







目录
参考文章:令人拍案叫绝的Wasserstein GAN - 知乎 (zhihu.com)
1 原始GAN存在问题
实际训练中,GAN存在着训练困难、生成器和判别器的loss无法指示训练进程、生成样本缺乏多样性等问题。这与GAN的机制有关。GAN最终达到对抗的纳什均衡只是一个理想状态,而现实情况中得到的结果都是中间状态(伪平衡)。
大部分的情况是,随着训练的次数越多判别器D的效果越好,会导致一直可以将生成器G的输出与真实样本区分开。这是因为生成器G是从低维空间向高维空间(复杂的样本空间)映射,其生成的样本分布空间Pg难以充满整个真实样本的分布空间Pr。即两个分布完全没有重叠的部分,或者它们重叠的部分可以忽略,这样就使得判别器D总会将它们分开。
在原始GAN的训练中,判别器训练得太好,会使生成器梯度消失,生成器loss降不下去;判别器训练得不好,会使生成器梯度不准,四处乱跑。只有判别器训练到中间状态最佳,但是这个尺度很难把握,没有一个收敛判断的依据。甚至在同一轮训练的前后不同阶段,这个状态出现的时段都不一样,是个完全不可控的情况。
引入Kullback–Leibler divergence(简称KL散度)和Jensen-Shannon divergence(简称JS散度)这两个重要的相似度衡量指标,后面的主角之一Wasserstein距离,就是要来吊打它们两个的。所以接下来介绍这两个重要的配角——KL散度和JS散度:
根据原始GAN定义的判别器loss,我们可以得到最优判别器的形式;而在最优判别器的下,我们可以把原始GAN定义的生成器loss等价变换为最小化真实分布与生成分布之间的JS散度。我们越训练判别器,它就越接近最优,最小化生成器的loss也就会越近似于最小化和之间的JS散度。
![]()
第一种loss形式无论跟是远在天边,还是近在眼前,只要它们俩没有一点重叠或者重叠部分可忽略,JS散度就固定是常数,而这对于梯度下降方法意味着——梯度为0!此时对于最优判别器来说,生成器肯定是得不到一丁点梯度信息的;即使对于接近最优的判别器来说,生成器也有很大机会面临梯度消失的问题。
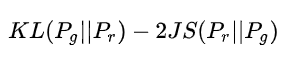
而第二种loss形式存在两个严重的问题。第一是它同时要最小化生成分布与真实分布的KL散度,却又要最大化两者的JS散度,一个要拉近,一个却要推远!这在直观上非常荒谬,在数值上则会导致梯度不稳定,这是后面那个JS散度项的毛病。
第一部分小结:在原始GAN的(近似)最优判别器下,第一种生成器loss面临梯度消失问题,第二种生成器loss面临优化目标荒谬、梯度不稳定、对多样性与准确性惩罚不平衡导致mode collapse这几个问题。
原始GAN问题的根源可以归结为两点,一是等价优化的距离衡量(KL散度、JS散度)不合理,二是生成器随机初始化后的生成分布很难与真实分布有不可忽略的重叠。
2 WGAN原理
WGan(Wasserstein Gan),Wasserstein是指Wasserstein距离,又叫Earth-Mover(EM)推土机距离,定义如下:


Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。WGAN本作通过简单的例子展示了这一点。考虑如下二维空间中的两个分布和,在线段AB上均匀分布,在线段CD上均匀分布,通过控制参数可以控制着两个分布的距离远近。
WGan的思想是将生成的模拟样本分布Pg与原始样本分布Pr组合起来,当成所有可能的联合分布的集合。然后可以从中采样得到真实样本与模拟样本,并能够计算二者的距离,还可以算出距离的期望值。

KL散度和JS散度是突变的,要么最大要么最小,Wasserstein距离却是平滑的,如果我们要用梯度下降法优化这个参数,前两者根本提供不了梯度,Wasserstein距离却可以。类似地,在高维空间中如果两个分布不重叠或者重叠部分可忽略,则KL和JS既反映不了远近,也提供不了梯度,但是Wasserstein却可以提供有意义的梯度。
使用W-GAN网络进行图像生成时,网络将整个图像视为一种属性,其目的就是学习图像整个属性的数据分布,因而将生成图像分布Pg拟合为真实图像分布Pr是合理可行的。若期望的生成分布Pg不是当前的真实图像分布Pr,那么网络具体的收敛方向将会不可控,会出现训练失败的情况。
这样就可以通过训练,让网络在所有可能的联合分布中对这个期望值取下界的方向优化,也就是将两个分布的集合拉到一起。这样原来的判别式就不再是判别真伪的功能了,而是计算两个分布集合距离的功能。所以将其称为评论器更加合适,同样,最后一层的sigmoid也需要去掉了。
核心思想:原始GAN的D的loss都是真实样本和1作交叉熵,模拟样本和0作交叉熵;G的loss是模拟样本和1作交叉熵。WGan的loss就是将真实样本和模拟样本形成联合分布,采样后给二者作差,D的目的是二者越大越好,G的目的是二者越小越好。

尽可能取到最大,此时L就会近似真实分布与生成分布之间的Wasserstein距离(忽略常数倍数)。注意原始GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在WGAN中的判别器做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。
接下来生成器要近似地最小化Wasserstein距离,可以最小化L,由于Wasserstein距离的优良性质,我们不需要担心生成器梯度消失的问题。再考虑到的第一项与生成器无关,就得到了WGAN的两个loss。

公式15是公式17的反,可以指示训练进程,其数值越小,表示真实分布与生成分布的Wasserstein距离越小,GAN训练得越好。
3 代码理解
WGAN与原始GAN第一种形式相比,只改了四点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
GAN代码的修改部分,具体区别可参照主页GAN代码进行对照:
- 因为变成回归任务,所以去掉Sigmoid函数。

- 删除Loss function。

- 不要用基于动量的优化算法(包括momentum和Adam),优化器改为RMSprop

- 保证fθ(x)fθ(x)满足K-Lipschitz条件,《Wasserstein GAN》做了一个简单地处理,因为判别器是由神经网络构成的,因此对每层的线性算子中参数做了一个夹逼,限制其取值范围,就可以实现。如上面代码的这个部分。clamp函数用于取上下限
# Clip weights of discriminator
for p in discriminator.parameters():
p.data.clamp_(-opt.clip_value, opt.clip_value)- 修改loss的计算方法:
loss_D = -torch.mean(discriminator(real_imgs)) + torch.mean(discriminator(fake_imgs))
loss_G = -torch.mean(discriminator(gen_imgs))GitHub源码
import argparse
import os
import numpy as np
import math
import sys
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.00005, help="learning rate")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--n_critic", type=int, default=5, help="number of training steps for discriminator per iter")
parser.add_argument("--clip_value", type=float, default=0.01, help="lower and upper clip value for disc. weights")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.shape[0], *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
validity = self.model(img_flat)
return validity
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.RMSprop(generator.parameters(), lr=opt.lr)
optimizer_D = torch.optim.RMSprop(discriminator.parameters(), lr=opt.lr)
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
batches_done = 0
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
fake_imgs = generator(z).detach()
# Adversarial loss
loss_D = -torch.mean(discriminator(real_imgs)) + torch.mean(discriminator(fake_imgs))
loss_D.backward()
optimizer_D.step()
# Clip weights of discriminator
for p in discriminator.parameters():
p.data.clamp_(-opt.clip_value, opt.clip_value)
# Train the generator every n_critic iterations
if i % opt.n_critic == 0:
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Generate a batch of images
gen_imgs = generator(z)
# Adversarial loss
loss_G = -torch.mean(discriminator(gen_imgs))
loss_G.backward()
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, batches_done % len(dataloader), len(dataloader), loss_D.item(), loss_G.item())
)
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
batches_done += 1














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









