







Beautifulsoup库:
就是Python的一个HTML的解析库,可以用它来方便地从网页中提取数据。借助网页的结构和属性等特性来解析网页。
解析器:
Beautiful Soup在解析时实际上依赖解析器,它除了支持Python标准库中的HTML解析器外,还支持一些第三方解析器(比如lxml)
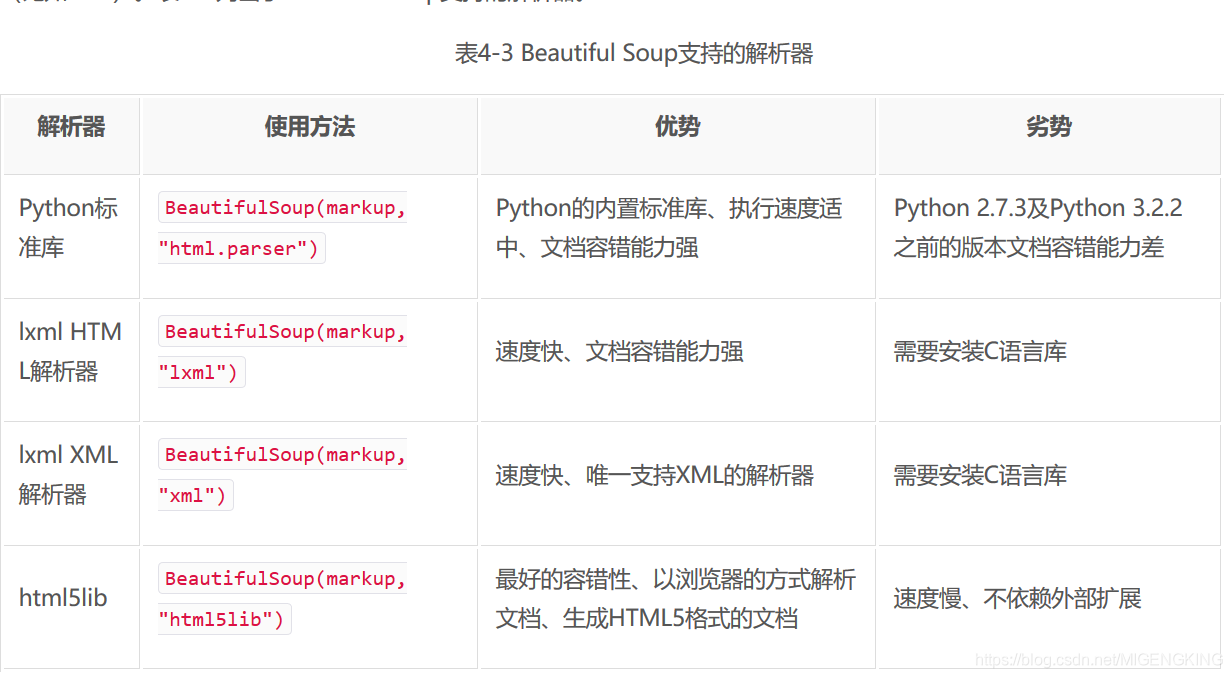
选择器:
1、节点选择器
2、方法选择器
3、css选择器
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
1)tag:HTML 中的一个个标签,两个重要的属性,name 和 attrs :
2)NavigableString:得到了标签的内容用 .string 即可获取标签内部的文字,会输出注释
3)BeautifulSoup:BeautifulSoup 对象表示的是一个文档的全部内容,是一个特殊的 Tag
4)Comment:Comment 对象是一个特殊类型的 NavigableString 对象,不会输出注释
其中,BeautifulSoup是Tag对象的具体化;Comment是Navigablestring对象的具体化。
1、BeautifulSoup的节点选择器:
直接调用节点的名称就可以选择节点元素,再调用string属性就可以得到节点内的文本了,这种选择方式速度非常快。如果单个节点结构层次非常清晰,可以选用这种方式来解析。
选择元素
|
提取信息:获取名称 获取属性 获取内容
|
嵌套选择:继续调用节点进行下一步的选择
|
关联选择:有时候不能做到一步就选到想要的节点元素,需要先选中某一个节点元素,然后以它为基准再选择 它的子节点、父节点、兄弟节点等。
实例;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6329
6329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









