









JDK 6u45
Hadoop 0.20.203.0
首先,保证要征用的几台电脑在同一个网域内(即IPv4的前三个数字是一样的),建议适用静态IP以免每次启动更改hosts文件:
Master:192.168.1.2
Slave1:192.168.1.3
Slave2:192.168.1.4
1、更改IP:
Ubuntu的IP更改在右上角,如图:

选择“Edit Connections”,进入到下图:
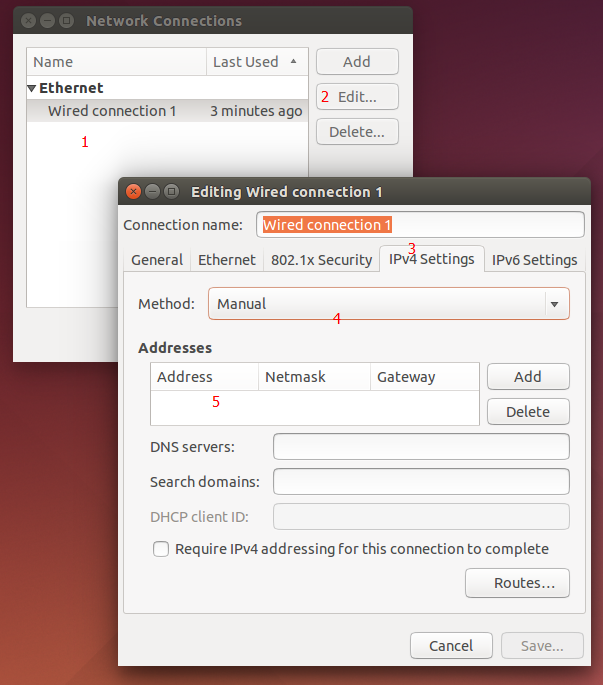
选中你的网络,然后点击旁边的Edit,选择IPv4Settings选项卡,选择Manual(静态),然后填写你的网络信息,保存退出重新连接即可
2、更改计算机名:
确保每一台电脑都有一个相同的用户名,如果不一样,请创建一个新的用户。以下是更改计算机名的方法:
打开hosts文件:
sudo gedit /etc/hosts
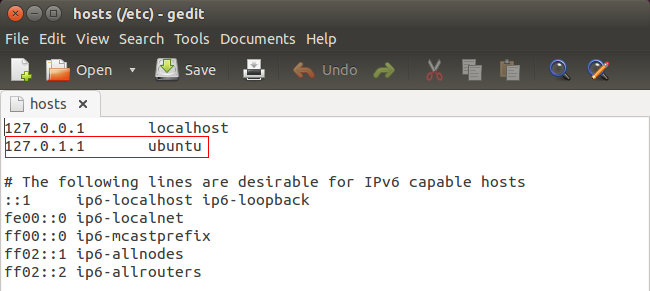
将红框处的信息删掉,然后仿照第一排,加入自己电脑的IP地址和自己想取的计算机名(也就是@后面的那个名字),此处笔者更改如下:
192.168.1.2 Master
同时,也一次性将其它从节点的IP和计算机名加到其中,最后内容如下:
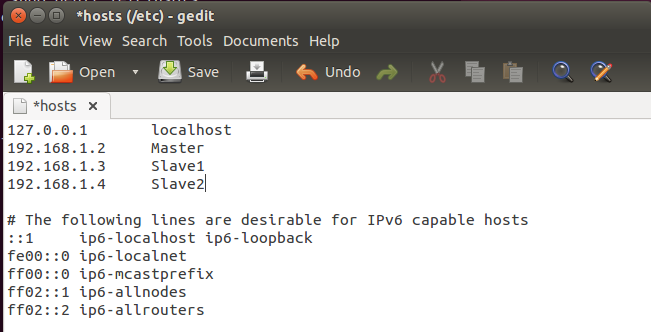
保存退出
然后打开hostname文件:
sudo gedit /etc/hostname
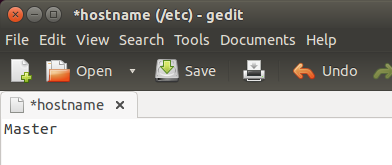
验证是否成功:
ping Slave1几台电脑之间能够相互ping通就说明成功
3、配置SSH无密码登录:
①安装SSH服务:
sudo apt-get install openssh-server有可能不成功,如果不成功,请先更新下系统:
sudo apt-get update②配置各台电脑自己的无密码登录:
执行命令:
ssh-keygen -t rsa -P ""路径确认的时候直接回车,默认路径即可(/home/hadoop/.ssh/id_rsa,这是笔者的路径)。
退到home目录下,进入.ssh文件夹:
cd .ssh把id_rsa.pub追加到授权的key里去,执行如下语句:
cat id_rsa.pub >> authorized_keys</span>authorized_keys文件本来不存在,但执行这条命令后它将自动生成
执行完后更改authorized_keys的权限为600,否则之后要出错(一定要改),如果.ssh文件夹是自己创建而不是在生成密码时自动创建的,那.ssh的权限也要改,改成700。
sudo chmod 600 authorized_keys完成后可以用ssh localhost验证一下。
其余Slave也如此配置
③配置Master无密码登录各Slave:
将Master的id_rsa.pub追加到各Slave的authorized_keys文件中即可。
首先将Master的id_rsa.pub文件远程复制到各Slave上(此时依然在.ssh文件夹中):
scp id_rsa.pub hadoop@Slave1:~/
scp id_rsa.pub hadoop@Slave2:~/④配置各Slave无密码登录Master:
此过程为③的逆过程,将各Slave的id_rsa.pub文件追加到Master的authorized_keys文件里即可
以下过程均以Master为例,配置好后将其分发到各Slave即可
4、JDK和Hadoop的安装请参考如下连接:
http://blog.csdn.net/marshal0826/article/details/18178591
请先看这个链接里的内容,因为集群分布的配置和伪分布差不过,下面的内容仅是与伪分布配置的不同之处。
5、配置hadoop,以Master为例(这些文件都在hadoop文件夹的conf文件夹中,请先进入这个文件夹。再提醒各位读者,下面的内容千万别照抄)
①配置core-site.xml:
打开core-site.xml文件:
sudo gedit core-site.xml在<configuration>和</configuration>之间添加如下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://Master:9000</value> //这里Master代替的就是你的IP,所以可以将Master换成IP,但如果IP一变动,这个文件也要改
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/tmp</value> //这也要改哦
</property></span>保存退出
②配置hdfs-site.xml:
打开这个文件,在<configuration>和</configuration>之间添加如下内容:dfsg
<property>
<name>dfs.replication</name>
<value>2</value> //如果大于3,则从节点不能低于3个,这里设置成2,因为只有两个从节点
</property>
<property>
//用于存放主节点的信息,比如fsimage文件(这个文件相当重要,没有他无法读取HDFS的内容),一般设置多个地址,
//只需在<value>与</value>之间以逗号分隔每个地址
<name>dfs.name.dir</name>
<value>/home/hadoop/hadoop/namedata</value>
</property>
<property>
//设置从节点数据的存放位置,也可以设置多个
<name>dfs.data.dir</name>
<value>/home/hadoop/hadoop/data</value>
</property></span>保存退出
③配置mapred-site.xml:
打开这个文件,在<configuration>和</configuration>之间添加如下内容:
<property>
<name>mapred.job.tracker</name>
<value>Master:9001</value>//此处和core-site.xml差不多
</property>
//以下内容可以暂时不用设置,但从经验来看,还是设置一下为好
<property>
//一个节点上最大能运行的Map数量(默认是两个,但从经验来看,如果数据量大而机器又旧,两个是带不起来的)
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>1</value>
</property>
<property>
//每个节点最大能运行的reduce数量,默认是1个,这里写出来是为了让大家知道在哪里改这个数据
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>1</value>
</property>
<property>
//我相信大家一定会遇到“java heap space”的问题,除非各位是算法高手,并且机器内存很大
//这个用于设置程序运行时(jvm虚拟机)的内存容量
<name>mapred.child.java.opts</name>
<value>-Xmx4096m</value>
</property></span>④配置masters文件:
打开这个文件,删掉localhost,添加Master的计算机名,笔者的Master的计算机名就叫Master,更改后保存退出保存退出。
⑤配置slaves文件:
将各Slave的计算机名添加到slaves文件中,一个名字一行,保存退出。
至此,Master上的hadoop配置完成,而各Slave上的hadoop配置,如果大家不闲麻烦,可以挨个配置,毕竟只有两三台嘛,就当是熟悉熟悉配置,但也可以用远程复制,命令如下:
scp -r '/home/hadoop/hadoop' hadoop@Slave1:~/
scp -r '/home/hadoop/hadoop' hadoop@Slave2:~/注意:不要单纯的复制就完事,上述文件中牵扯到文件地址的地方都要改成Slave节点上的地址(core-site.xml和hdfs-site.xml文件)。
5、格式化并启动hadoop:
执行如下格式化语句:
hadoop namenode -format执行启动语句启动hadoop:
start-all.sh在Master上用jps查看进程,可以看到JobTracker,NameNode,Jps和SecondaryNameNode四个进程(顺序无关紧要),在Slave上用jps可以看到TaskTracker,Jps和DataNode三个进程,如此,hadoop集群式配置分布成功。
也可以在网页上查看集群,浏览器地址栏中输入Master:50070和Master:50030即可
写下此文仅为记录之用,免得以后配置再去到处找资料。读者可以参考下面的连接,下面的很专业,但是是在CentOS上配置的,读者可以结合起来看:
http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html
http://www.cnblogs.com/xia520pi/archive/2012/04/08/2437875.html















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









