







一、爬虫介绍
爬虫:Spider 网络蜘蛛 爬虫也叫网页蜘蛛,网络机器人,就是模拟客户端发送网络请求,获取请求对应的响应,一种按照一定规则,自动抓取互联网信息的程序。
本质原理
现在所有的软件原理大部分都是基于http请求发送和获取数据的,模拟发送http请求从别人的服务端获取数据。绕过反扒不同程序反扒措施不一样比较复杂。
爬虫是否合法?
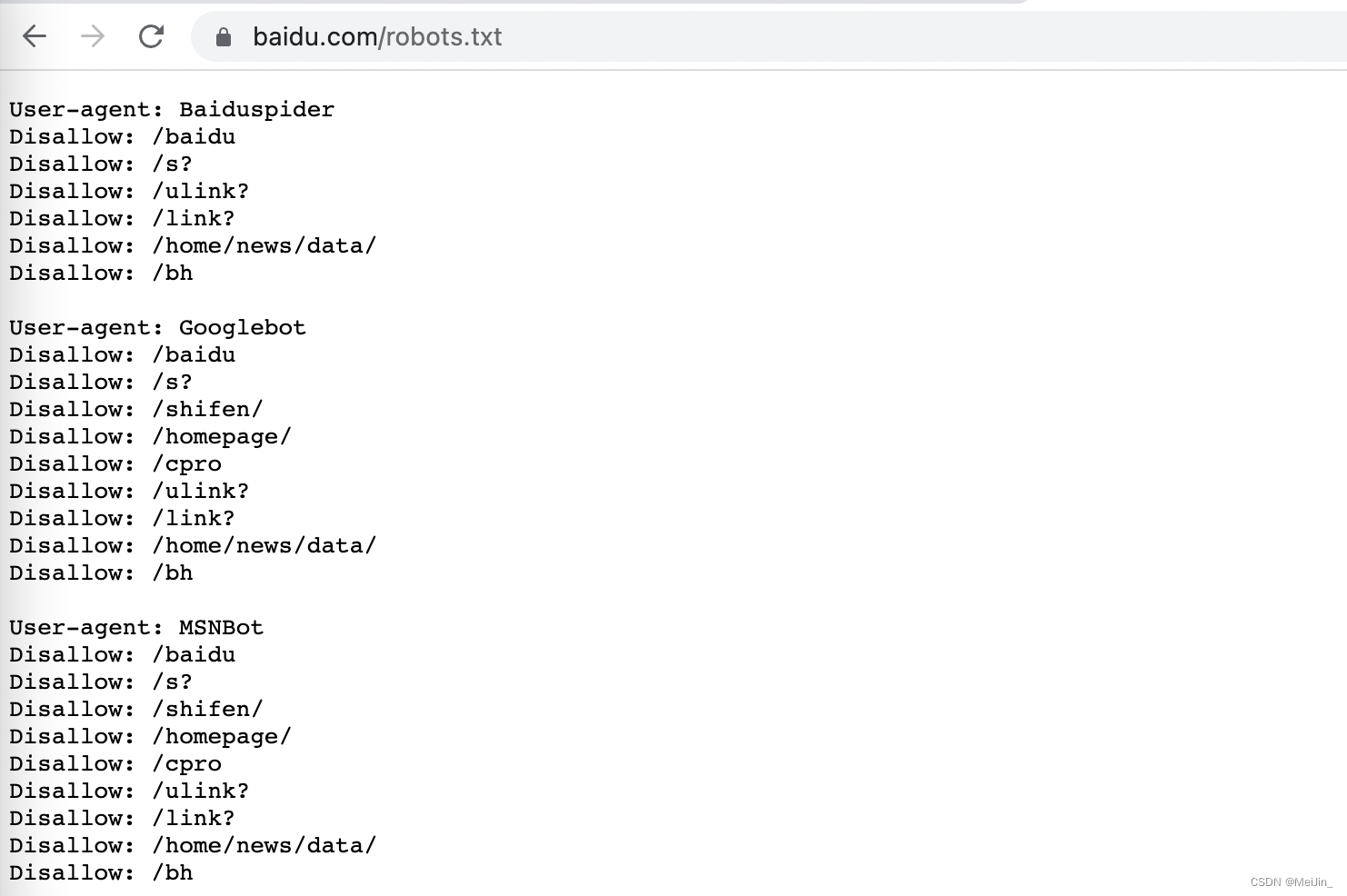
爬虫协议:每个网站根路径下都有robots.txt,这个文件规定了 该网站 哪些可以爬取 哪些不能爬
二、Requests模块发送Get请求
模拟发送http请求的模块:requests 不仅仅做爬虫用它,调用第三方接口,也是要用它
安装Requests
pip install requests
模拟使用:
import requests
res = requests.get('https://blog.csdn.net/MeiJin_')
print(res.text) # http响应体文本内容 从此解析到想要的数据 入库!
延时知识点:短链接
可以延伸短链接 底层原理一个很长的链接发送请求 数据保存到本地 生成链接
三、Get请求携带参数
方式一
直接在请求地址中添加 www.baidu.com?info='Like'
res = requests.get('https://www.baidu.com/?info=%27%E6%83%B3%E8%A6%81%E7%9A%84%E4%BF%A1%E6%81%AF%27')
print(res.text)
方式二
使用params参数携带
res = requests.get('https://www.baidu.com/s', params={
'info1': 'Like',
'info2': 'Boys',
}) # 实际请求地址是 https://www.baidu.com/s?info1=Like&info2Boys
print(res.text)
URL编码与解码
从地址栏里拿出数据 都会被Url进行编码和解码
from urllib import parse # 内置模块
info1 = parse.quote('Mr.梅') # 编码
info2 = parse.unquote('Mr.%E6%A2%85') # 解码
print(info1) # Mr.%E6%A2%85
print(info2) # Mr.梅

四、携带请求头
朝地址发送请求 会在请求头中看到我们的信息 型号不一样 这个内容是不一样的
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
User-Agent:客户端类型:有浏览器、手机端浏览器、爬虫类型,程序,scrapy一般伪造成浏览器
模拟使用
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
res=requests.get('https://dig.chouti.com/',headers=header)
print(res.text)
我们爬去某个网站 发送请求不能正常返回说明模拟的不够 只要数据对应的上就能返回对应的数据
一般网站可以通过Referer来做反扒如果要登录,模拟向登录接口发请求,正常操作必须在登录页面上才能干这事
如果没有携带referer,它就认为你是恶意的就会拒绝。
五、携带Cookie
方式一
模拟抽屉网点赞信息
data = {'linkId': '37001777'} # 发送请求我们可以获得到账号ID
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)AppleWebKit/537.36(KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Cookie': 'deviceId=web.eyJ0eXAiOiJKV1Qixxxxxxxxxxxxxxxxxxxxxxxxxxx.........
}
res = requests.post('https://dig.chouti.com/link/vote', data=data, headers=header)
print(res.text)
方式二
通过cookie参数:因为cookie很特殊,一般都需要携带,模块把cookie单独抽取成一个参数,是字典类型,以后可以通过参数传入
data = {'linkId': '37001777'} # 发送请求我们可以获得到账号ID
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)AppleWebKit/537.36(KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',}
res = requests.post('https://dig.chouti.com/link/vote', data=data, headers=header, cookies={'key': 'value'})
print(res.text) # cookies格式都是字典格式 按照输入即可
六、发送Post请求
方式一
先发送错误登录请求 看返回数据是否对错 输入对的密码 获取cookie 通过Cookie登录
data = {
'username': 'xxxxx',
'password': 'xxxxx', # 错误的 请求码是 error 5 正确的是0
'captcha': 'cccc',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
res = requests.post('http://www.aa7a.cn/user.php', data=data)
print(res.text) # {"error":0,"ref":"http://www.aa7a.cn/"}
print(res.cookies) # RequestCookieJar对象响应头中得cookie,如果正常登录,这个cookie 就是登录后的cookie
res2 = requests.get('http://www.aa7a.cn/', cookies=res.cookies) # 访问首页,携带cookie,
# res2 = requests.get('http://www.aa7a.cn/')
print('xxxxUsername' in res2.text)
方式二
data = {
'username': 'xxxxx',
'password': 'xxxxx', # 错误的 请求码是 error 5 正确的是0
'captcha': 'cccc',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
res = requests.post('http://www.aa7a.cn/user.php', json= {"key": "Value"})
request.session的使用:当request使用,但是它能自动维护cookie
session = requests.session()
data = {
'username': 'xxxxx',
'password': 'xxxxx', # 错误的 请求码是 error 5 正确的是0
'captcha': 'cccc',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
res = session.post('http://www.aa7a.cn/user.php', data=data)
res1 = session.get('http://www.aa7a.cn')
print('xxxxUsername' in res1.text)
七、响应Response
import requests # Response对象有很多属性和方法
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)AppleWebKit/537.36(KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',}
respone = requests.get('https://www.jianshu.com', params={'name': 'Like', 'age': 20}, headers=header)
# respone属性
print(respone.text) # 响应体的文本内容
print(respone.content) # 响应体的二进制内容
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # 响应cookie
print(respone.cookies.get_dict()) # cookieJar对象,获得到真正的字段
print(respone.cookies.items()) # 获得cookie的所有key和value值
print(respone.url) # 请求地址
print(respone.history) # 访问这个地址,可能会重定向,放了它冲定向的地址
print(respone.encoding) # 页面编码
八、获取二进制数据
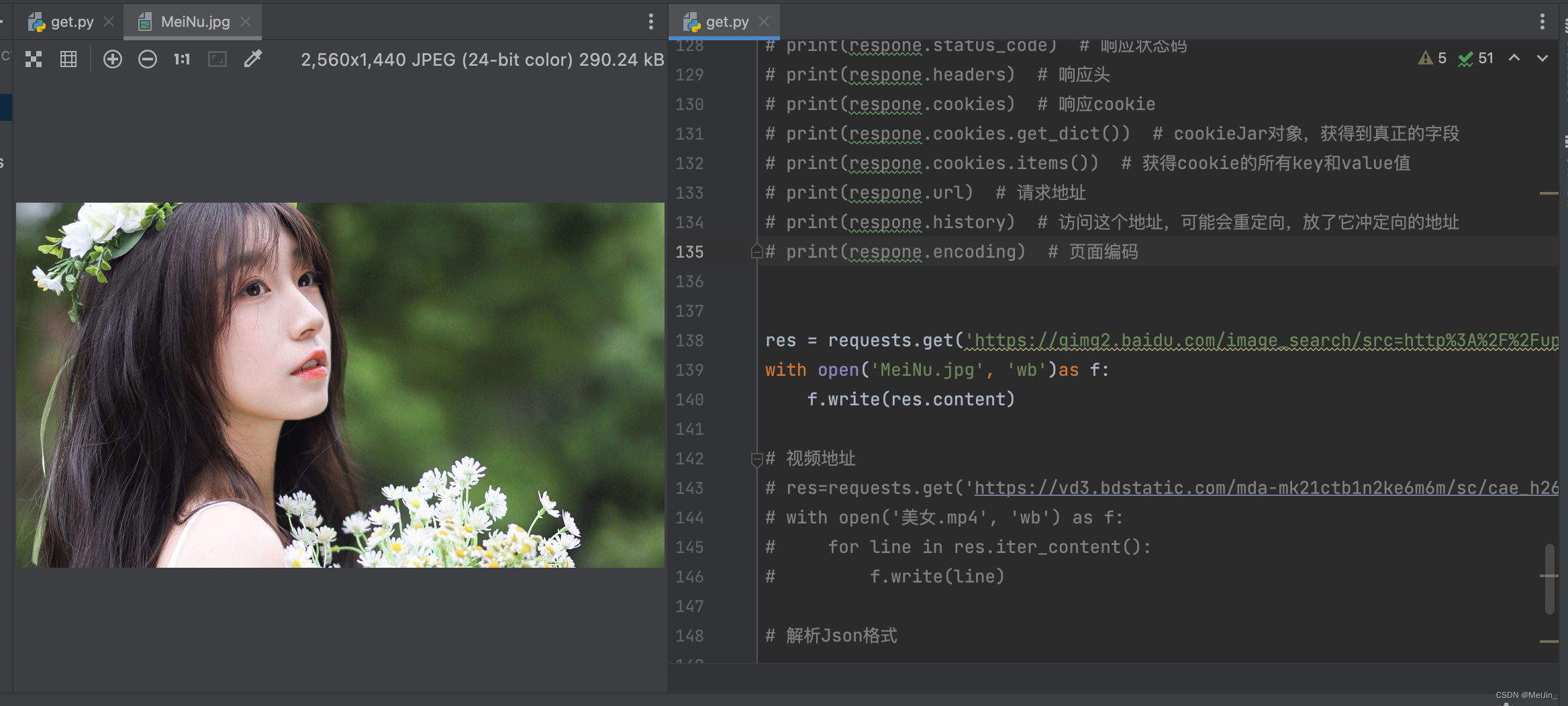
获取二进制数据 图片
res = requests.get('https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fup.enterdesk.com%2Fedpic_source%2F81%2F71%2F2b%2F81712bdce2d6966b9942f249031aba8e.jpg&refer=http%3A%2F%2Fup.enterdesk.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1671809061&t=bc2a02c107ba2835560c30bb4811c822')
with open('MeiNu.jpg', 'wb')as f:
f.write(res.content)
获取二进制视频
res=requests.get('https://vd3.bdstatic.com/mda-mk21ctb1n2ke6m6m/sc/cae_h264/1635901956459502309/mda-mk21ctb1n2ke6m6m.mp4')
with open('美女.mp4', 'wb') as f:
for line in res.iter_content():
f.write(line)
九、解析Json数据
res = requests.get(
'https://api.map.baidu.com/place/v2/search?ak=6E823f587c95f0148c19993539b99295®ion=%E4%B8%8A%E6%B5%B7&query='
'%E8%82%AF%E5%BE%B7%E5%9F%BA&output=json')
print(res.text)
print(type(res.text))
print(res.json()['results'][0]['name'])
print(type(res.json()))
技术小白记录学习过程,有错误或不解的地方请指出,如果这篇文章对你有所帮助请
点点赞收藏+关注谢谢支持 !!!















 729
729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











