




 本文探讨了时间序列异常检测的重要性和多种方法,包括STL分解、加性异常、时间变化、趋势和水平转移。介绍了CART、ARIMA、指数平滑法(如EWMA和Holt-Winters模型)以及神经网络在异常检测中的应用。这些方法各有优缺点,适用于不同类型的异常和时间序列数据。例如,STL适合季节性数据,CART和神经网络能处理复杂模式,而ARIMA则适用于趋势和周期性数据。
本文探讨了时间序列异常检测的重要性和多种方法,包括STL分解、加性异常、时间变化、趋势和水平转移。介绍了CART、ARIMA、指数平滑法(如EWMA和Holt-Winters模型)以及神经网络在异常检测中的应用。这些方法各有优缺点,适用于不同类型的异常和时间序列数据。例如,STL适合季节性数据,CART和神经网络能处理复杂模式,而ARIMA则适用于趋势和周期性数据。
时间序列异常检测:寻找相对于某个标准或常用信号的异常数据点。异常类型有多种,但只关注从业务角度来看最重要的异常类型,例如意外的峰值、下降、趋势变化和水平转移。
例如:网站跟踪用户,发现用户在短时间内增长极快,像一个峰值。这类异常被称为加性异常。当服务器宕机,短时间内会有零或很低的用户数量,这类异常通常被归类为时间变化。
异常检测算法通常要么在每个时间点上标记异常 / 非异常,要么预测某时间点的信号,测试这个时间点的值是否与预测值有足够的差异,从而将其视为异常。使用第二种方法,能够可视化一个置信区间,有助于理解为什么会出现异常并验证。
STL 分解:将时间序列数据表示成三个要素:季节性、趋势、残差。分析残差的背离程度,引入阈值作为预警依据。可以使用绝对中位差来作为阈值。优点是方法简单,对峰值异常较敏感,能结合滑动平均来检测周期性的异常。缺点是需要进行调参,不能检测剧烈变动的指标。
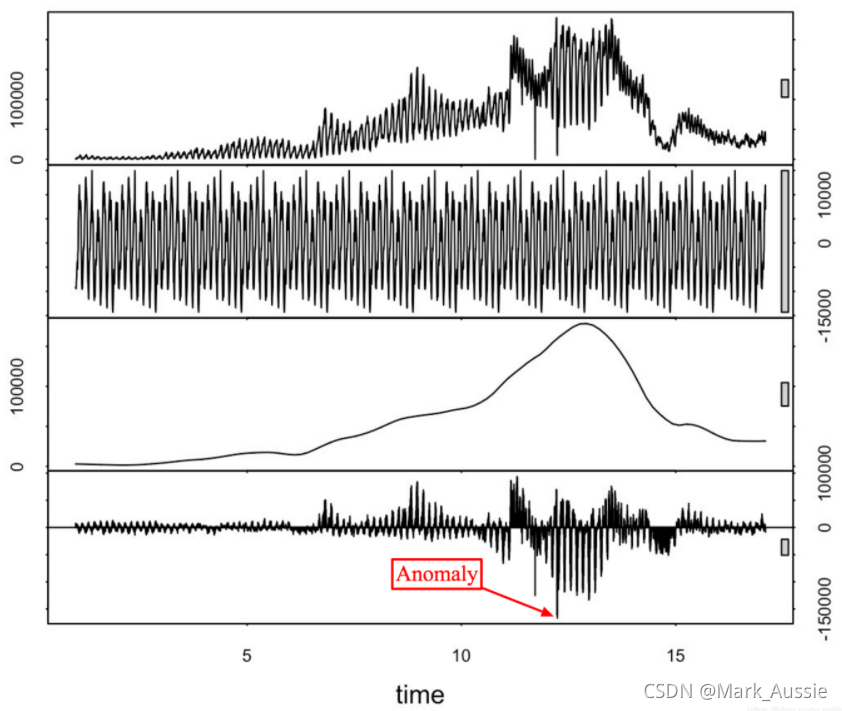
从上到下:利用STL分解检索原始时间序列、季节、趋势和残差部分。
顾名思义,它适用于季节性时间序列,这是最流行的情况。如果对残差进行分析并引入一定的阈值,就可以得到异常检测算法。使用中位数绝对偏差来获得更健壮的异常检测。
方法实现:mirrors / zrnsm / pyculiarity · CODE CHINA;
使用广义极端学生氏偏差测试检查是否一个残差点是一个离群点。
优点:简单、健壮。可处理许多不同情况,且所有的异常可以直观地解释。
主要用于检测加性异常值。检测电平变化,可以分析一些滚动平均信号而不是原始信号。
缺点:调整选项方面的僵化。能做的就是利用显著性水平调整置信区间。
最典型的情况是信号的特性发生了巨大的变化。例如,正在跟踪对公众关闭的网站上的用户,然后突然打开,此时应该分别跟踪在启动期之前和之后出现的异常。
分类与回归树:最健壮和最有效的机器学习技术之一;分类和回归树算法有两种使用方式:一是准备好已标记过异常点的数据集,进行监督型的机器学习;另一种让 CART 算法自动寻找数据集中的模式,预测异常点的置信区间,常用xgboost,可用各种特征学习和预测,计算量会因此上升。
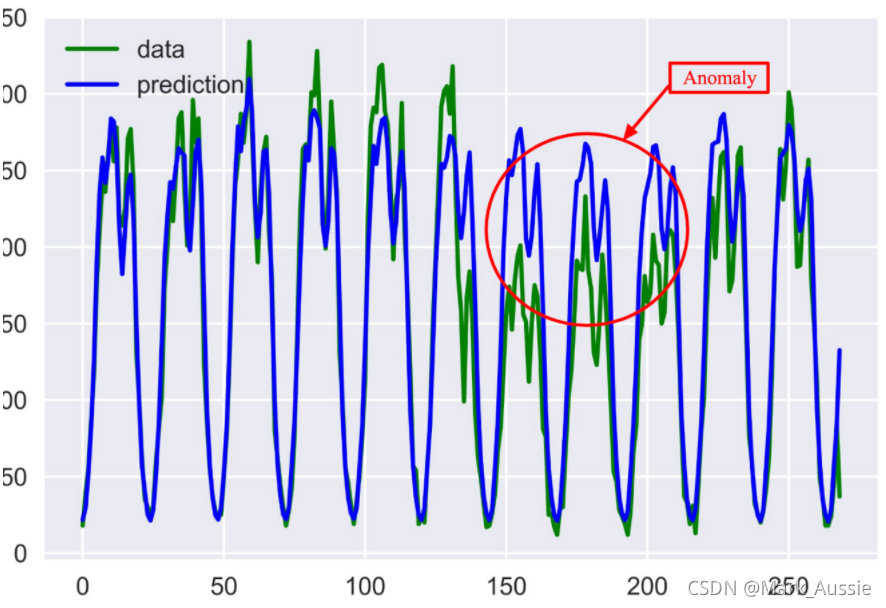
实际时间序列(绿色),CART模型预测的时间序列(蓝色),以及检测到偏离预测时间序列的异常。
优点:不受信号结构的任何约束,可以引入许多特征参数来执行学习并获得复杂的模型。
缺点:越多的特征会越快影响计算性能,此时需要选择特性。
ARIMA:方法简单且强大,可预测信号并发现异常,核心是从过去的几个点产生下一个点的预测加上一些随机变量,通常是白噪声,未来的预测点会产生新的点。对预测范围的明显影响是信号变得更平滑。难点在于要选择差异的数量、自回归的数量和预测误差系数。每次处理一个新信号时,都要构建一个新的ARIMA模型。另一个问题是信号应该是平稳的差分后,意味着信号不依赖时间(重要的限制)。异常检测利用离群点建立调整后的信号模型,利用 t 统计量检验模型的拟合是否优于原始模型。
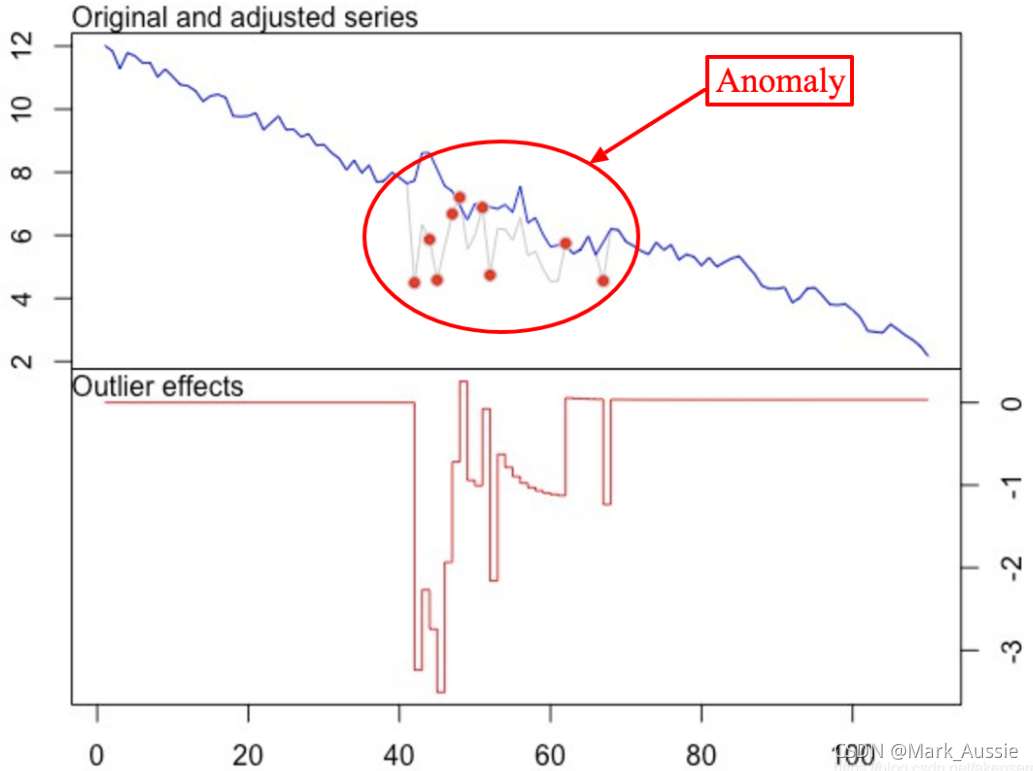
利用原始ARIMA模型建立了两个时间序列,对离群值ARIMA模型进行了调整。最佳实现是tsoutliers R包。适用于检测所有类型的异常情况,可以找到合适的ARIMA模型为需要的信号。
神经网络:CART一样,有两种方法可以应用神经网络:监督学习和非监督学习。
处理时间序列时,最合适的神经网络类型是LSTM,递归神经网络,如正确地构建,将允许在时间序列中建模最复杂的依赖关系,以及高级的季节性依赖关系。如果有多个时间序列相互耦合,这种方法也非常有用。
指数平滑法:与ARIMA方法相似。基本的指数模型相当于ARIMA(0,1,1)模型。
异常探测时,最又去的方法是冬季季节法,定义季节周期,如一个星期,一个月,一年,等等。
如需要跟踪几个季节周期,如同时具有周和年依赖项,则只选择一个。通常选最短的。
滑动平均(exponential moving average),也称:指数加权平均(exponentially weighted moving average),可估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关。
加权移动平均法是对观察值分别给予不同的权数,按不同权数求得移动平均值,以最后的移动平均值为基础,确定预测值。采用加权移动平均法,是因为观察期的近期观察值对预测值有较大影响,更能反映近期变化的趋势。
指数加权移动平均法,数值的加权系数随时间呈指数递减,越靠近当前时刻数值加权系数越大。
指数加权移动平均较传统的平均法来说,一是不需要保存过去所有的数值;二是计算量显著减小。
指数平滑法是特殊的加权平均法,加权的特点是对离预测值较近的历史数据给予较大的权重,对离预测期较远的历史数据给予较小的权重,权重由近到远按指数规律递减。
分为一次指数平滑法、二次指数平滑法及更高次指数平滑法。
一次指数平滑模型:EWMA
单指数模型(single-exponential), 和线性模型的思路类似,离当前点越远的点,重要性越低,具体化为数值的指数下降,对应的参数是alpha。
alpha值越小,下降越慢,默认的alpha=0.3;
计算模型:s2 = α * x2 + (1 - α) * s1
α是平滑系数,si(i=1,2...n)是前 i 个数据的平滑值,
α取值为[0,1],越接近1,平滑后的值越接近当前时间的数据值,数据越不平滑,
α越接近0,平滑后的值越接近前i个数据的平滑值,数据越平滑,
α的值通常可多尝试几次以达到最佳效果。
一次指数平滑算法进行预测的公式为:xi+h = si, i 为当前最后的一个数据记录的坐标,
即预测的时间序列为一条直线,不能反映时间序列的趋势和季节性。
二次平滑指数:Holt-Linear
计算模型:
s2 = α * x2 + (1 - α) * (s1 + t1)
t2 = ß * (s2 - s1) + (1 - ß) * t1
默认alpha = 0.3 and beta = 0.1
二次指数平滑保留了趋势信息,使预测的时间序列可以包含之前数据的趋势。
二次指数平滑的预测公式为 xi+h = si+hti, 二次指数平滑的预测结果是一条斜的直线。
三次平滑指数:Holt-Winters
三次指数平滑在二次指数平滑的基础上保留了季节性的信息,使得其可以预测带有季节性的时间序列。三次指数平滑添加了一个新的参数p来表示平滑后的趋势。
Additive Holt-Winters:Holt-Winters加法模型
累加的三次指数平滑:
k为周期,累加三次指数平滑的预测公式为: xi+h = si+hti+pi-k+(h mod k)
Multiplicative Holt-Winters:Holt-Winters乘法模型
累乘的三次指数平滑:
累乘三次指数平滑的预测公式为: xi+h = (si+hti)pi-k+(h mod k)
α,ß,γ 取值范围[0,1],s,t,p 初始值对算法整体影响不大,
通常的取值为 s0 = x0,t0 = x1 - x0,累加时p=0,累乘时p=1.
参考:
时间序列异常点检测_akenseren的博客-CSDN博客_时间序列异常检测

















 2413
2413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









