






Bartek Plotka是Improbable的一名基础设施软件工程师。他对一些新兴技术和分布式系统的问题非常感兴趣。凭借着曾经在Intel从事底层开发的背景,之前作为一名Mesos贡献者的经验,以及在Improbable线上全球规模的SRE经历,他专注于微服务领域相关的改进工作。他的三个最爱分别是Golang,开源软件,还有排球。
也许从我们的旗舰产品SpatialOS不难猜到,Improbable面对的需求是一个全球规模的,运行着数十个Kubernetes集群的高度动态的云基础设施。为了维持他们的运转,我们成为了Prometheus监控系统的早期用户。Prometheus能够实时跟踪数百万个监控指标,并附带提供了一套强大的查询语言,用户可以通过它从这些指标里提取有用信息。
Prometheus简单可靠的运维模型是其主打卖点之一。然而,在形成一定规模后,我们发现了一些短板。为了解决这些问题,我们今天正式发布了Thanos项目[1],一个由Improbable开源的项目,它可以将全球现有的Prometheus部署无缝转换成一个统一的监控系统,配套一个不受限制的历史数据存储。

在一定的集群规模下,一些问题将在负载超出一个普通的Prometheus集群承载能力后不断被暴露出来。我们如何能够以一个经济可靠的方式来存储PB级别的历史数据?我们能够不牺牲查询响应时间便做到这一点吗?我们能够通过一个单一的查询接口访问到不同Prometheus服务器上的所有指标数据吗?再者,我们能否以某种方式合并通过Prometheus高可用集群采集到的复制数据吗?
作为这些问题的答案,我们创立了Thanos项目。在接下来的部分,我们将讲述我们在开发Thanos之前是怎样规避这些功能上的不足之处,并详细介绍我们心中构想的一些目标。
全局查询视图
Prometheus主张根据功能进行分片。即便是单台Prometheus服务器也能针对几乎所有用例提供足够的扩展能力,将用户从水平扩展的复杂性中解放出来。
尽管这是一个很棒的部署模型,然而用户往往希望能够通过相同的API或者UI访问所有的数据 —— 即全局视图。举个例子,你可以在一个Grafana看板上渲染多张查询视图,但是每个查询只能针对一台单个的Prometheus服务器。而另一方面,倘若使用的是Thanos,用户将能够从多台Prometheus服务器上查询和聚合数据,因为所有这些数据均可以从单个端点获取。
在此之前,Improbable为了能够实现全局视图,我们将我们的Prometheus实例组织成一个多层的分级联盟[2]。这意味着需要建立一个单一的meta Prometheus服务器,从每个“叶子”服务器采集一部分数据。
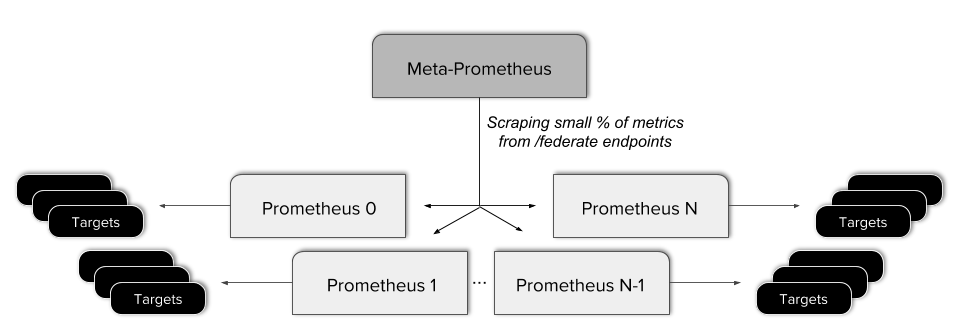
这种方式最终被证明是有问题的。它导致配置方面的负担不断增重,而且增加了一个额外地潜在故障点,并且需要在联盟节点上配置一些复杂的规则从而只暴露某些数据。此外,这样的联盟方式并没有实现一个真正意义上的全局视图,因为并非所有数据都可以从单个查询接口获得。
与之密切相关的是一套成对的Prometheus高可用服务器采集得到的数据所提供的一个统一视图。Prometheus的高可用模型即是单独地采集数据两次,这再简单不过了。然而,要得到一张两个数据流的合并和去重后的视图是一场浩大的可用性改进。
毋庸置疑,我们需要一套高可用的Prometheus集群。在Improbable,我们非常重视监控每一分钟采集得到的数据,然而每个集群部署一个单一的Prometheus实例意味着存在单点故障的风险。任何配置错误或者硬件故障都可以导致重要监测结果的丢失。即便是一次简单的发布也可能会导致指标采集出现小的中断,因为重新启动可能会比一次采集的时间间隔要长得多。
可靠的历史数据存储
我们的梦想之一(也是广大Prometheus用户的共同梦想)便是可以拥有一个廉价的,响应及时的长期指标存储。在Improbable,我们使用的是Prometheus 1.8,我们曾经被迫将指标保留策略设定为一个尴尬的九天。这增加了一个明显的运维限制,即我们可以通过监控图表回顾多久以前的情况。
Prometheus 2.0在这方面提供了不少帮助,时间序列的数据量不再影响整体的服务器性能(请参阅Fabian在KubeCon上关于Prometheus 2的演讲[3])。不过,Prometheus仍然是将指标数据放在它的本地磁盘里。尽管高效的数据压缩可以在一块本地的SSD盘上获得显著的优势,但是最终可以存储多少历史数据还是会受到限制。
此外,在Improbable,我们关注可用性,简易性和成本。更大的本地磁盘更难操作和备份。他们更加地昂贵而且需要更多的备份工具,这带来了不必要的复杂性。
降准采样(Downsampling)
一旦开始查询历史数据,我们很快便意识到,在我们检索几周,几个月,乃至最终数年的数据时,这里存在的大O复杂度会让查询变得越来越慢。
通常这个问题的解决办法称之为降准采样,这是一个降低信号采样率的过程。针对降准采样处理后的数据,我们可以在“伸缩“(zoom out)到一个更大的时间范围的同时维护相同数量的样本数据,从而保证查询响应的速度。对旧数据的降准采样是任何一款长期存储解决方案的必然要求,这超出了普通的Prometheus集群的范畴。
额外的目标
Thanos项目的最初目标之一是无缝集成任意现有的Prometheus实例。第二个目标是操作应该尽量简单,并且应该尽可能降低准入门槛。如果存在任何依赖关系的话,它们应当很容易满足小型和大型用户的需求,这也意味着基准成本是可以忽略不计的。

在上一节中我们列举了一些我们预期的目标,我们来盘点一下这些清单,看看Thanos是如何解决这些问题的。
全局视图
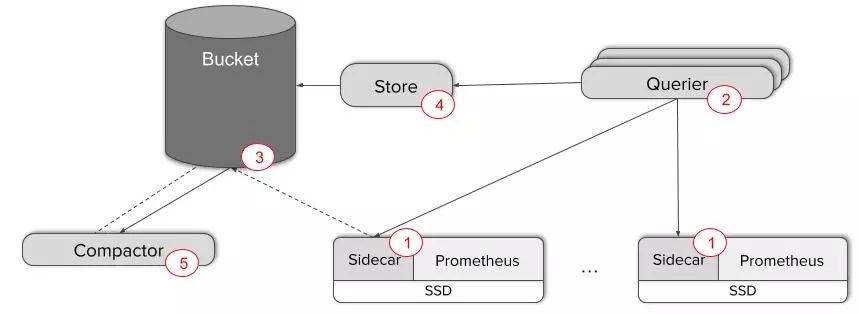
为了能够在现有的Prometheus集群之上收获一个全局视图,我们需要将中央查询层和所有服务器互联。Thanos Sidecar[4]组件即是担任这样的角色,它会被部署到每一台正在运行的Prometheus服务端一侧。它充当的是一个代理服务器,通过Thanos规范化的基于gRPC的Store API提供Prometheus的本地数据,它也允许通过标签和时间段来选择时间序列数据。
在另外一端运行的是一个可以横向扩展并且无状态的Querier组件,在应答PromQL查询时比标准的Prometheus HTTP API做的事情稍微多一些。Querier、Sidecar 以及其他的 Thanos组件通过gossip协议通信。
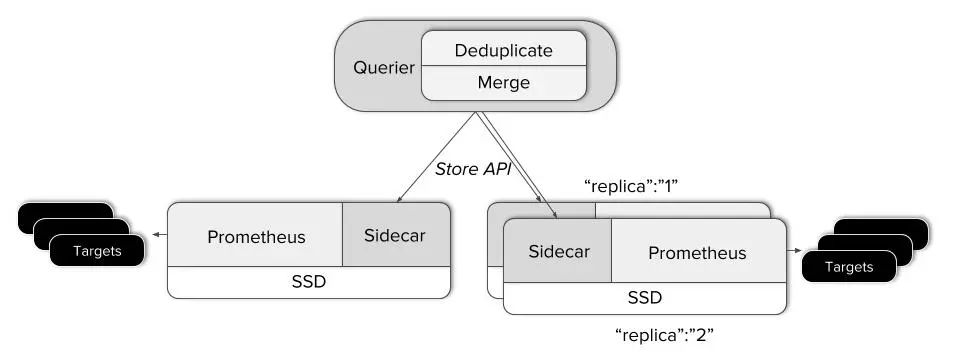
当Querier收到一个请求时,它会向相关的Store API服务器(这里即是我们的Sidecar)发送请求,并从他们的Prometheus服务器获取时间序列数据。
它将这些响应的数据聚合在一起,并对它们执行PromQL查询。 它可以聚合不相交的数据也可以针对Prometheus的高可用组进行数据去重。
它通过将完全分离的Prometheus部署整合到我们数据的一个全局视图的方式解决了我们遇到的问题里的核心难点。事实上,Thanos可以就这样部署,并且可以按需使用这些功能。根本不需要现有的Prometheus服务器做任何改动!
不受限的保留数据!
然而,迟早有一天,我们会希望保留超出Prometheus常规保留时间外的一些数据。为了实现这一点,我们决定使用对象存储系统来备份我们的历史数据。它在每个云甚至大多数本地数据中心上均有广泛应用,并且极具成本效益。此外,几乎所有对象存储解决方案均可以通过众所周知的S3 API进行访问。
Prometheus的存储引擎大约每两个小时将其最近的内存数据写入磁盘。持久化的数据块包含固定时间范围内的所有数据,并且是不可变的。这一点很有用,因为这样一来,Thanos Sidecar便可以简单地监听Prometheus的数据目录变化,然后在新的数据块出现时将它们上传到对象存储桶中。
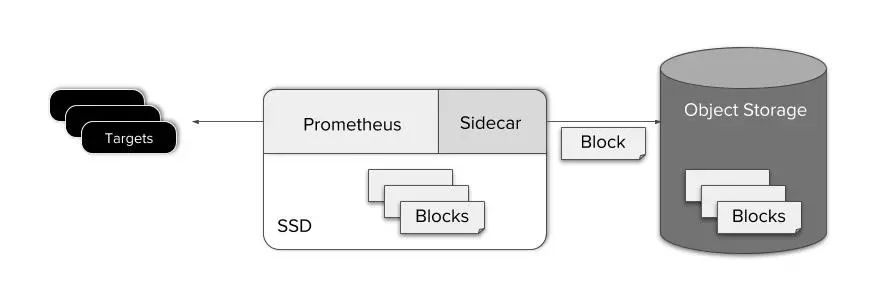
在指标数据块写入磁盘后通过Sidecar上传到对象存储的一个额外好处在于它可以保持 ”scraper“(由Prometheus和其配套的Thanos Sidecar组成)足够的轻量。这简化了运维,成本,和系统设计。
备份我们的数据很容易。 那么再次从对象存储中查询数据呢?
Thanos Store组件充当了一个对象存储里面数据的数据检索代理。就像Thanos Sidecar那样,它也会加入到gossip集群里并且实现Store API。这样一来现有的Querier就可以把它也当成是类似Sidecar那样的另外一个时间序列数据的数据源 —— 不需要任何特殊处理。
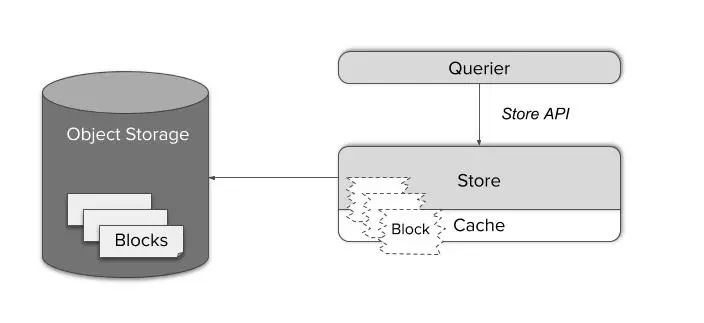
时间序列的数据块由一些大文件组成。按需下载它们的话会显得效率低下,而且在本地缓存它们需要巨大的内存和磁盘空间。
与之相反的是,Store Gateway知道如何处理Prometheus存储引擎的数据格式。通过智能的查询计划并且仅缓存必要索引部分的数据块的方式,它能够将一些复杂查询降级成一个针对对象存储里的文件最小数量的HTTP范围请求(HTTP range request)。通过这种方式,它可以在不影响响应时间的同时将原始请求的数量降低四到六个数量级,从整体上看,很难区分这和查询本地SSD上的数据有何差异。
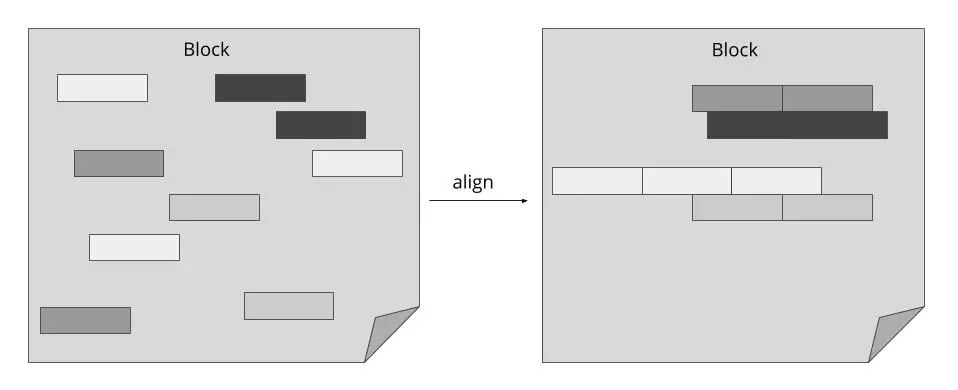
如上图所示,Thanos Querier通过利用Prometheus存储格式的特点(可在块文件中共存相关数据)显著降低了针对对象存储产品的单次请求成本。考虑到这一点,我们可以将多个字节的提取工作聚合到一个最小数量的批量调用中。
压缩和降准采样(Compaction & downsampling)
在时间序列的一个新数据块成功上传到对象存储的那一刻起,我们便可以把它当做是Storage Gateway上一条可用的“历史”数据。
然而,经过一段时间后,来自单一数据源(即附带运行Sidecar的Prometheus实例)的这些数据块逐渐累积,却没能充分发挥索引的全部潜能。为了解决这个问题,我们引入了一个单独的单例组件,名为Compactor。它会简单地将Prometheus的本地压缩机制应用到对象存储里的历史数据,并且可以作为一个简单的定时批处理任务执行。

得益于Prometheus高效的样本压缩技术,从数据大小的角度来看,在一个很长时间的范围内查询许多序列并不成问题。然而,数十亿的样本数据的解压以及针对这些样本执行查询处理的潜在成本会不可避免地导致查询延迟的急剧增长。另一方面,由于每个可用的屏幕像素上存在着数以百计的数据点,甚至因此无法渲染全分辨率的数据。这也使得降准采样不仅可行,而且不会引起明显的精度损失。
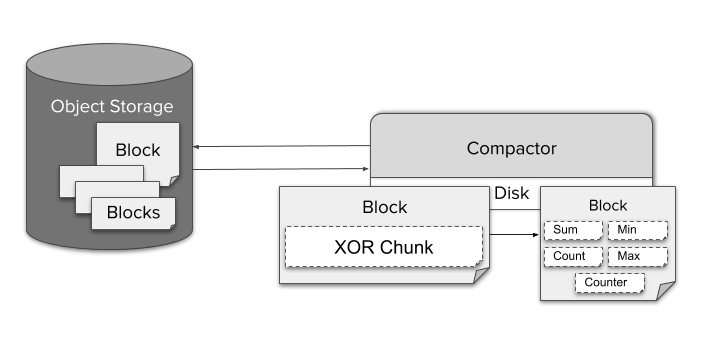
为了生成降准采样的数据,Compactor会持续不断地将序列数据聚合到5分钟和一小时的分辨率。针对用TSDB的XOR压缩编码的每个原始数据块,它将会存储几个不同类型的聚合数据,例如,单一数据块的最小值,最大值,或者总和。这使得Querier能够针对给定的PromQL查询自动选择合适的聚合数据。
从用户的角度来看,使用降准采样后的数据不需要做什么特殊配置。当用户缩小(zoom in)和拉大(zoom out)时,Querier会自动在不同的分辨率和原始数据之间进行切换。或者,用户也可以通过在查询参数中指定一个自定义的“step”来直接控制它。
由于每GB的存储成本是微乎其微的,在默认情况下,Thanos将会始终在存储里维持原始的以及五分钟和一小时分辨率的数据,因而无需删除原始数据。
记录规则(recording rule)
即便使用了Thanos,记录规则依然是监控堆栈的重要组成部分。 它们减少了查询的复杂度,延迟和成本。它们还为用户提供了方便的查看指标数据重要的聚合后视图的快捷方式。Thanos建立在普通的Prometheus实例之上,因此,在现有的Prometheus服务器里保留记录规则(recording rule)和告警规则(alert rule)是完全有效的。但是,对于下面这些情况来说,这可能不太够用:
全局的告警和规则(例如:当三个集群中的两个以上的集群里的服务宕机时发出告警)
超出单台Prometheus本地保留数据的规则
希望将所有规则和告警存储在一个地方
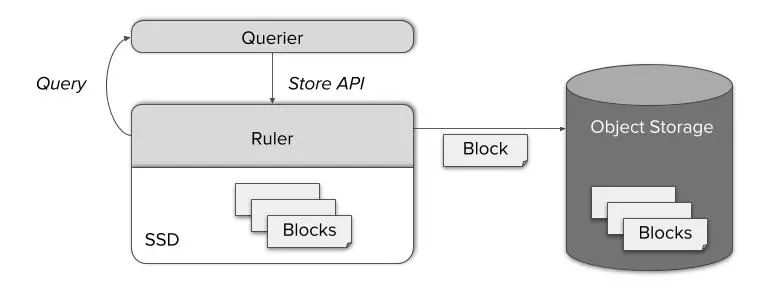
针对上述这些情况,Thanos提供了一个名为Ruler的单独组件,它会基于Thanos Querier执行规则并作出告警。通过公开众所周知的Store API,查询节点得以访问新计算出的指标数据。随后,它们也会备份到对象存储并可以通过Store Gateway访问。
Thanos的力量
Thanos非常灵活,它可以根据用户的使用场景进行不同的设置。在对普通的Prometheus实际做迁移时这一点尤其有用。我们不妨通过一个简单例子快速回顾一下从Thanos的组件里学到的东西。下面这个例子讲解了如何将自己普通的Prometheus迁移到我们闪亮的'无限保留指标'的世界:
将Thanos Sidecar添加到你的Prometheus服务端 - 例如,在Kubernetes pod里运行一个相邻容器;
部署一些Thanos Querier的副本以启用数据浏览功能。与此同时,用户可以轻松地在Scraper和Querier之间配置一个gossip集群。使用thanos_cluster_members指标来确认所有组件都已连接。
值得一提的是,仅靠上述单独的这两步就足以实现一个从潜在的Prometheus高可用复本获取结果的全局视图和无缝的数据去重!只需将仪表盘连接到Querier HTTP端点或直接使用Thanos UI即可。
但是,如果你想要实现指标数据的备份和长期保留,我们需要完成额外的下面三个步骤:
创建一个AWS S3或GCS存储桶。你只需要简单地配置一下Sidecar即可完成数据的备份。如今你也可以将本地保留策略配至最低。
部署一个Store Gateway然后将它加入到现有的gossip集群。做到这一点的话我们的查询便也可以访问到备份好的数据!
部署Compactor,通过应用压缩和降准采样来提升长期数据查询的响应能力。
只需要五步,我们便可以将Prometheus的实例组装成一个强大的监控系统,为用户提供全局视图,无限制的保留数据并且拥有潜在的指标高可用。
相关链接:
https://github.com/improbable-eng/thanos
https://github.com/prometheus/prometheus/blob/master/docs/federation.md#hierarchical-federation
https://www.youtube.com/watch?v=nDalewt4BOw
https://kubernetes.io/blog/2015/06/the-distributed-system-toolkit-patterns/#example-1-sidecar-containers
https://github.com/improbable-eng/thanos/tree/master/kube
https://github.com/improbable-eng/thanos/blob/master/docs/getting_started.md
Kubernetes入门与进阶实战培训















 390
390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









