







https://zhuanlan.zhihu.com/p/56699895
前言
在SOA、微服务架构流行的年代,许多复杂业务上需要支持多资源占用场景,而在分布式系统中因为某个资源不足而导致其它资源占用回滚的系统设计一直是个难点。我所在的团队也遇到了这个问题,为解决这个问题上,团队采用的是阿里开源的分布式中间件Fescar的解决方案,并详细了解了Fescar内部的工作原理,解决在使用Fescar中间件过程中的一些疑虑的地方,也为后续团队在继续使用该中间件奠定理论基础。
目前分布式事务解决方案基本是围绕两阶段提交模式来设计的,按对业务是有侵入分为:对业务无侵入的基于XA协议的方案,但需要数据库支持XA协议并且性能较低;对业务有侵入的方案包括:TCC等。Fescar就是基于两阶段提交模式设计的,以高效且对业务零侵入的方式,解决微服务场景下面临的分布式事务问题。Fescar设计上将整体分成三个大模块,即TM、RM、TC,具体解释如下:
- TM(Transaction Manager):全局事务管理器,控制全局事务边界,负责全局事务开启、全局提交、全局回滚。
- RM(Resource Manager):资源管理器,控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。
- TC(Transaction Coordinator):事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。
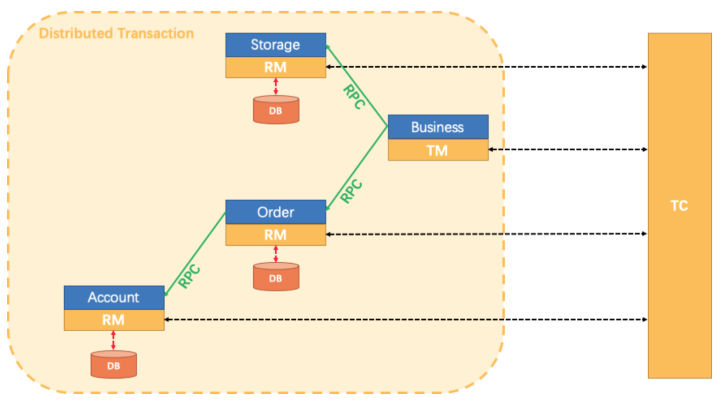
本文将深入到Fescar的RM模块源码去介绍Fescar是如何在完成分支提交和回滚的基础上又做到零侵入,进而极大方便业务方进行业务系统开发。
一、从配置开始解读
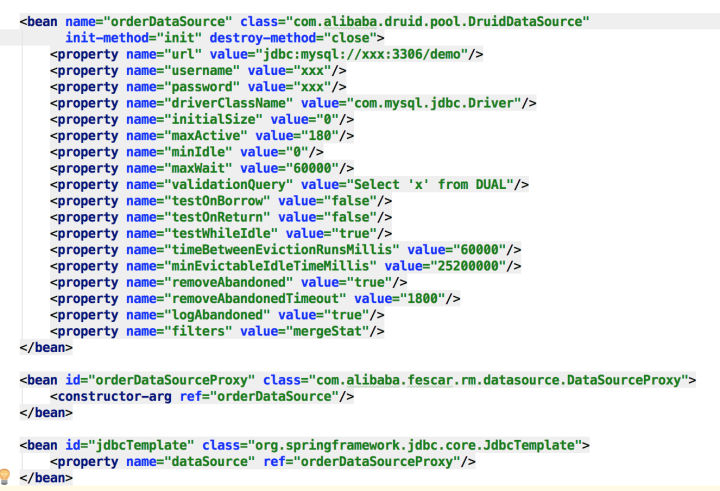
上图是Fescar源码examples模块dubbo-order-service.xml内的配置,数据源采用druid的DruidDataSource,但实际jdbcTemplate执行时并不是用该数据源,而用的是Fescar对DruidDataSource的代理DataSourceProxy,所以,与RM相关的代码逻辑基本上都是从DataSourceProxy这个代理数据源开始的。
Fescar采用2PC来完成分支事务的提交与回滚,具体怎么做到的呢,下面就分别介绍Phase1、Phase2具体做了些什么。
二、Phase1—分支(本地)事务执行
Fescar将一个本地事务做为一个分布式事务分支,所以若干个分布在不同微服务中的本地事务共同组成了一个全局事务,结构如下。
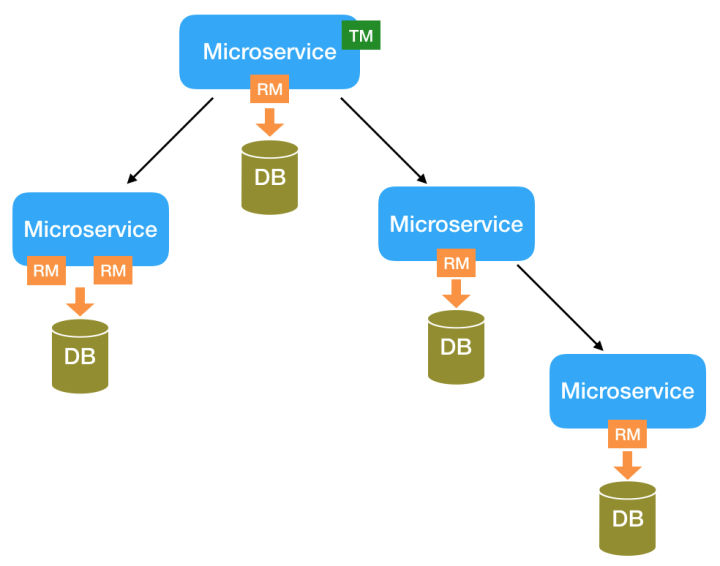
那么,一个本地事务中SQL是如何执行呢?在Spring中,本质上都是从jdbcTemplate开始的,比如下面的SQL语句:
jdbcTemplate.update("update storage_tbl set count = count - ? where commodity_code = ?", new Object[] {count, commodityCode});一般JdbcTemplate执行流程如下图所示:
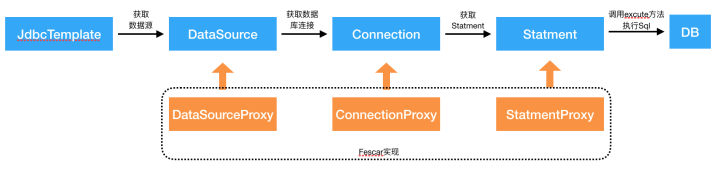
由于在配置中,JdbcTemplate数据源被配置成了Fescar实现DataSourceProxy,进而控制了后续的数据库连接使用的是Fescar提供的ConnectionProxy,Statment使用的是Fescar实现的StatmentProxy,最终Fescar就顺理成章地实现了在本地事务执行前后增加所需要的逻辑,比如:完成分支事务的快照记录和分支事务执行状态的上报等等。
DataSourceProxy获取ConnectionProxy:
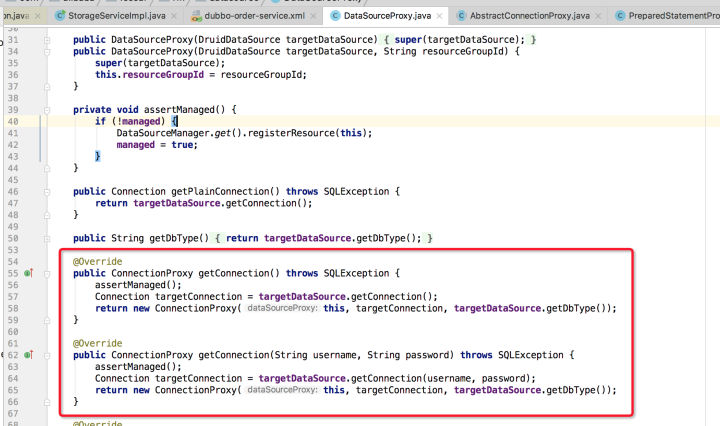
ConnectionProxy获取StatmentProxy:
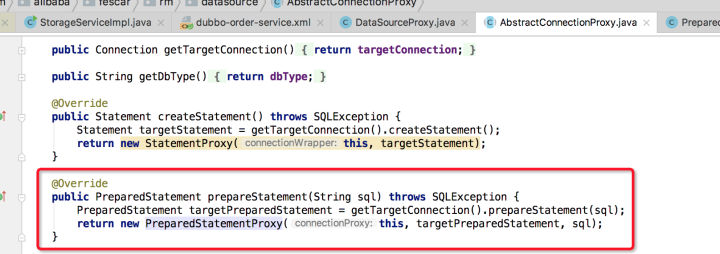
在获取到StatmentProxy后,可以调用excute方法执行sql了

而真正excute实现逻辑如下:
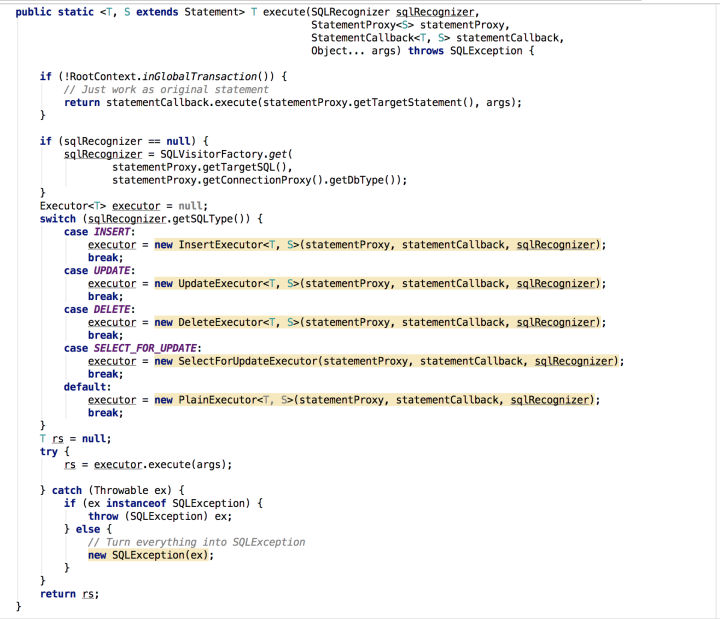
- 首先会检查当前本地事务是否处于全局事务中,如果不处于,直接使用默认的Statment执行,避免因引入Fescar导致非全局事务中的SQL执行性能下降。
- 解析Sql,有缓存机制,因为有些sql解析会比较耗时,可能会导致在应用启动后刚开始的那段时间里处理全局事务中的sql执行效率降低。
- 对于INSERT、UPDATE、DELETE、SELECT..FOR UPDATE这四种类型的sql会专门实现的SQL执行器进行处理,其它SQL直接是默认的Statment执行。
- 返回执行结果,如有异常则直接抛给上层业务代码进行处理。
再来看一下关键的INSERT、UPDATE、DELETE、SELECT..FOR UPDATE这四种类型的sql如何执行的,先看一下具体类图结构:
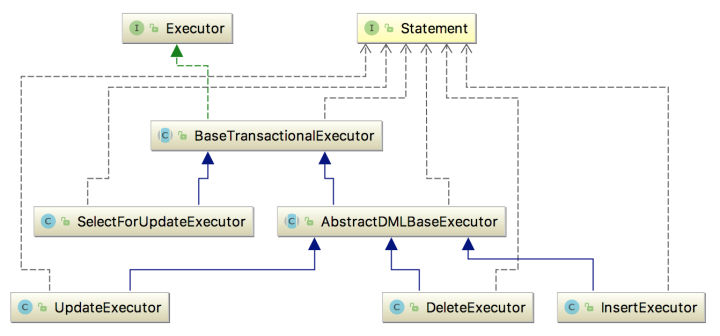
为结省篇幅,选择UpdateExecutor实现源码看一下,先看入口BaseTransactionalExecutor.execute,该方法将ConnectionProxy与Xid(事务ID)进行绑定,这样后续判断当前本地事务是否处理全局事务中只需要看ConnectionProxy中Xid是否为空。
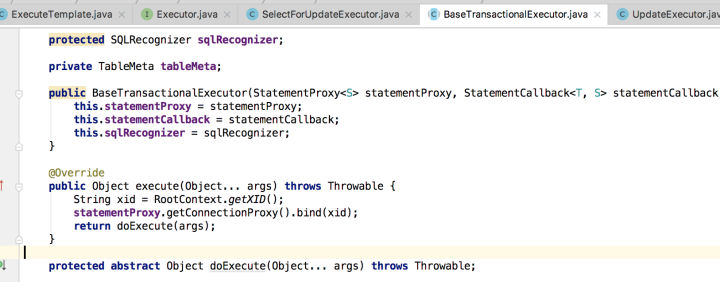
然后,执行AbstractDMLBaseExecutor中实现的doExecute方法
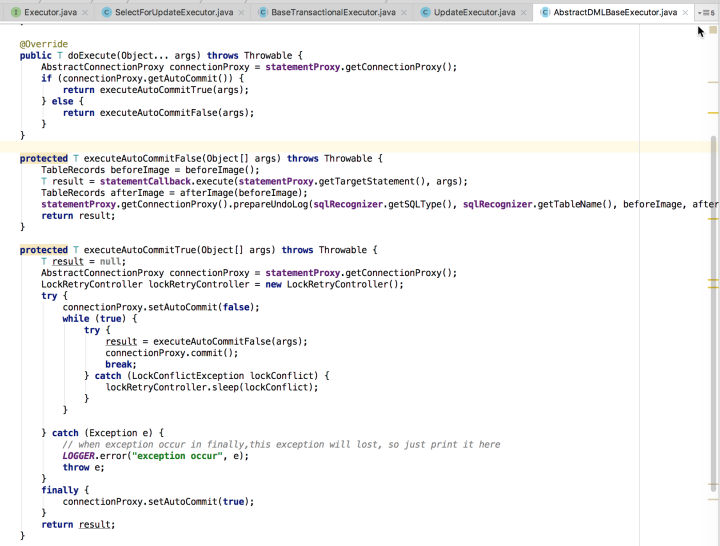
基本逻辑如下:
- 先判断是否为Auto-Commit模式
- 如果非Auto-Commit模式,则先查询Update前对应行记录的快照beforeImage,再执行Update语句,完成后再查询Update后对应行记录的快照afterImage,最后将beforeImage、afterImage生成UndoLog追加到Connection上下文ConnectionContext中。(注:获取beforeImage、afterImage方法在UpdateExecutor类下,一般是构造一条Select...For Update语句获取执行前后的行记录,同时会检查是否有全局锁冲突,具体可参考源码)
- 如果是Auto-Commit模式,先将提交模式设置成非自动Commit,再执行2中的逻辑,再执行connectionProxy.commit()方法,由于执行2过程和commit时都可能会出现全局锁冲突问题,增加了一个循环等待重试逻辑,最后将connection的模式设置成Auto-Commit模式
如果本地事务执行过程中发生异常,业务上层会接收到该异常,至于是给TM模块返回成功还是失败,由业务上层实现决定,如果返回失败,则TM裁决对全局事务进行回滚;如果本地事务执行过程未发生异常,不管是非Auto-Commit还是Auto-Commit模式,最后都会调用connectionProxy.commit()对本地事务进行提交,在这里会创建分支事务、上报分支事务的状态以及将UndoLog持久化到undo_log表中,具体代码如下图:
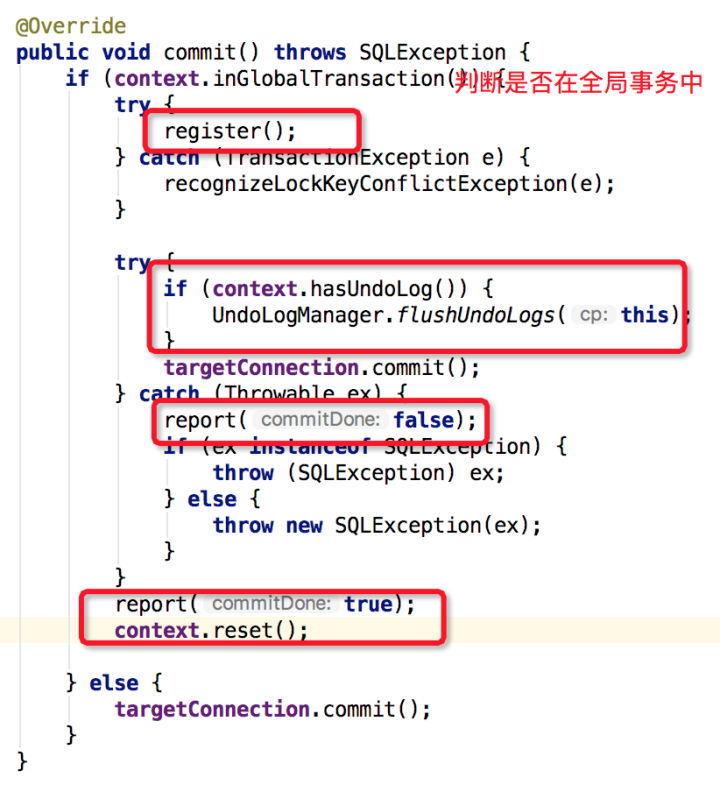
基本逻辑:
- 判断当前本地事务是否处于全局事务中(也就判断ConnectionContext中的xid是否为空)。
- 如果不处于全局事务中,则调用targetConnection对本地事务进行commit。
- 如果处于全局事务中,首先创建分支事务,再将ConnectionContext中的UndoLog写入到undo_log表中,然后调用targetConnection对本地事务进行commit,将UndoLog与业务SQL一起提交,最后上报分支事务的状态(成功 or 失败),并将ConnectionContext上下文重置。
综上所述,RM模块通过对JDBC数据源进行代理,干预业务SQL执行过程,加入了很多流程,比如业务SQL解析、业务SQL执行前后的数据快照查询并组织成UndoLog、全局锁检查、分支事务注册、UndoLog写入并随本地事务一起Commit、分支事务状态上报等。通过这种方式,Fescar真正做到了对业务代码无侵入,只需要通过简单的配置,业务方就可以轻松享受Fescar所带来的功能。Phase1整体流程引用Fescar官方图总结如下:
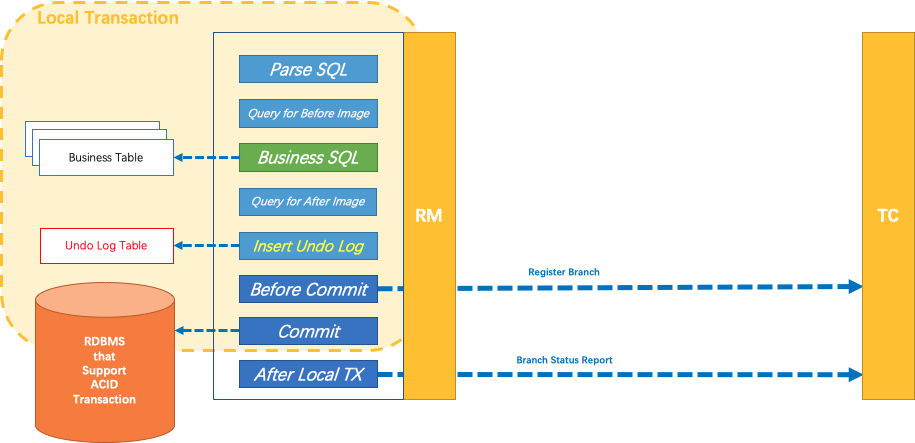
三、Phase2-分支事务提交或回滚
阶段2完成的是全局事物的最终提交或回滚,当全局事务中所有分支事务全部完成并且都执行成功,这时TM会发起全局事务提交,TC收到全全局事务提交消息后,会通知各分支事务进行提交;同理,当全局事务中所有分支事务全部完成并且某个分支事务失败了,TM会通知TC协调全局事务回滚,进而TC通知各分支事务进行回滚。
在业务应用启动过程中,由于引入了Fescar客户端,RmRpcClient会随应用一起启动,该RmRpcClient采用Netty实现,可以接收TC消息和向TC发送消息,因此RmRpcClient是与TC收发消息的关键模块。
public class RMClientAT {
public static void init(String applicationId, String transactionServiceGroup) {
RmRpcClient rmRpcClient = RmRpcClient.getInstance(applicationId, transactionServiceGroup);
AsyncWorker asyncWorker = new AsyncWorker();
asyncWorker.init();
DataSourceManager.init(asyncWorker);
rmRpcClient.setResourceManager(DataSourceManager.get());
rmRpcClient.setClientMessageListener(new RmMessageListener(new RMHandlerAT()));
rmRpcClient.init();
}
}上述代码展示是的RmRpcClient初始化过程,有三个关键类RMHandlerAT、AsyncWorker和DataSourceManager。RMHandlerAT具有了分支提交和回滚两个方法,分支提交或回滚的逻辑可以从这里开始看;AsyncWorker是一个异步Worker,主要是完成分支事务异步提交的功能,具有失败重试功能;DataSourceManager对数据源管理和维护。
下面分成两部分来讲:分支事务提交、分去事务回滚。
3.1、分支事务提交
在接收到TC发起的全局提交消息后,经RmRpcClient对通信协议的处理,再交由RMHandlerAT来完成对分支事务的提交,分支事务提交从RMHandlerAT.doBranchCommit()开始,但最后由AsyncWorker异步Worker完成,直接看AsyncWorker中的代码实现:
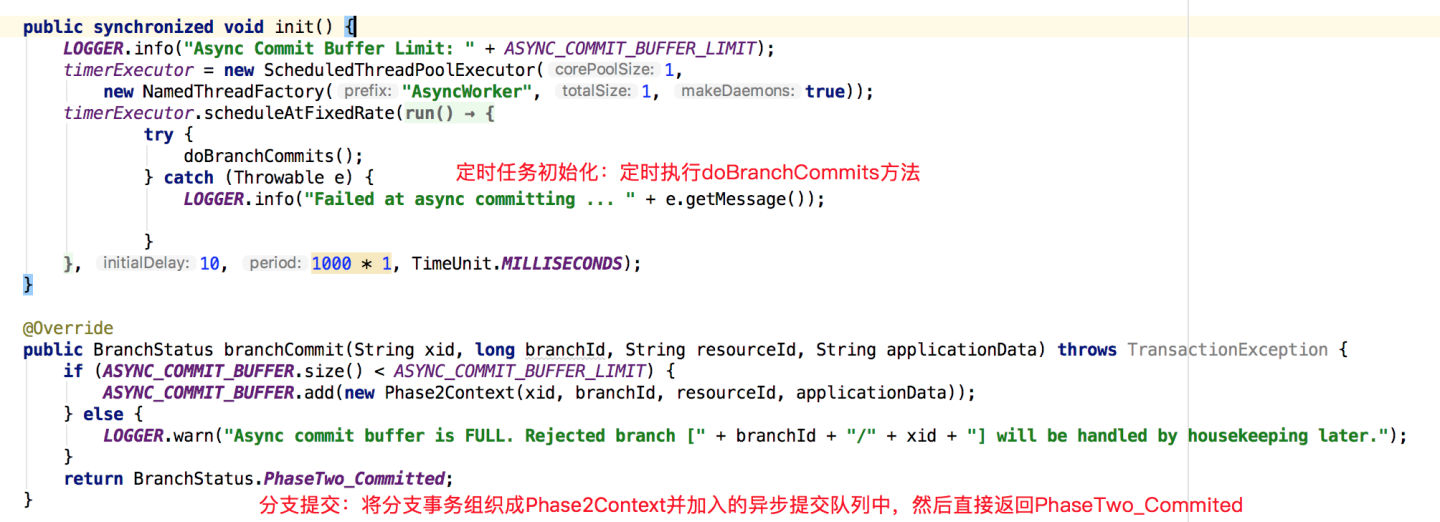
分支事务提交关键逻辑在doBranchCommits方法中:
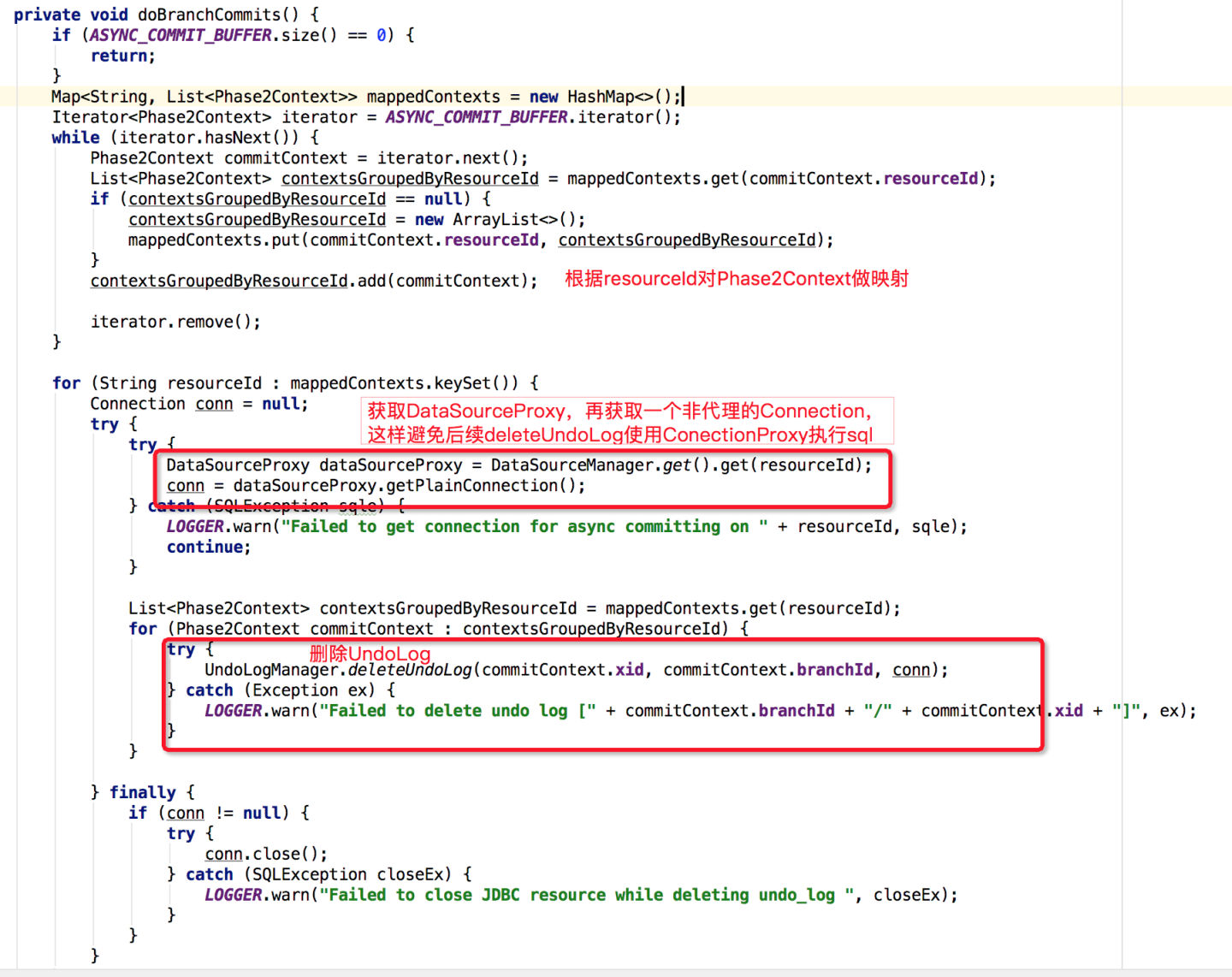
该方法主要是批量删除UndoLog日志,但并未使用ConnectionProxy去执行删除SQL,可能原因是:1、完全没必要 2、考虑效率优先
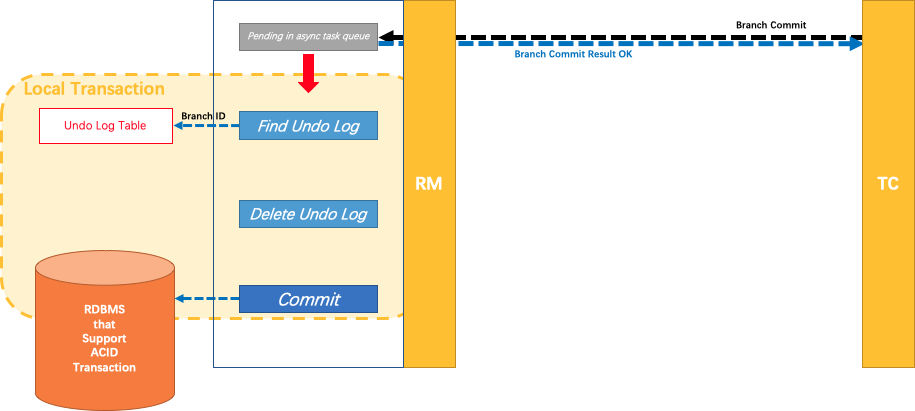
同样,对于分支事务提交也引用Fescar官方一张图来结尾:
3.2、分支事务回滚
同样,分支事务回滚是从RMHandlerAT.doBranchRollback开始的,然后到了dataSourceManager.branchRollback,最后完成分支事务回滚逻辑的是UndoLogManager.undo方法。
@Override
protected void RMHandlerAT:doBranchRollback(BranchRollbackRequest request, BranchRollbackResponse response) throws TransactionException {
String xid = request.getXid();
long branchId = request.getBranchId();
String resourceId = request.getResourceId();
String applicationData = request.getApplicationData();
LOGGER.info("AT Branch rolling back: " + xid + " " + branchId + " " + resourceId);
BranchStatus status = dataSourceManager.branchRollback(xid, branchId, resourceId, applicationData);
response.setBranchStatus(status);
LOGGER.info("AT Branch rollback result: " + status);
}
@Override
public BranchStatus DataSourceManager:branchRollback(String xid, long branchId, String resourceId, String applicationData) throws TransactionException {
DataSourceProxy dataSourceProxy = get(resourceId);
if (dataSourceProxy == null) {
throw new ShouldNeverHappenException();
}
try {
UndoLogManager.undo(dataSourceProxy, xid, branchId);
} catch (TransactionException te) {
if (te.getCode() == TransactionExceptionCode.BranchRollbackFailed_Unretriable) {
return BranchStatus.PhaseTwo_RollbackFailed_Unretryable;
} else {
return BranchStatus.PhaseTwo_RollbackFailed_Retryable;
}
}
return BranchStatus.PhaseTwo_Rollbacked;
}UndoLogManager.undo方法源码如下:
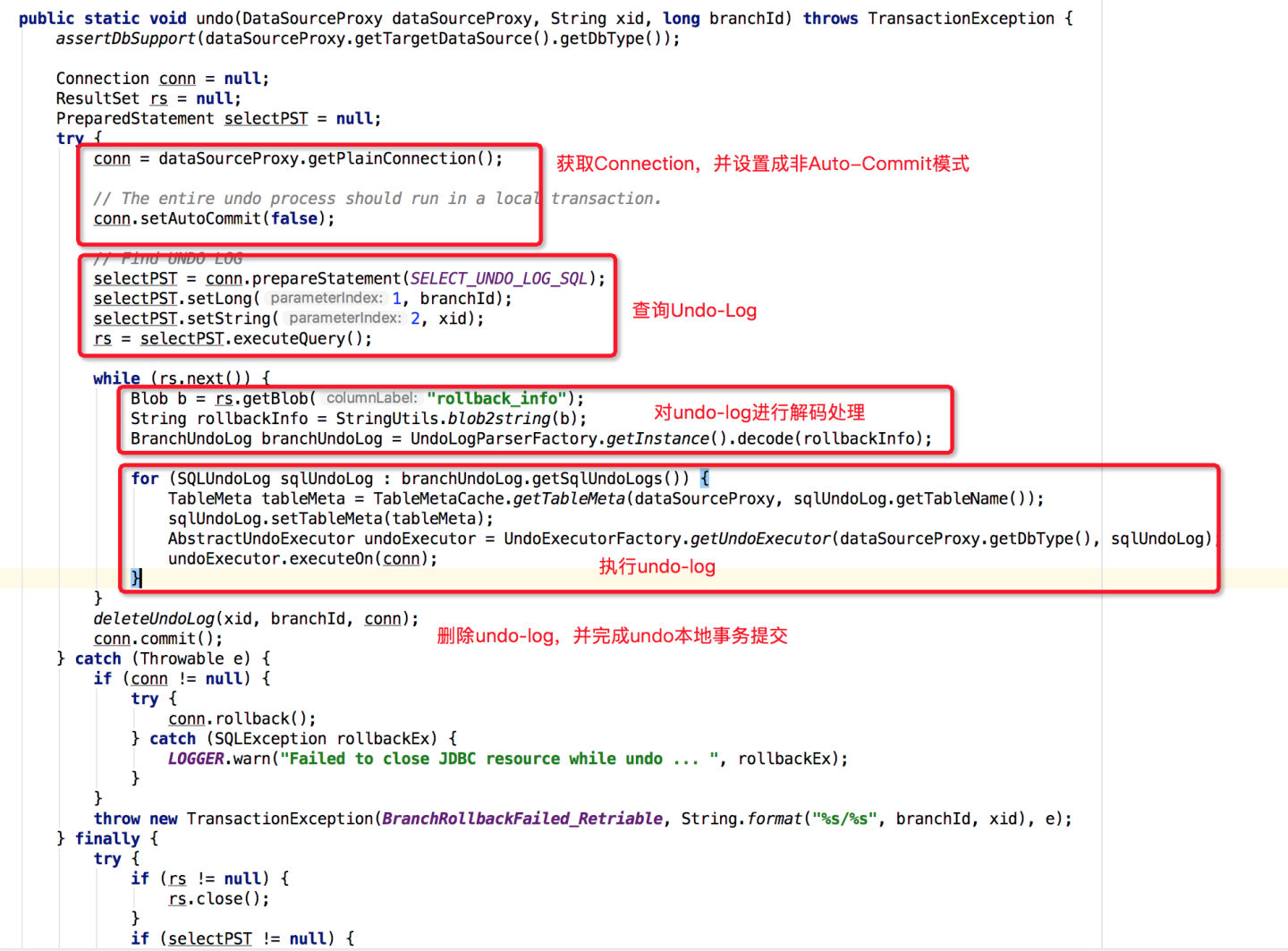
从上图可以看出,整个回滚到全局事务之前状态的代码逻辑集中在如下代码中:
AbstractUndoExecutor undoExecutor = UndoExecutorFactory.getUndoExecutor(dataSourceProxy.getDbType(), sqlUndoLog);
undoExecutor.executeOn(conn);首先通过UndoExecutorFactory获取到对应的UndoExecutor,然后再执行UndoExecutor的executeOn方法完成回滚操作。目前三种类型的UndoExecutor结构如下:

undoExecutor.executeOn源码如下:
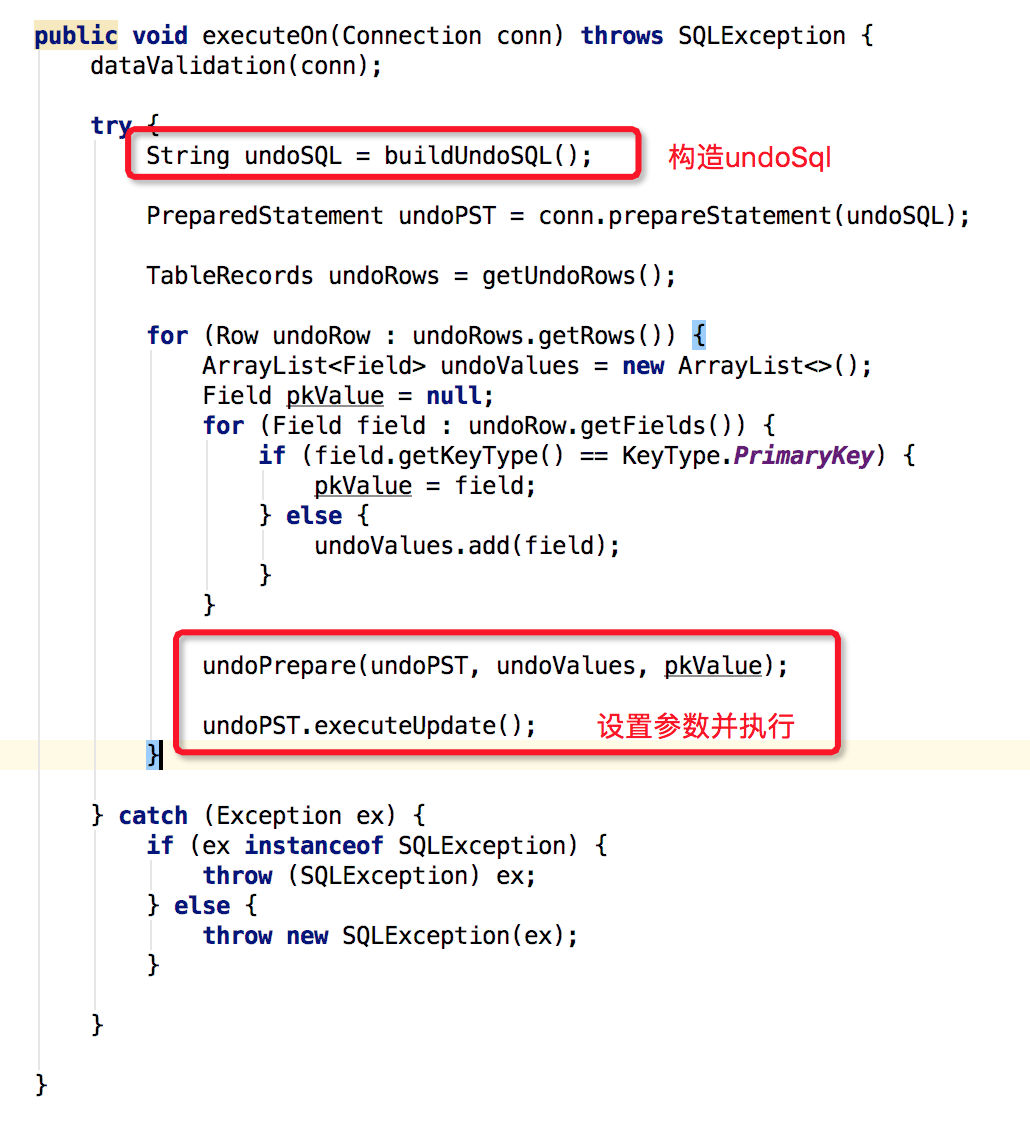
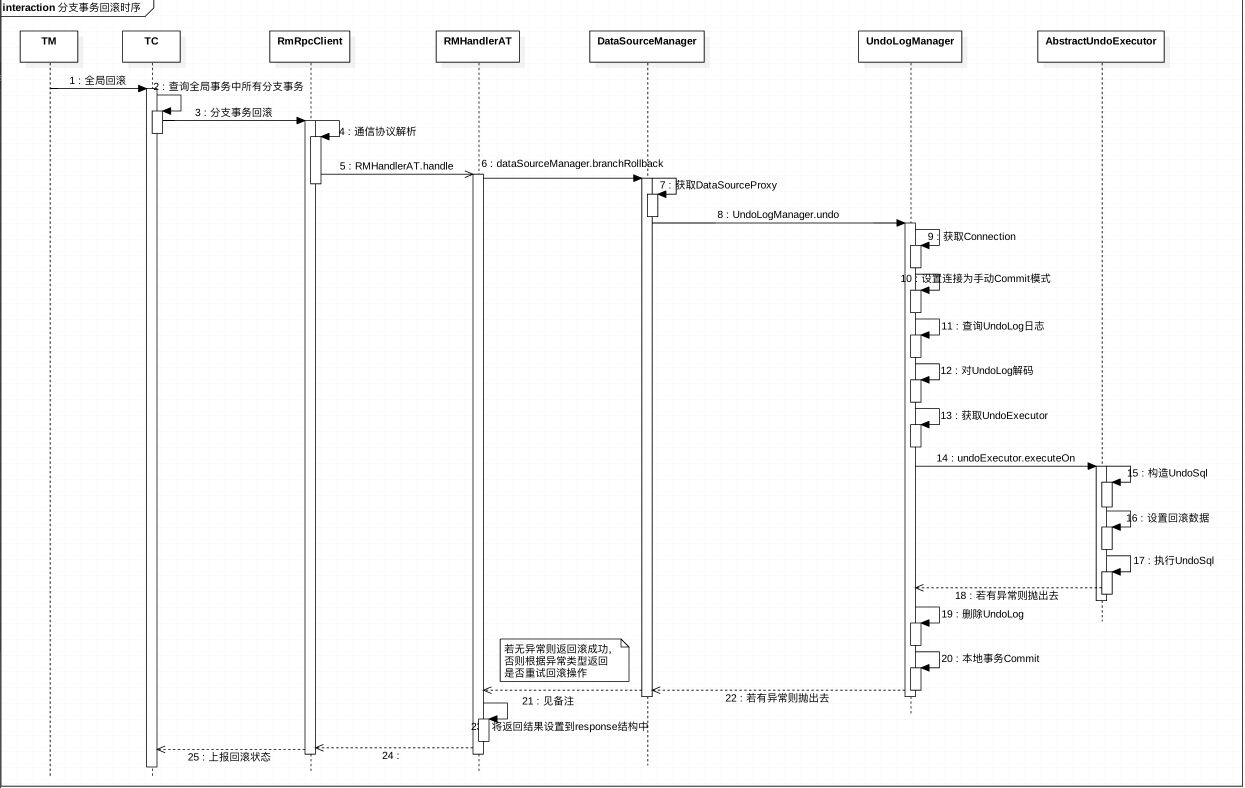
至此,整个分支事务回滚就结束了,分支事务回滚整体时序图如下:
引入Fescar官方对分支事务回滚原理介绍图作为结尾:
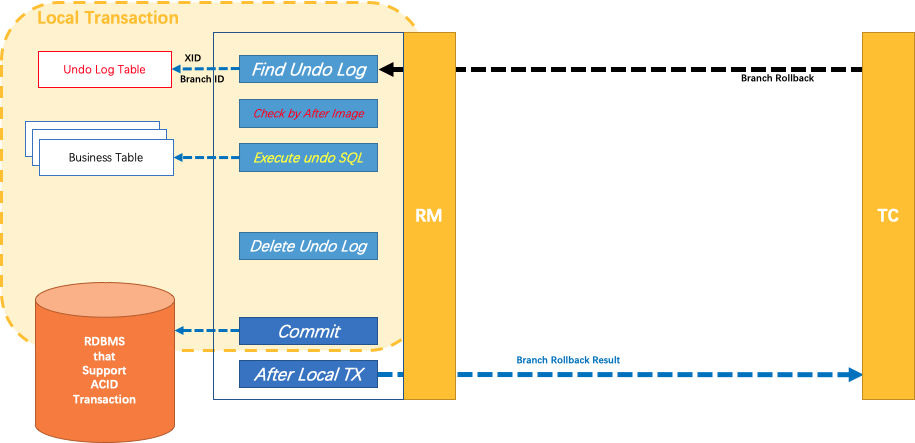
综合上述,Fescar在Phase2通过UndoLog自动完成分支事务提交与回滚,在这个过程中不需要业务方做任何处理,业务方无感知,因些在该阶段对业务代码也是无侵入的。
四、总结
本文主要介绍了RM模块的相关代码,将RM模块按2PC模式分成Phase1和Phase2分别进行介绍,从Fescar源码上看,整个源码结构清晰,有利于研发人员快速学习Fescar的原理。在使用方面,只需进行简单的配置,就可以享受Fescar带来的便捷功能,对业务做到了无侵入;同时在性能方面,Fescar在分支事务提交过程中采用异步模式,减少了全局锁的占用时间,进而提升了整体性能。后续,将继续学习Fescar的其它模块(TM、TC)与全局锁的实现逻辑,并做相关总结介绍。














 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









