






urllib模块提供的上层接口,使我们可以像读取本地文件一样读取www和ftp上的数据,
在python3中urllib模块导入不能直接import urllib 而要import urllib .request。
1、基本方法
# -*- encoding: utf-8 -*-
import urllib .request
url='https://www.veer.com/favorites/165850_67290_d04868dbc0e84c8dad3335c3f4152800'
#直接用urllib.request模块的urlopen()获取页面
response=urllib .request.urlopen(url) #返回HTTPResponse类型
page=response.read() #读取页面,page的数据格式为bytes类型,需要decode()解码,转换成str类型
page = page.decode('utf-8')
urlopen返回对象提供方法:
- read() , readline() ,readlines() , fileno() , close() :对HTTPResponse类型数据进行操作
- info():返回HTTPMessage对象,表示远程服务器返回的头信息
- getcode():返回Http状态码。如果是http请求,200请求成功完成;404网址未找到
- geturl():返回请求的url
2.使用Request
urllib.request.Request(url, data=None, headers={}, method=None)
使用request()来包装请求,再通过urlopen()获取页面。
# -*- encoding: utf-8 -*-
import urllib .request
#直接用urllib.request模块的urlopen()获取页面
url='https://www.veer.com/favorites/165850_67290_d04868dbc0e84c8dad3335c3f4152800'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36' }
req = urllib .request.Request(url, headers=headers) #包装请求
response=urllib .request.urlopen(req) #返回HTTPResponse类型
page=response.read() #读取页面,page的数据格式为bytes类型,需要decode()解码,转换成str类型
page = page.decode('utf-8')
urlopen()的data参数默认为None,当data参数不为空的时候,urlopen()提交方式为Post。这里先不讲post方式的请求。
先来说一说HTTP的异常处理问题:
当urlopen不能够处理一个response时,产生urlError。不过通常的Python APIs异常如ValueError,TypeError等也会同时产生。HTTPError是urlError的子类,通常在特定HTTP URLs中产生。
1.URLError
通常,URLError在没有网络连接(没有路由到特定服务器),或者服务器不存在的情况下产生。
这种情况下,异常同样会带有"reason"属性,它是一个tuple(可以理解为不可变的数组),
包含了一个错误号和一个错误信息。
from urllib import request,error
try:
photo=urllib.request.urlopen(image_href)
except error.URLError as e:
print(image_href+'页面不存在!!!')
print(e.reason)
2:HTTPError
程序功能:"""
HTTPError 子类
URLError 父类
先捕获子类的错误后捕获父类的错误
"""
from urllib import request,error
try:
response = request.urlopen('http://jiajiknag.com/index.html')
except error.HTTPError as e:
print(e.reason,e.code,e.headers,sep='\n')
except error.URLError as e:
print(e.reason)
else:
print('Request.Sucessfully')
参考链接:https://blog.csdn.net/Jiajikang_jjk/article/details/82758880
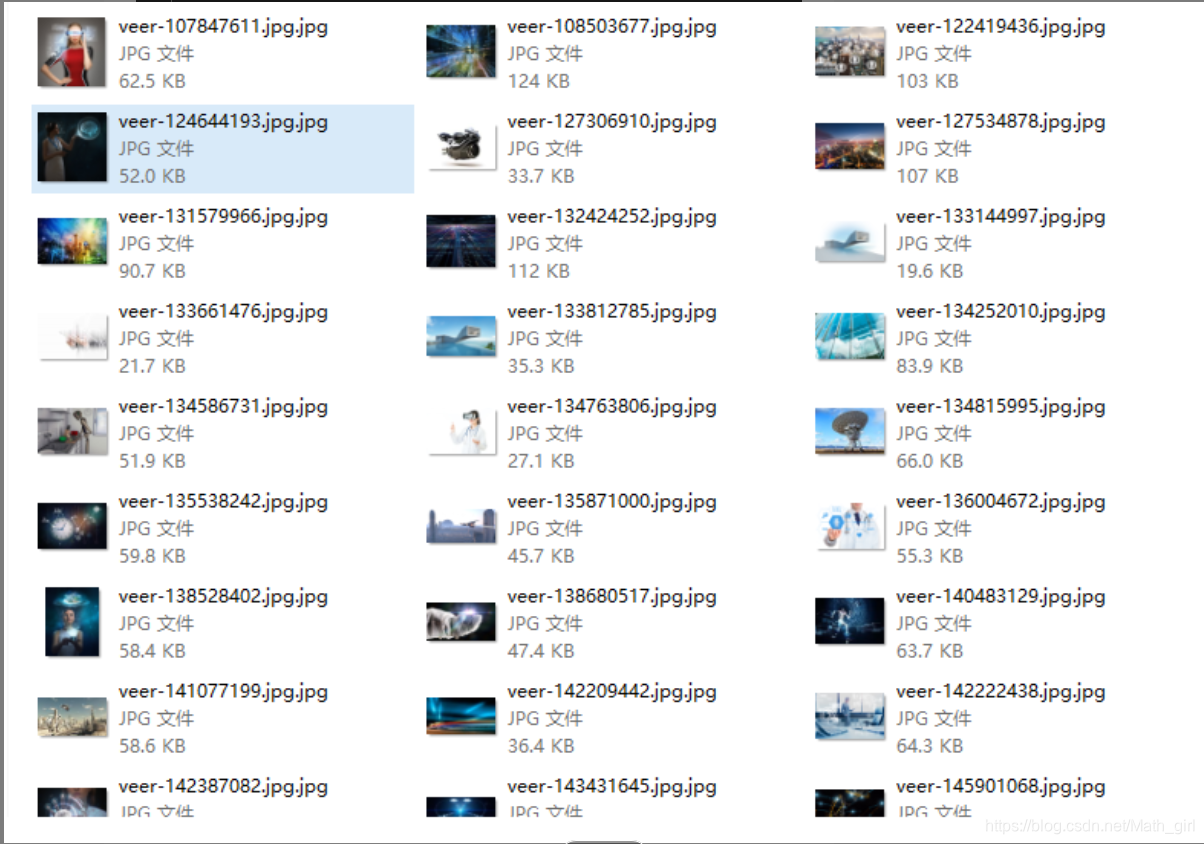
下面附上自己写的一个爬取网页批量下载图片的代码:
# -*- encoding: utf-8 -*-
import urllib .request
import re
from urllib import request,error
def open_url(inner_url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36' }
req = urllib .request.Request(inner_url, headers=headers) #包装请求
response=urllib .request.urlopen(req) #返回HTTPResponse类型
page=response.read().decode('utf-8') #读取页面,page的数据格式为bytes类型,需要decode()解码,转换成str类型
return page
def get_image(inner_page):
#正则匹配
p = r'src="([^"]+\.jpg)"'
links_list = re.findall(p, inner_page)
for each in links_list:
# 以/为分隔符,-1返回最后一个值
filename = each.split("/")[-1]
prestr = 'https:'
image_href = prestr + each
try:
#读取图片url
photo=urllib.request.urlopen(image_href)
except error.HTTPError as e:
print(e.reason, e.code, e.headers, sep='\n')
print(image_href)
except error.URLError as e:
print(image_href+'页面不存在!!!')
else:
print('Request.Sucessfully')
w=photo.read()
# 打开指定文件,并允许写入二进制数据
f = open('E://image//' + filename + '.jpg', 'wb') #参数wb表示以二进制格式打开一个文件只用于写入
# 写入获取的数据
f.write(w)
#关闭文件
f.close()
if __name__=='__main__':
url = "https://www.veer.com/favorites/165850_67290_d04868dbc0e84c8dad3335c3f4152800"
html=open_url(url)
get_image(html)














 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









