_cluster = route.cluster() # 'users'
# modify the route if there's an override for the cluster we are going to
if next_cluster in routing_overrides:
# the user provided the ip/port of their offloaded deploy in the header baggage
offloaded_instance_ip_port = routing_overrides[next_cluster] # '10.0.0.42:80'
# redirect the request to the ORIGINAL_DST cluster with the new ip/port header
headers.set('x-envoy-original-dst-host', ip_port)
route.set_cluster('original_dst_cluster')过滤器使用Envoy的跟踪实用程序提取baggage中包含的覆盖。虽然过滤器总是可以访问像traceId和isSampled这样的跟踪信息,但我们首先必须修改Envoy,从而可以提取baggage中的信息。合并了这个更改后,过滤器就可以使用新的API来提取底层trace中的baggage:routing_overrides = headers.trace().baggage()['overrides']
最初目的集群(Original Destination Cluster)
假设覆盖应用于当前目标集群,则必须将请求重定向到已卸载的部署。我们使用Envoy的原始目的地[7](ORIGINAL_DST)将请求发送到一个由baggage提供的覆盖。
对于我们配置的ORIGINAL_DST集群,最终目的地是由一个特殊的x-envoy-original-dst-host报头决定的,它包含一个ip/port,如10.0.42:80,HTTP过滤器可以改变这个报头来重定向请求。
例如,如果请求最初是为user集群准备的,但是用户重写了ip/port,我们将把x-envoy-original-dst-host更改为所提供的ip/port。
当x-envoy-original-dst-host被修改后,过滤器需要将请求发送到ORIGINAL_DST集群,以确保发送到新的目的地。这一需求促使我们对Envoy做出了第二个变更:支持路由可变性。合并此变更后,过滤器就可以改变目标集群:route.set_cluster('original_dst_cluster')。
— 5 —
结果
通过卸载部署、传播baggage和Envoy过滤器,我们现在已经展示了预发覆盖的所有主要组件。
这个工作流程极大改进了端到端测试的开销。我们现在每个月都有100个独立的服务部署,与以前的Onebox解决方案相比,预发覆盖有以下优点:
环境配置:Onebox要求用户启动数百个容器并运行定制的种子脚本,需要开发人员花上至少1个小时准备环境。通过预发覆盖,用户可以在10分钟内通过端到端环境部署某个变更。
低成本基础设施:Onebox运行的是完全独立于预发/生产环境的技术栈,所以底层基础设施组件(例如网络、可观察性)通常是单独实现的。通过将端到端测试转移到预发环境,由于环境改进为集中维护,降低了基础设施支持的成本。
低成本功能验证: 由于Onebox和产品之间的差异,即使在Onebox端到端测试之后,用户也经常(合理的)怀疑代码的正确性。预发与生产环境在数据和流量模式方面更为接近,使用户更有信心相信如果变更在预发环境中就绪,也就意味着在生产环境中就绪。
额外的工作
启动预发覆盖是一项涉及网络、部署、可观察性、安全性和开发工具的跨组织工作。以下是一些没有涉及到的额外工作流程:
配置覆盖: 除了在baggage中指定路由覆盖外,我们还允许用户在每个请求的基础上修改配置变量。通过修改配置库,赋予baggage优先级,让用户在启用全局配置之前为请求设置特性标志。
安全影响: 因为可以指定覆盖路由规则,所以必须锁定过滤器功能,以确保不良行为者不能被任意路由。
未来的工作
展望未来,我们可以通过预发覆盖做更多的事情,让用户重新创建想要验证的端到端场景:
可共享的baggage: 为用户提供一个集中管理的baggage存储,允许持久化一组独特的覆盖(服务foo是X,服务bar是Y,标签baz是Z),通过与团队成员共享确切的场景而改善协作。
覆盖用例: 让我们的基础设施了解其他覆盖,以便让用户控制请求的行为。例如,我们可以使用Envoy错误注入将人造延迟注入到请求中,临时启用调试日志记录,或者重定向到不同的数据库。
与本地开发集成: 我们可以允许重写请求,直接将请求重路由到用户的笔记本电脑,而不是要求用户在准备阶段启动他们的PR实例。
请继续关注我们系列中的下一篇文章,我们将展示如何在交付阶段使用自动化验收测试对生产部署进行验收!
相关链接:
https://eng.lyft.com/scaling-productivity-on-microservices-at-lyft-part-4-gating-deploys-with-automated-acceptance-4417e0ebc274
https://en.wikipedia.org/wiki/Service-level_objective
https://response.pagerduty.com/before/severity_levels/
https://www.envoyproxy.io/docs/envoy/latest/api-docs/xds_protocol
https://opentracing.io/docs/overview/tags-logs-baggage/
https://aws.amazon.com/sqs/
https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/upstream/load_balancing/original_dst
本文源自公众号DeepNoMind,分布式实验室已获完整授权。
推荐阅读:
点击下方卡片关注分布式实验室,和我们一起
关注分布式最佳实践

▲ 点击上方卡片关注分布式实验室,掌握前沿分布式技术
新的一年,想一起学习K8s、考CKA证书吗?来,这里有最好的学习方案,线下3天封闭式培训,15人小班课,考不过免费复训。Kubernetes实战班北京、上海、深圳,三站齐发,扫描下方二维码咨询详情。
















 7946
7946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









