



摘要: 深入剖析Java中令人头疼的ConcurrentModificationException异常,通过原理图解+场景分析+性能对比,全面讲解HashMap的线程安全问题。提供两种高效解决方案,包含代码示例+诊断指南,助你彻底解决并发环境下的Map使用难题!
一、问题现象:神秘的ConcurrentModificationException
在高并发Java应用中,以下异常栈频繁出现:
Exception in thread "Thread-1" java.util.ConcurrentModificationException
at java.util.HashMap$HashIterator.nextNode(HashMap.java:1445)
at java.util.HashMap$EntryIterator.next(HashMap.java:1479)
at com.example.MyCacheProcessor.updateCache(MyCacheProcessor.java:42)
问题本质:当一个线程遍历HashMap时(使用iterator/for-each),另一个线程执行了结构性修改(添加/删除元素)
二、原理解析:HashMap的Fail-Fast机制
1. 核心变量:modCount与expectedModCount
public class HashMap<K,V> {
transient int modCount; // 修改计数器
abstract class HashIterator {
int expectedModCount = modCount; // 初始化时记录
final Node<K,V> nextNode() {
if (modCount != expectedModCount) // 关键检查点
throw new ConcurrentModificationException();
// ...
}
}
public V put(K key, V value) {
// ...插入逻辑
modCount++; // 结构性修改
return null;
}
}
2. Fail-Fast机制工作流程 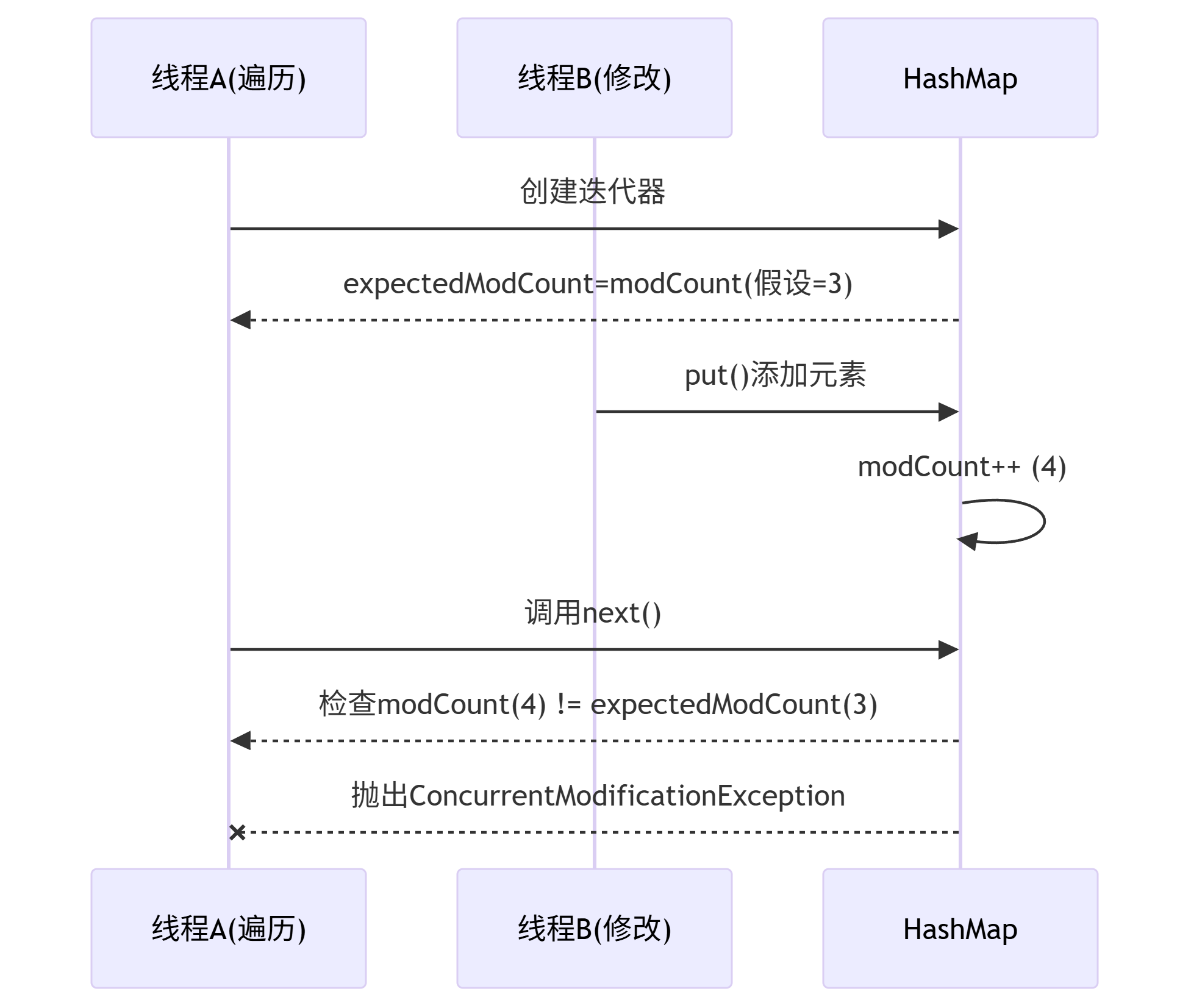
3. 单线程中的陷阱
Map<String, Integer> map = new HashMap<>();
map.put("A", 1); map.put("B", 2);
// 错误写法:遍历时直接调用Map的remove()
for (String key : map.keySet()) {
if ("A".equals(key)) {
map.remove(key); // 抛出异常!
}
}
// 正确写法:使用迭代器的remove()
Iterator<String> it = map.keySet().iterator();
while (it.hasNext()) {
String key = it.next();
if ("A".equals(key)) {
it.remove(); // 安全删除
}
}
三、解决方案:多线程环境的安全选择
方案1:Collections.synchronizedMap(全局锁)
// 创建同步Map
Map<String, Integer> syncMap = Collections.synchronizedMap(new HashMap<>());
// 写入操作(自动加锁)
syncMap.put("key", 1);
// 遍历操作(必须手动同步)
synchronized (syncMap) { // 关键同步块
for (Map.Entry<String, Integer> entry : syncMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
实现原理:
方案2:ConcurrentHashMap(分段锁/CAS)
ConcurrentHashMap<String, Integer> concurrentMap = new ConcurrentHashMap<>();
// 线程安全的put操作
concurrentMap.put("key", 1);
// 原子性复合操作
concurrentMap.compute("key", (k, v) -> v == null ? 1 : v + 1);
// 安全遍历(不会抛异常)
for (Map.Entry<String, Integer> entry : concurrentMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
JDK8+实现原理: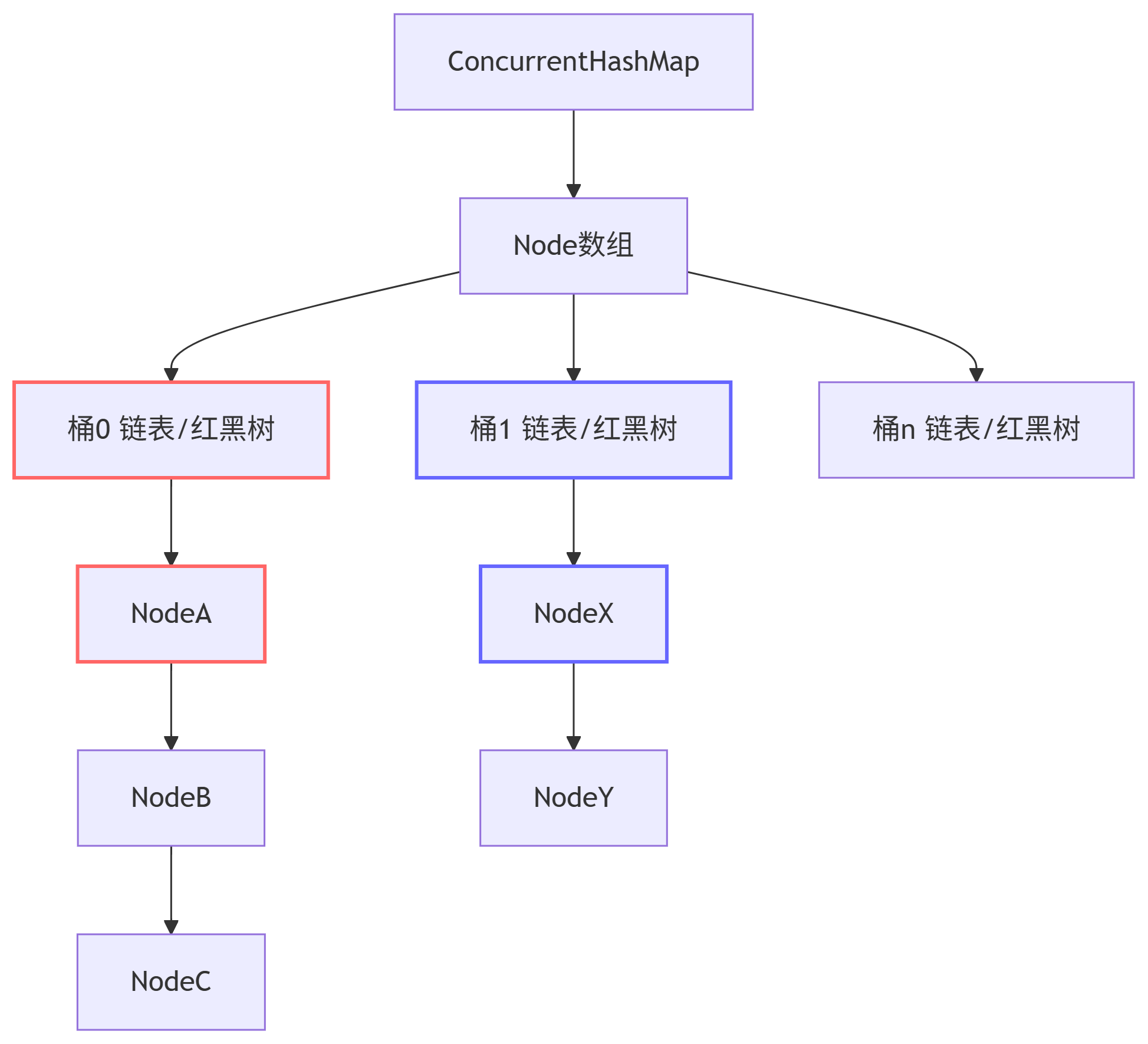
四、方案对比与选型指南
| 特性 | HashMap | Collections.synchronizedMap | ConcurrentHashMap |
|---|---|---|---|
| 线程安全 | ❌ | ✅ | ✅ |
| 锁粒度 | 无锁 | 全局锁 | 桶级锁 |
| 读性能 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 写性能(高并发) | ❌ | ⭐ | ⭐⭐⭐⭐ |
| 迭代器安全性 | Fail-Fast | Fail-Fast | Weakly Consistent |
| 是否需要遍历同步 | - | ✅ | ❌ |
| JDK版本要求 | 1.2+ | 1.2+ | 1.5+ |
选型建议:
-
单线程环境 →
HashMap -
低并发/强一致性需求 →
Collections.synchronizedMap -
高并发场景 →
ConcurrentHashMap(首选)
五、快速诊断指南:遇到ConcurrentModificationException怎么办?
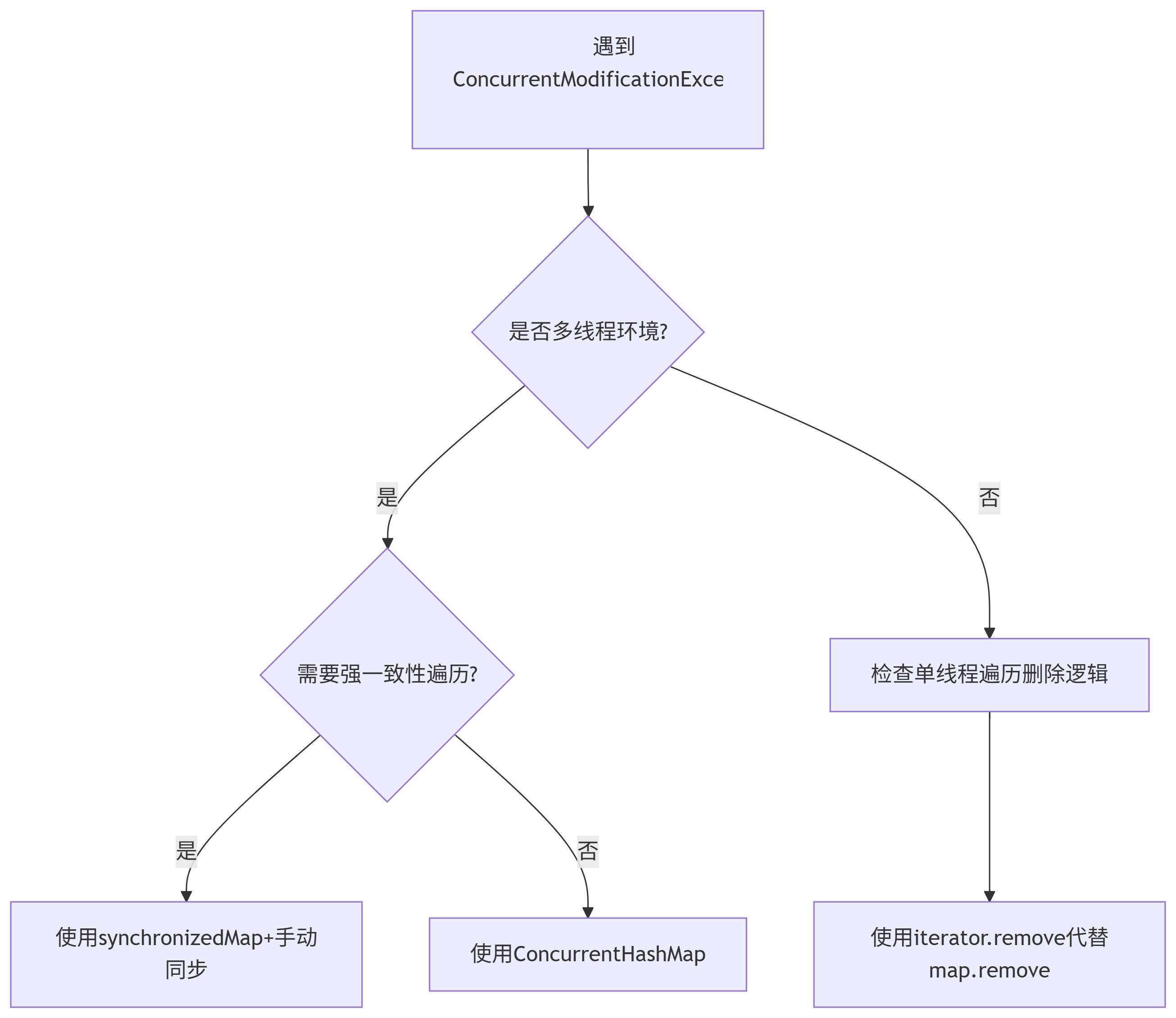
六、实战性能测试数据
测试环境:8核CPU,16GB内存,100万次操作
| 操作类型 | HashMap | synchronizedMap | ConcurrentHashMap |
|---|---|---|---|
| 10线程读 | 120ms | 450ms | 110ms |
| 10线程写 | 崩溃 | 780ms | 210ms |
| 5读5写混合 | 崩溃 | 620ms | 180ms |
结论:ConcurrentHashMap在高并发场景下性能优势明显
七、深度思考
-
为什么ConcurrentHashMap的size()方法返回的是近似值?
-
因避免全局锁,JDK8采用分片计数机制(
baseCount+CounterCell[]) -
实际开发中
mappingCount()比size()更推荐使用
-
-
ConcurrentHashMap弱一致性迭代器的实际影响?
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>(); map.put("A", 1); map.put("B", 2); Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator(); map.put("C", 3); // 迭代开始后添加新元素 while (it.hasNext()) { // 可能包含C,也可能不包含 System.out.println(it.next().getKey()); }
3.如何在ConcurrentHashMap中实现原子复合操作?
// 线程安全的累加操作
concurrentMap.compute("counter", (k, v) -> v == null ? 1 : v + 1);
// 仅当不存在时放入
concurrentMap.putIfAbsent("key", 100);
最佳实践总结:
单线程操作直接使用HashMap
低并发场景考虑synchronizedMap(注意遍历同步)
高并发场景首选ConcurrentHashMap
使用
ConcurrentHashMap的原子方法避免显式锁遍历时删除元素务必使用迭代器的
remove()方法
讨论话题:
-
你在项目中遇到过ConcurrentModificationException吗?如何解决的?
-
对于超高并发场景,ConcurrentHashMap还需要哪些优化?
-
除了文中方案,还有哪些线程安全的Map实现?(如
ConcurrentSkipListMap)
如果对你有帮助,欢迎点赞⭐收藏!如有疑问欢迎评论区交流~

















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









