




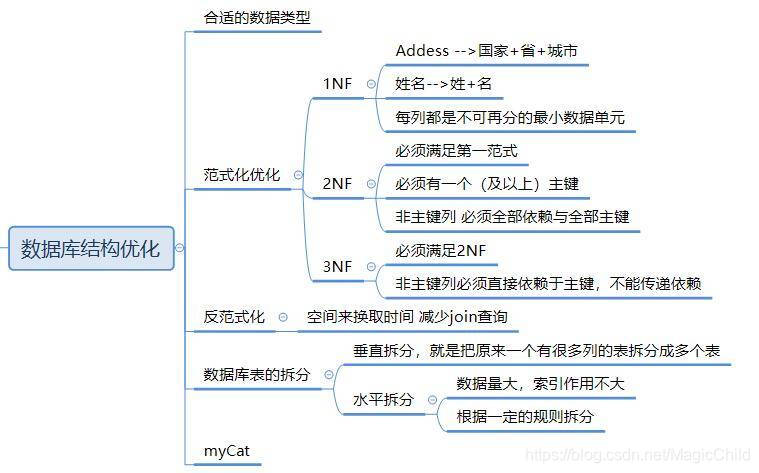
第一范式 :原子性,列不可再分
第二范式: 在第一范式的基础上,存在主键,其他字段都依赖主键
第三范式: 在第二范式的基础上,其他字段不能依赖其他字段
反范式:牺牲空间换时间增加效率,违反第二第三范式
反范式
反范式是通过增加冗余数据或数据分组来提高数据库读性能的过程。在某些情况下, 反范式有助于掩盖关系型数据库软件的低效。关系型的范式数据库即使做过优化, 也常常会带来沉重的访问负载。
范式
1.1、第一范式(1NF:每一列不可包含多个值)
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。
在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
1.2、第二范式(2NF:非主属性部分依赖于主关键字)
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。简而言之,第二范式就是非主属性部分依赖于主关键字。
1.3、第三范式(3NF:属性不依赖于其它非主属性)
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性。
垂直拆分
专库专用
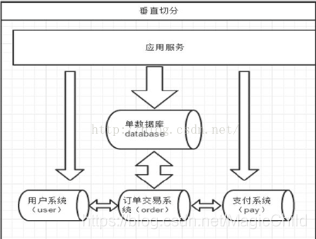
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面
优点:
1. 拆分后业务清晰,拆分规则明确。
2. 系统之间整合或扩展容易。
3. 数据维护简单。
缺点:
1. 部分业务表无法join,只能通过接口方式解决,提高了系统复杂度。
2. 受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
3. 事务处理复杂。
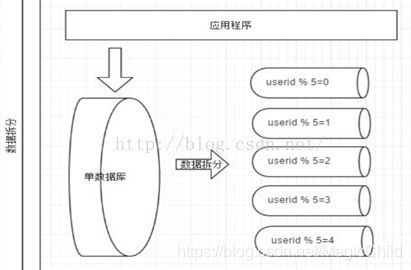
水平拆分
垂直拆分后遇到单机瓶颈,可以使用水平拆分。相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。
相对于垂直拆分,水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中 的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,主要有分表,分库两种模式,如图:
优点:
1. 不存在单库大数据,高并发的性能瓶颈。
2. 对应用透明,应用端改造较少。
3. 按照合理拆分规则拆分,join操作基本避免跨库。
4. 提高了系统的稳定性跟负载能力。
缺点:
1. 拆分规则难以抽象。
2. 分片事务一致性难以解决。
3. 数据多次扩展难度跟维护量极大。
4. 跨库join性能较差。

















 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









