







利用Scrapy框架爬取前途无忧招聘信息
关于安装和命令使用可参考:https://docs.scrapy.org/en/1.7/intro/install.html
先创建项目和爬虫文件
分析网站
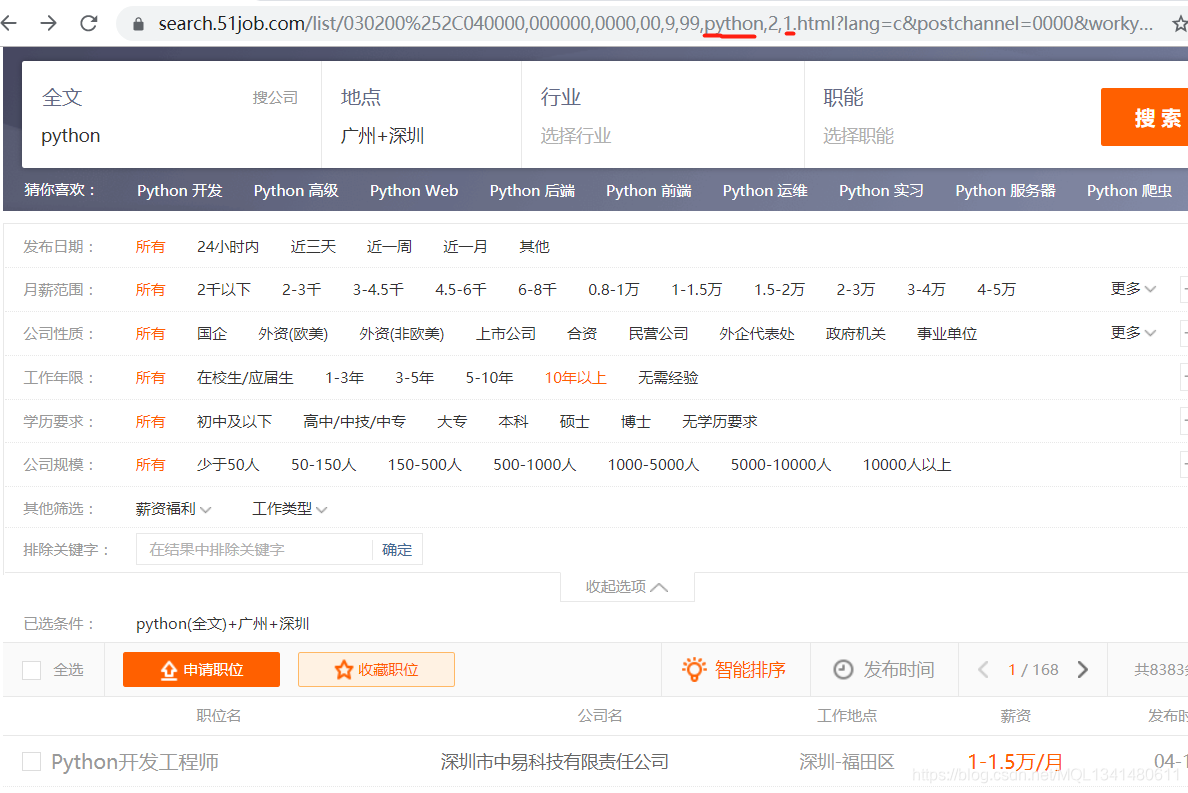
发现输入搜索内容跟url链接保持一致,且更换页数后的数字也跟url链接有关系(看url链接红线标识)
这样我们就可以通过修改url来选择性爬取所有页面的招聘信息
继续分析
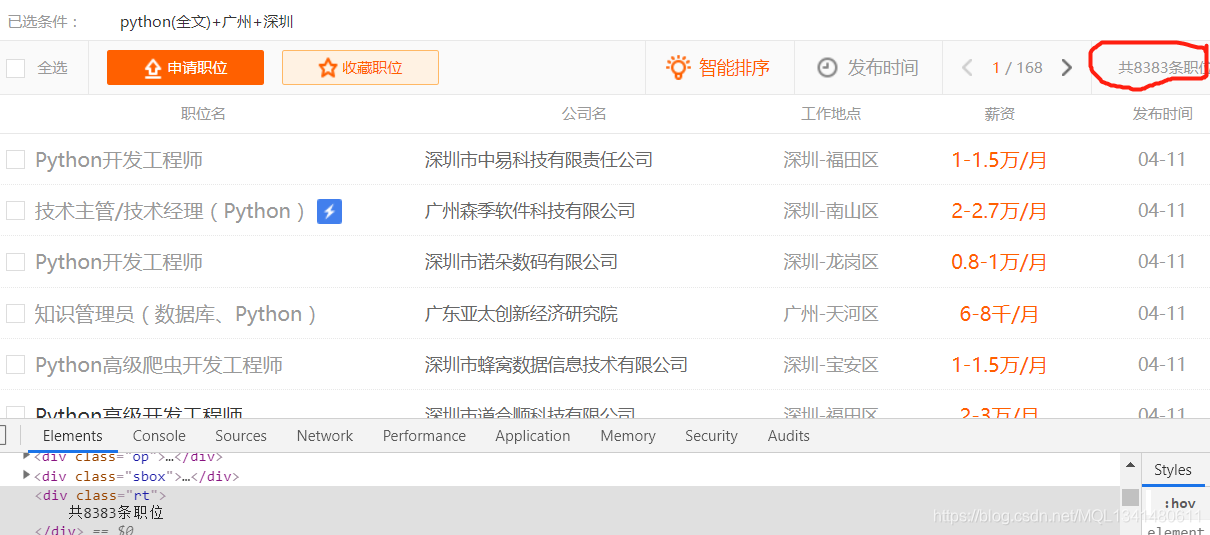
这里直接显示了所有职位的数量,我们可以这个数字来确定要爬取的页数(一页有50个职位)。
总结思路:我们先通过输入的形式修改url来确定我们要搜索的职位,然后先爬取该搜索内容网站的职位数量,根据职位数量确定页数,再爬取所有页数的职位详情信息。代码如下
# -*- coding: utf-8 -*-
import scrapy
from urllib import parse
import urllib
import re
frist = input("请输入职位")
frist = urllib.parse.quote(frist)
class JobsSpider(scrapy.Spider):
name = 'jobs'
allowed_domains = ['51job.com']
start_urls = ['https://search.51job.com/list/030200%252C040000,000000,0000,00,9,99,'+str(frist)+',2,1.html?']
def parse(self, response):
#抓取职位数量
SL = response.xpath('//*[@id="resultList"]/div[2]/div[4]/text()').get(default='')
SL = re.findall('共(.*?)条职位',SL)[0]
#根据数量确定页数
if int(SL) % 50 != 0:
page = int(SL) // 50 + 1
print(page)
else:
page = int(SL) // 50
print(page)
#通过修改url来爬取所有页面
for i in range(1,page+1):
url = 'https://search.51job.com/list/030200%252C040000,000000,0000,00,9,99,'+str(frist)+',2,{}.html?'.format(i)
#print(url)
yield scrapy.Request(url,callback=self.parseDetail)
def parseDetail(self,response):
#爬取职位详情页面的url
URL_list = response.xpath('//*[@id="resultList"]/div/p/span/a/@href').extract()
for URL in URL_list:
yield scrapy.Request(URL,callback=self.parseXX)
def parseXX(self,response):
#爬取详情信息
ZW = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/h1/text()').get(default='')
GZ = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()').get(default='')
GS = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[1]/a[1]/text()').get(default='')
YQ1 = response.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div//p/text()').extract()
YQ2 = response.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div//span/text()').extract()
YQ3 = response.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div/text()').extract()
if len(YQ1) > 1:
YQ = YQ1
elif len(YQ2) > 1:
YQ = YQ2
elif len(YQ3) > 1:
YQ = YQ3
items = {
"职位:":ZW,
"工资:": GZ,
"公司:":GS,
"要求:":YQ
}
yield items
运行结果

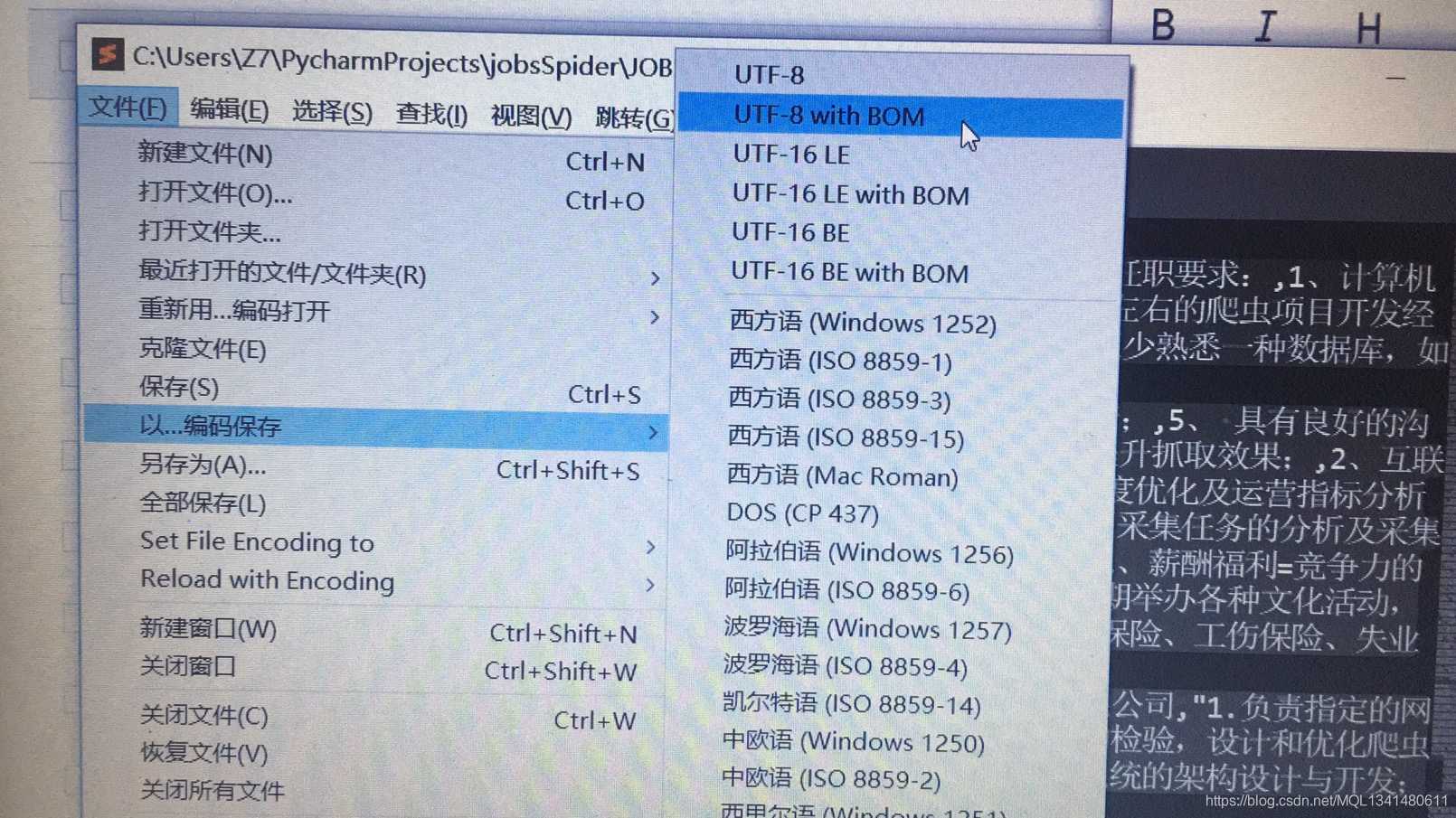
这里保存为csv文件输出。
如果打开是乱码的话,用文本编辑器转换一下编码保存再打开就可以了
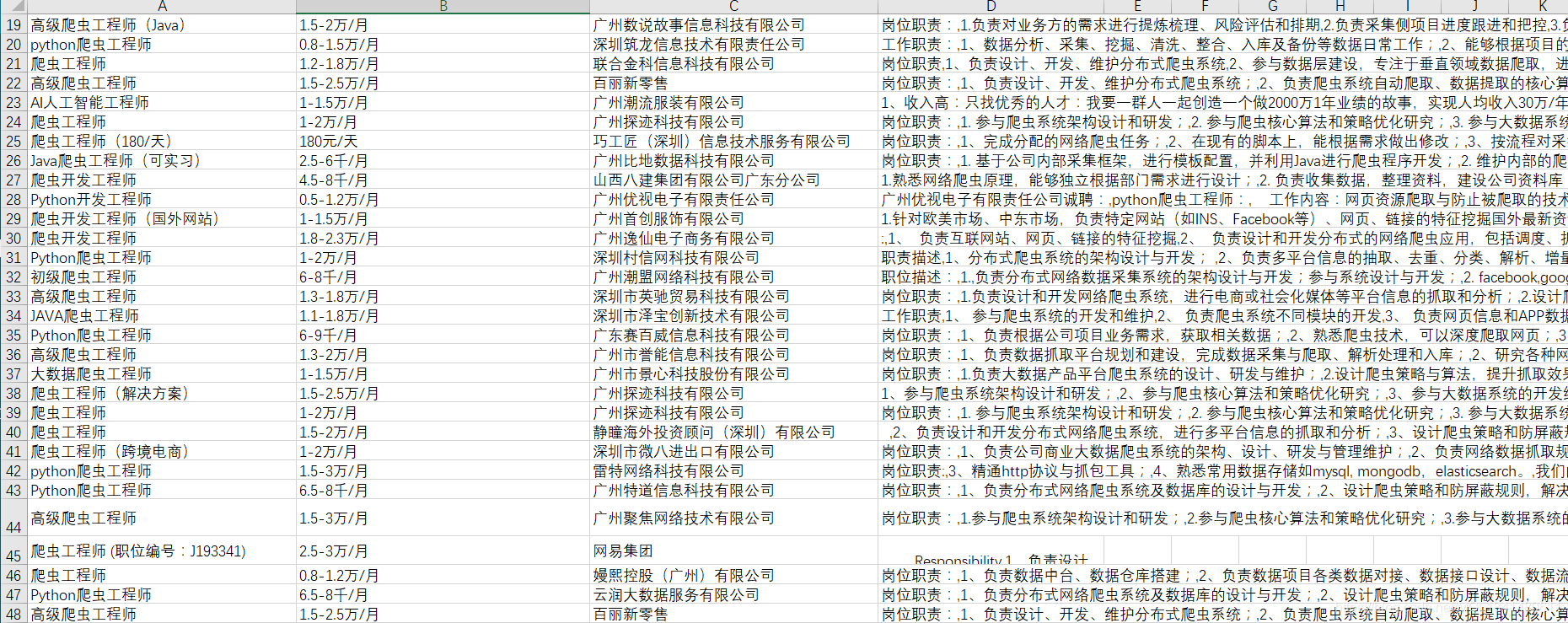
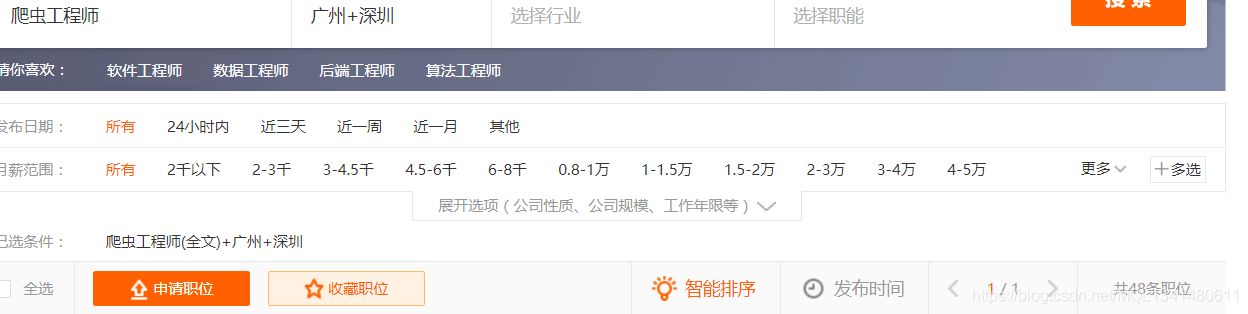
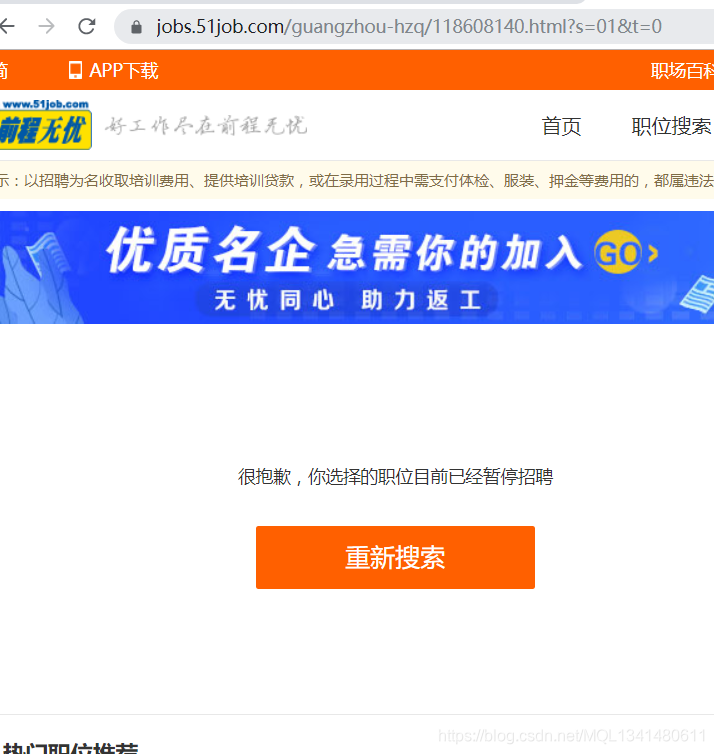
总共48个职位爬了47个,少了一个。我去看了一下运行记录有一个404的请求信息
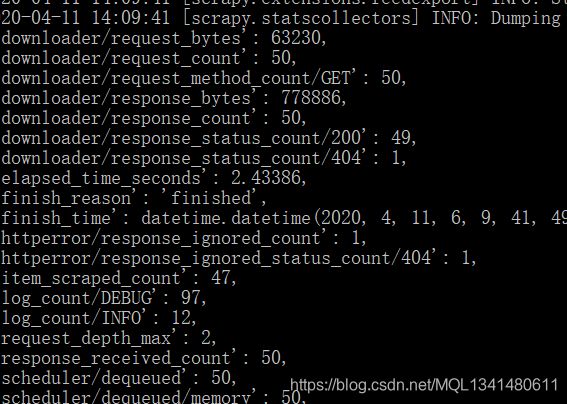

复制链接在网页搜一下














 6433
6433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









